
数据结构和算法 十、链表的类型
一、为什么要使用链表?
链表是一种克服数组限制的数据结构。我们先来看看数组的一些限制
- 在程序中使用数组之前,必须提前知道数组的大小。
- 增加数组的大小是一个耗时的过程。在运行时扩展数组的大小几乎是不可能的。
- 数组中的所有元素都需要连续存储在内存中。在数组中插入一个元素需要转移它的所有前辈。
链表很有用,因为
- 它动态分配内存。链表的所有节点都非连续地存储在内存中,并在指针的帮助下链接在一起。
- 在链表中,大小不再是问题,因为我们不需要在声明时定义它的大小。列表根据程序的需求增长并限制在可用内存空间内。
二、链表的类型
1、单链表(java实现)

class LinkedList {
Node head; // head of the list
/* Linked list Node*/
class Node {
int data;
Node next;
// Constructor to create a new node
// Next is by default initialized
// as null
Node(int d) { data = d; }
}
}
// A simple Java program to introduce a linked list
class LinkedList {
Node head; // head of list
/* Linked list Node. This inner class is made static so that
main() can access it */
static class Node {
int data;
Node next;
Node(int d)
{
data = d;
next = null;
} // Constructor
}
/* method to create a simple linked list with 3 nodes*/
public static void main(String[] args)
{
/* Start with the empty list. */
LinkedList llist = new LinkedList();
llist.head = new Node(1);
Node second = new Node(2);
Node third = new Node(3);
/* Three nodes have been allocated dynamically.
We have references to these three blocks as head,
second and third
llist.head second third
| | |
| | |
+----+------+ +----+------+ +----+------+
| 1 | null | | 2 | null | | 3 | null |
+----+------+ +----+------+ +----+------+ */
llist.head.next = second; // Link first node with the second node
/* Now next of the first Node refers to the second. So they
both are linked.
llist.head second third
| | |
| | |
+----+------+ +----+------+ +----+------+
| 1 | o-------->| 2 | null | | 3 | null |
+----+------+ +----+------+ +----+------+ */
second.next = third; // Link second node with the third node
/* Now next of the second Node refers to third. So all three
nodes are linked.
llist.head second third
| | |
| | |
+----+------+ +----+------+ +----+------+
| 1 | o-------->| 2 | o-------->| 3 | null |
+----+------+ +----+------+ +----+------+ */
}
}2、双向链表

如上图所示,双向链表中的节点有两个地址部分;一部分存储下一个节点的地址,而节点的另一部分存储前一个节点的地址。双向链表中的初始节点在地址部分有NULL值,它提供了前一个节点的地址。
struct node
{
int data;
struct node *next;
struct node *prev;
} 在上面的表示中,我们定义了一个名为节点的结构,它有三个成员,一个是整数类型的数据,另外两个是指针,即节点类型的 next 和 prev。 next 指针变量保存下一个节点的地址,prev 指针保存前一个节点的地址。 两个指针的类型,即 next 和 prev 都是结构节点,因为两个指针都存储结构节点类型的节点的地址。
双向链表会为每个节点消耗更多空间,因此会导致更广泛的基本操作,例如插入和删除。但是,我们可以轻松地操作列表的元素,因为列表在两个方向(向前和向后)上都维护着指针。
3、循环单向/双向链表
循环单向链表
在循环单向链表中,链表的最后一个节点包含指向链表第一个节点的指针。我们可以有循环单链表和循环双链表。
我们遍历一个循环单链表,直到我们到达我们开始的同一个节点。循环单点赞列表没有开始也没有结束。任何节点的下一部分都不存在空值。
下图显示了一个循环单链表。
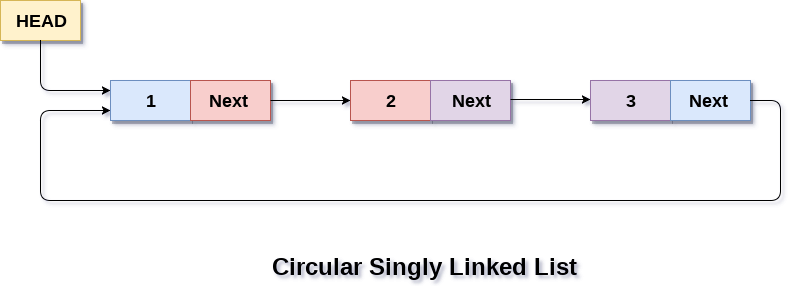
循环双向链表
循环双向链表是一种更复杂的数据结构类型,其中一个节点包含指向其前一个节点和下一个节点的指针。循环双向链表在任何节点中都不包含 NULL。列表的最后一个节点包含列表的第一个节点的地址。列表的第一个节点还包含其前一个指针中最后一个节点的地址。
一个循环双向链表如下图所示。
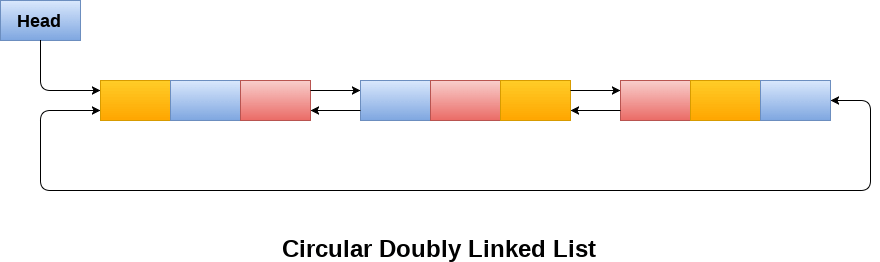
由于循环双向链表在其结构中包含三个部分,因此每个节点需要更多空间和更昂贵的基本操作。但是,循环双向链表提供了对指针的轻松操作,并且搜索效率提高了一倍。
4、跳过列表(Skip list)
跳过列表是一种概率数据结构。跳过列表用于存储带有链表的元素或数据的排序列表。它允许元素或数据的过程有效地查看。在一个步骤中,它会跳过整个列表的几个元素,这就是它被称为跳过列表的原因。
跳过列表是链表的扩展版本。它允许用户非常快速地搜索、删除和插入元素。它由一个包含一组元素的基本列表组成,这些元素维护后续元素的链接层次结构。
(1)跳过列表的结构
跳过列表分为两层:最低层和顶层。
跳过列表的最底层是一个普通的排序链表,跳表的最上层就像一条“快线”,元素被跳过。
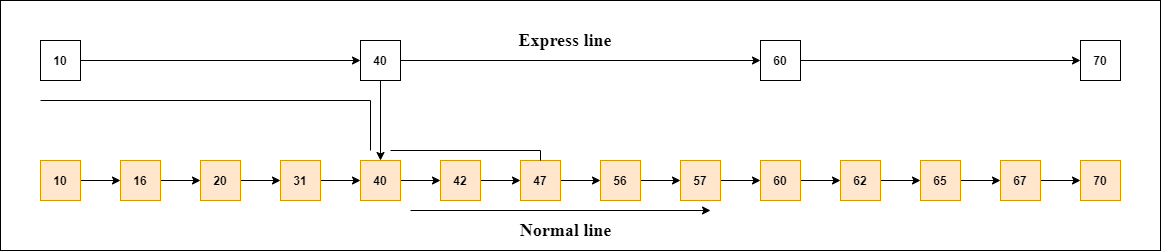
(2)跳过列表的优点
1、如果您想在跳过列表中插入一个新节点,那么它将非常快速地插入该节点,因为跳过列表中没有旋转。
2、与哈希表和二叉搜索树相比,跳过列表易于实现。
3、在列表中查找节点非常简单,因为它以排序形式存储节点。
4、跳过列表算法可以很容易地修改为更具体的结构,例如可索引的跳过列表、树或优先级队列。
5、跳过列表是一个健壮且可靠的列表。
(3)跳过列表的缺点
1、它比平衡树需要更多的内存。
2、不允许反向搜索。
3、跳过列表搜索节点比链表慢得多。
相关文章
- 141. 环形链表
- Data Structures (二) - 链表LinkedList实现(Part A)
- [牛客经典必刷算法题] LC5-链表的插入排序
- 剑指offer No.16 合并两个排序的链表
- 每日算法刷题Day13-在O(1)时间删除链表结点、合并两个排序的链表、把字符串转换成整数
- 148. 排序链表
- 常用链表排序算法_单链表的排序算法
- 【day10】LeetCode(力扣)刷题(注释详细)[707.设计链表][278.第一个错误的版本][98. 验证二叉搜索树]
- c++的链表-C++实现简单链表
- 单向循环链表-链表(单链表)的基本操作及C语言实现
- 双向链表排序,复杂度O(nlogn)
- 数组和链表
- 算法练习之x的平方根,爬楼梯,删除排序链表中的重复元素, 合并两个有序数组详解编程语言
- 算法练习之合并两个有序链表, 删除排序数组中的重复项,移除元素,实现strStr(),搜索插入位置,无重复字符的最长子串详解编程语言
- Oracle数据库中使用的链表结构技术分析(oracle中链表结构图)
- 利用Redis缓存实现高效链表算法(redis缓存链表算法)
- C#数据结构与算法揭秘四双向链表
- java单向链表的实现实例
- c语言链表操作示例分享