正则匹配之道
第⼀步,做分解。
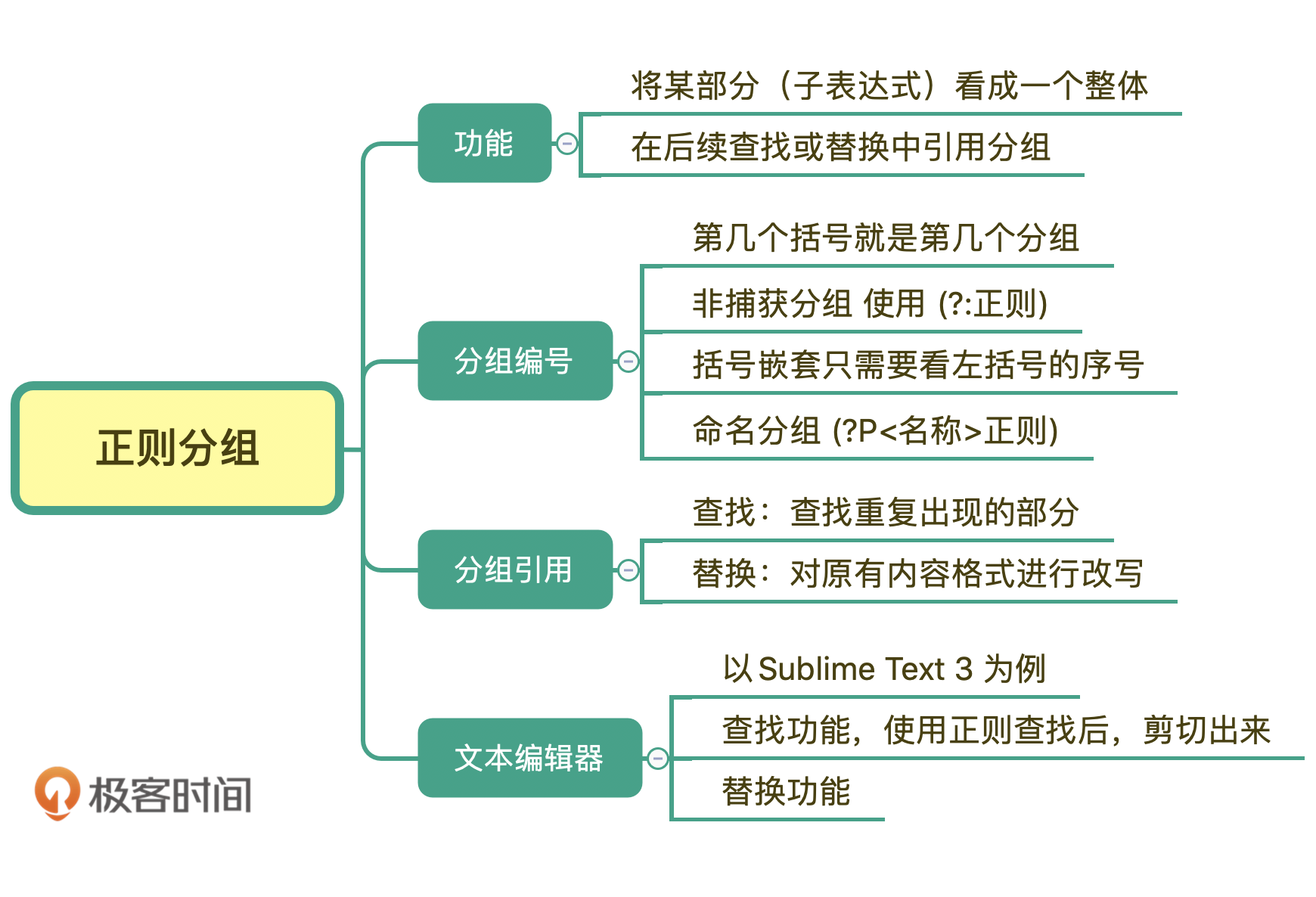
拿到一个问题后,我们要先思考:这个问题可以分为几个子问题?每个子问题是否独立?我们拿最常见的电子邮件地址匹配来说。从文本结构来看,它可以分为“username + @ + domain name”这三个独立的部分。怎么画呢?我们可以先画出逻辑结构图。通过这个过程来厘清思路。当然,这是软件⼯程最基本的思路,相信你做起来应该问题不大。
第⼆步,分析各个子问题。
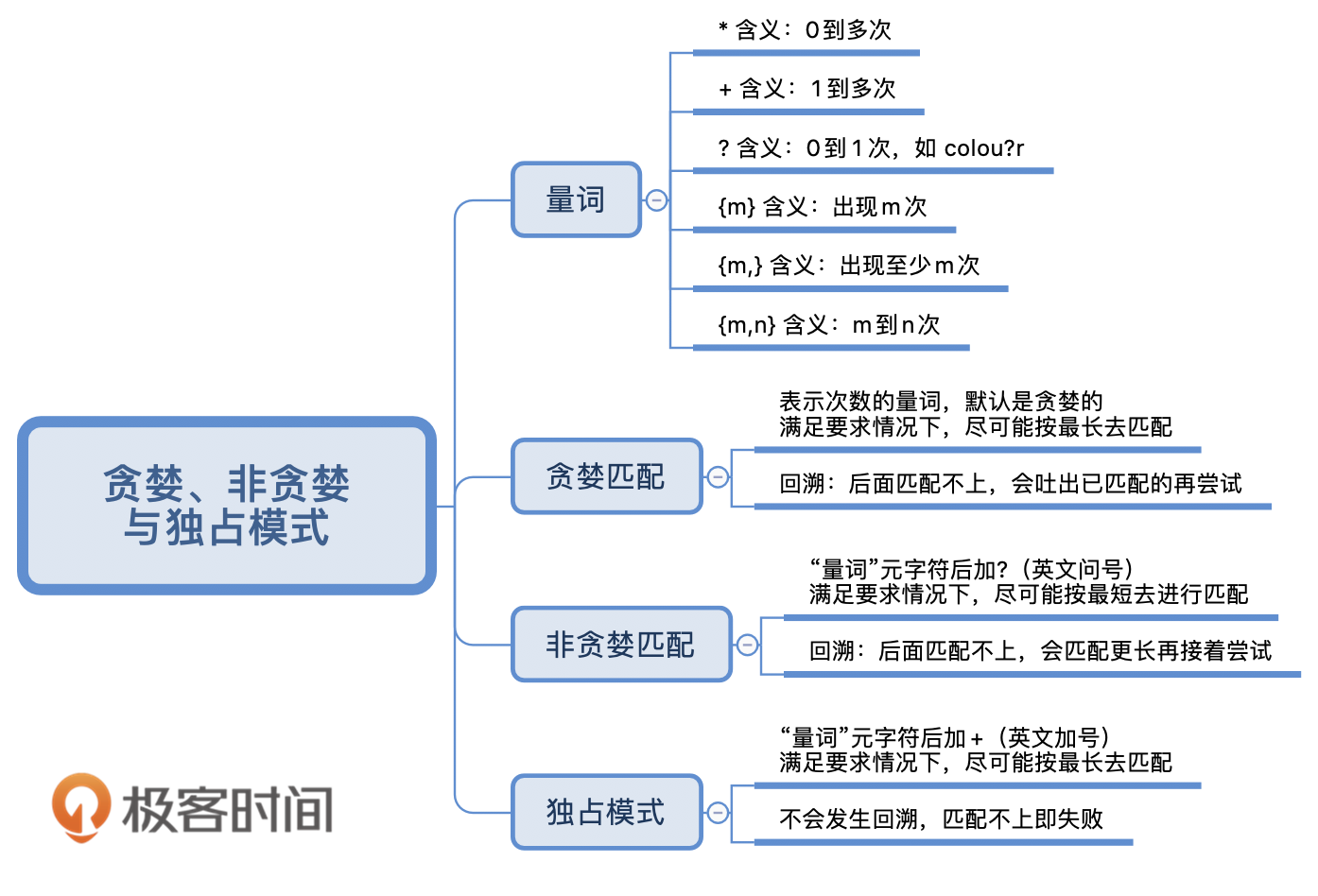
某个位置上可能有多个字符?那就用字符组。某个位置上可能有多个字符串?那就用多选结构。出现的次数不确定?那就用量词。对出现的位置有要求?那就用锚点锁定位置…… 某种程度上,这就像武术里的见招拆招,每个问题都有对应的解法,只要熟练掌握了,知道什么时候用字符组,什么时候用多选结构,什么时候用量词,什么时候用锚点,就很容易搭建起完整的概念模型。
第三步,套皮。
你大概注意到了,到现在,我们还没有谈论正则表达式的典型标志,比如方括号、星号、花括号。要知道,这些典型标志无非只是一些符号而已,真正重要的是字符组、多选结构、量词等等这些概念。一旦你的概念模型清楚了,写出正则表达式就非常简单了,无非是查阅语法手册,把之前得到的概念模型按照对应语言或工具的约定写下来而已。
第四步,调试。很多人都说,正则表达式的麻烦之处在于它像个黑箱子,很难调试,迄今为止仍然没有特别好用的⼯具,所以我们没法⼀步步跟进去看匹配的具体过程,只能笼统地知道“匹配了”或者“没匹配”。那到底怎么调试呢?我的经验是,复杂⼀点的正则表达式不能⼀次写对,这是很正常的。与其纠结“这个正则表达式看起来这么复杂,此处到底要用星号 * 还是加号 +,不如先搞清楚,星号( * )或加号( + )限定的到底是正则表达式中的哪一部分,对应要匹配文本中的哪一部分。这两个问题搞清楚了,整个问题就迎刃而解了。
另外,还有⼀点统摄全局的经验想和你说一下, 那就是学会了正则表达式之后,务必要保持克制 。写正则表达式很容易上瘾,毕竟它的功能那么强⼤,处理速度那么快,⼜像天书符咒那样充满了“神秘”色彩。于是,“写⼀条其他⼈看不懂的正则表达式,⼀次性解决所有问题”,就成了某些程序员的执念。但是,从软件工程的角度来看,这种办法绝对是噩梦,不但其他人无法理解,自己过⼀段时间也会挠头。
第⼀,能用普通字符串处理的,坚决⽤普通字符串处理。
字符串处理的速度不见得差,可读性却好上很多。如果要在大段文本中定位所有的 today 或者 tomorrow,用最简单的字符串查找,直接找两遍,明显比 to(day|morrow) 看起来更清楚。
第⼆,能写注释的正则表达式,⼀定要写注释。
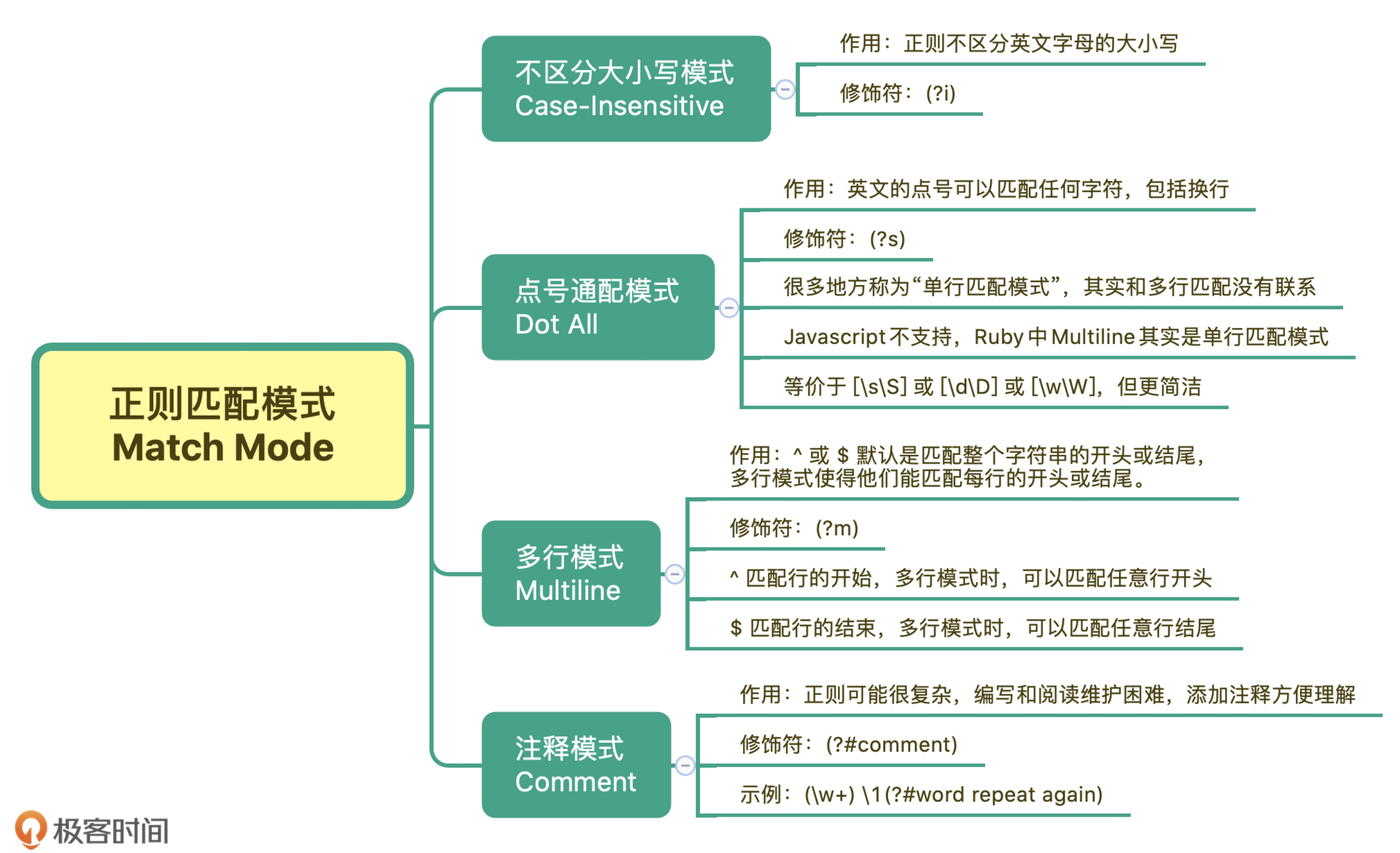
正则表达式的语法非常古老,不够直观,为了便于阅读和维护,如今大部分语言里都可以通过 x 打开注释模式。有了注释,复杂正则表达式的结构也能一目了然。
第三,能用多个简单正则表达式解决的,⼀定不要苛求用一个复杂的正则表达式。
这里最明显的例子就是输入条件的验证。比如说,常见的密码要求“必须包含数字、小写字母、大写字母、特殊符号中的至少两种,且长度在 8 到 16 之间”。你当然可以绞尽脑汁用一个正则表达式来验证,但如果放下执念,⽤多个正则表达式分别验证“包含数字”“包含小写字母”“包含大写字母”“包含特殊符号”这四个条件,要求验证成功结果数大于等于 2,再配合一个正则表达式验证长度,这样做也是可行的。虽然看起来繁琐,但可维护性绝对远远强于单个正则表达式。