
Kafka 概述
Kafka 概述
2023-09-14 09:14:49 时间
Kafka 属于分布式的消息引擎系统,主要功能 :提供一套完备的消息发布与订阅解决方案
生产者和消费者都是客户端(Clients):
- 生产者(Producer):向主题发布消息的客户端应用程序
- 消费者(Consumer):订阅这些主题消息的客户端应用程序
Kafka 服务端 :
- 由多个 Broker 进程构成
- Broker 负责接收/处理客户端发送过来的请求,和消息进行持久化
Broker
备份机制(Replication):实现高可用
- 备份思想:把相同的数据拷贝到多台机器上,形成副本(Replica)
Kafka 有两类副本:
- 领导者副本(Leader Replica):对外提供服务,与客户端程序进行交互
- 追随者副本(Follower Replica):只追随领导者副本,不与外界进行交互
副本机制:
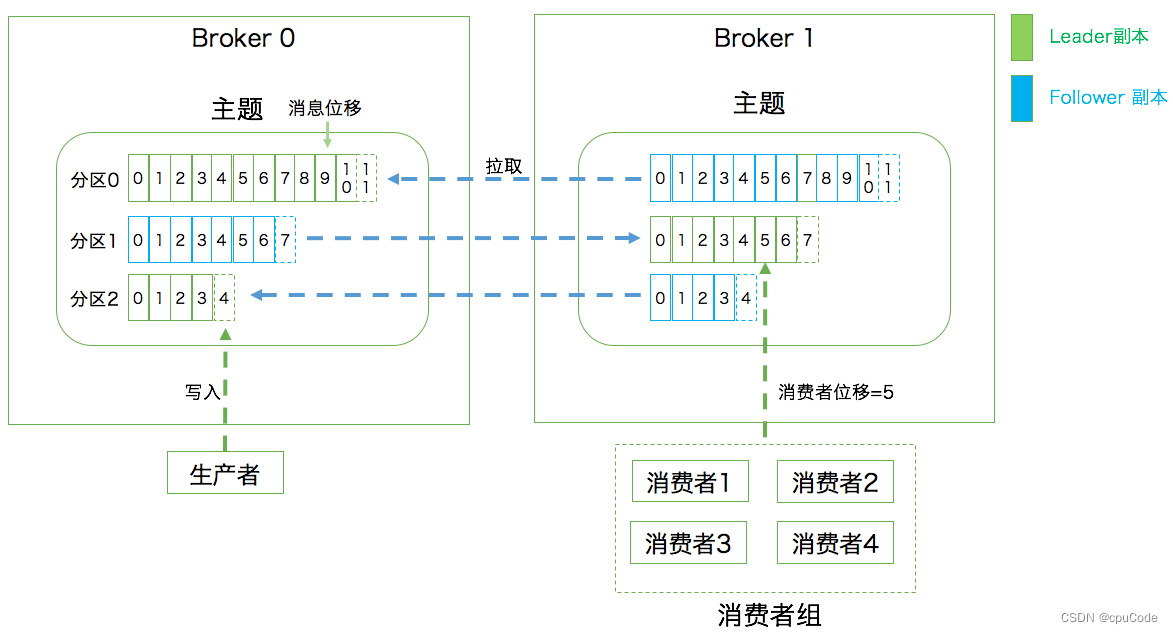
- 生产者向领导者副本写消息
- 消费者从领导者副本读消息
- 追随者副本:只向领导者副本发送请求,与领导者的同步
伸缩性(Scalability) :
- 利用分区机制把数据切分到不同的 Broker 上
- 分区机制:将每个主题划分成多个分区(Partition)
- 每个分区是一组有序的消息日志
- 生产者的每条消息只会发送到一个分区中
- 分区编号是从 0 开始的,如 : Topic 有 20 个分区,分区号是从 0 到 19
副本/分区关系 :
- 每个分区下能配置 n 个副本(1 个领导者副本/ N-1个追随者副本)
- 生产者向分区写入消息,每条消息在分区位置由位移(Offset)表示
- 分区位移从 0 开始,如 : 生产者向空分区写入10 条消息,该消息的位移是 0 - 9
Kafka 三层消息架构:
- 一层 :主题层,每个主题能配 M 个分区,每个分区能配 N 个副本
- 二层:分区层,每个分区的 N 个副本中只有一个领导者角色,对外提供服务;其他 N-1 个副本只先领导副本拉取数据,实现数据冗余
- 三层:消息层,每个分区有 T 条消息,每条消息的位移从 0 开始,依次递增
- 客户端只与分区的领导者副本进行交互
Kafka Broker 持久化数据 :
- 用消息日志 (Log) 来保存数据
- 一个日志是一个只能追加写 (Append-only) 消息的物理文件
- 实现高吞吐量 :追加写入,能避免随机 I/O 操作,改为顺序 I/O 写操作
Kafka 定期删除消息 :
- 利用日志段(Log Segment)机制定期删除消息来回收磁盘
- 一个日志分成多个日志段,消息只写到最新的日志段中,当写满后,就自动分出新的日志段,并把老日志段保存
- 后台定时任务检查老日志段是否能够被删除,来实现回收磁盘
消费者
两种消息模型 :
- 点对点模型(Peer to Peer,P2P) : 同条消息只能被一个消费者消费
- 发布订阅模型
Kafka 实现 P2P 模型 : 引入了消费者组(Consumer Group)
- 消费者组 : 多个消费者实例为一个组来消费一组主题
- 该组主题的每个分区只能被组内的一个消费者实例消费
- 多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)
- 消费者实例能是一个进程或一个线程,都是一个消费者实例(Consumer Instance)
重平衡 (Rebalance) :
- 消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程
- 实现消费者高可用
消费者位移 (Consumer Offset) :
- 表示消费者消费进度,每个消费者都有自己的消费者位移
相关文章
- Kafka学习之一深度解析
- Kafka+Storm+HDFS整合实践
- 自己玩KAFKA 版本 kafka_2.13-3.2.1
- kafka 第一次小整理(草稿篇)————演变[二]
- Flink(16):Flink之Connect Kafka API
- kafka可视化客户端工具(Kafka Tool)的基本使用
- kafka-eagle报错解决:Kafka version is “-“ or JMX Port is “-1“ maybe kafka broker jmxport disable.
- OUT了吧,Kafka能实现消息延时了
- kafka在zookeeper上的节点信息和查看方式
- kafka.common.KafkaException: Failed to acquire lock on file .lock in /tmp/kafka-logs. A Kafka instance in another process or thread is using this directory.
- Kafka消费者没有收到通知的分析
- pyspark kafka createDirectStream和createStream 区别
- kafka的topic和分区策略——log entry和消息id索引文件
- Flume+Kafka+Spark Streaming+MySQL实时日志分析
- 大数据Hadoop之——Kafka鉴权认证(Kafka kerberos认证+kafka账号密码认证+CDH Kerberos认证)
- Kafka 重平衡
- Kafka概述与工作原理