
推荐系统(4):推荐系统分类
目录
0. 相关文章链接
1. 根据实时性分类
1.1. 离线推荐
离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率。
1.2. 实时推荐
关于到底什么是实时推荐,一共分为3层:
- 第一层,“给得及时”,也就是服务的实时响应。这个是最基本的要求,一旦一个推荐系统上线后,在互联网的场景下,没有让用户等个一天一夜的情况,基本上最慢的服务接口整个下来响应时间也超过秒级。达到第一层不能成为实时推荐,但是没达到就是不合格。
- 第二层,“用得及时”,就是特征的实时更新。例如用户刚刚购买了一个新的商品,这个行为事件,立即更新到用户历史行为中,参与到下一次协同过滤推荐结果的召回中。做到这个层次,已经有实时推荐的意思了,常见的效果就是在经过几轮交互之后,用户的首页推荐会有所变化。这一层次的操作影响范围只是当前用户。
- 第三层,“改得及时”,就是模型的实时更新。还是刚才这个例子,用户刚刚购买了一个新的商品,那需要实时地去更新这个商品和所有该用户购买的其他商品之间的相似度,因为这些商品对应的共同购买用户数增加了,商品相似度就是一种推荐模型,所以它的改变影响的是全局推荐。
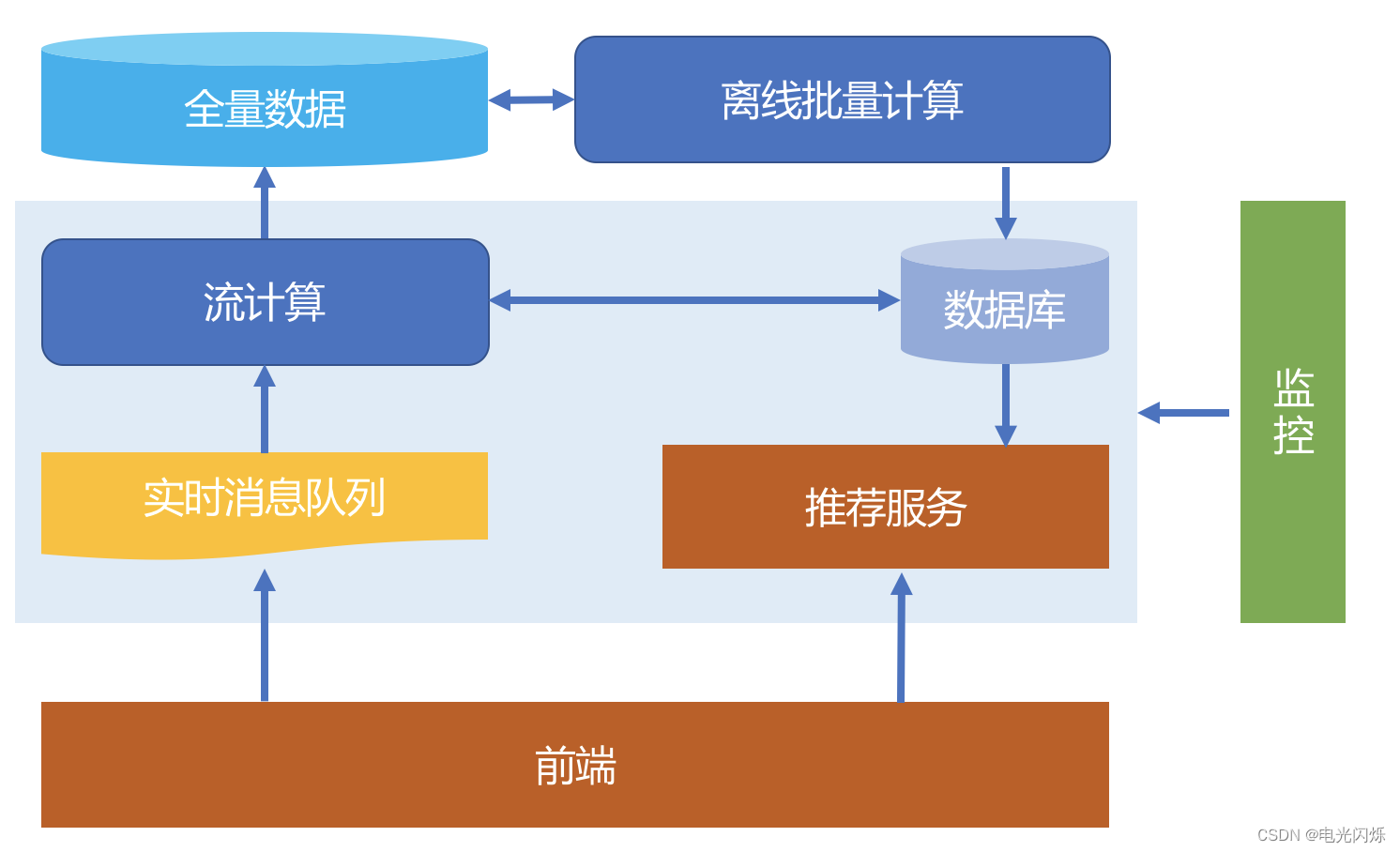
实时推荐架构橄榄如下所示:
按照前面的分析,一个处在第三层次的实时推荐,需要满足三个条件:
- 数据实时进来
- 数据实时计算
- 结果实时更新
为此,下面给出一个基本的实时推荐框图:
整体介绍一下这个图,前端服务负责和用户之间直接交互,不论是采集用户行为数据,还是给出推荐服务返回结果。
用户行为数据经过实时的消息队列发布,然后由一个流计算平台消费这些实时数据,一方面清洗后直接入库,另一方面就是参与到实时推荐中,并将实时计算的结果更新到推荐数据库,供推荐服务实时使用。
2. 根据推荐是否个性化分类
- 基于统计的推荐
- 个性化推荐
3. 根据推荐原则分类
- 基于相似度的推荐
- 基于知识的推荐
- 基于模型的推荐
4. 根据数据源分类
4.1. 基于人口统计学的推荐
基于人口统计学的推荐机制(Demographic-based Recommendation)是一种最易于实现的推荐方法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
具体介绍和使用可以查看博主的 推荐系统(5):推荐算法之基于人口学的统计推荐算法 博文。
4.2. 基于内容的推荐
Content-based Recommendations (CB)根据用户过去喜欢的产品,为用户推荐和他过去喜欢的产品相似的产品。该相似度不是通过ItemCF进行实现,而是通过抽取物品内在或者外在的特征值,实现相似度计算。
具体介绍和使用可以查看博主的 推荐系统(6):推荐算法之基于内容的推荐算法 博文。
4.3. 基于协同过滤的推荐
基于协同过滤的推荐就是基于用户的协同过滤推荐算法以及基于物品的协同过滤推荐算法,而使用的推荐。
具体介绍和使用可以查看博主的 推荐系统(7):推荐算法之基于协同过滤推荐算法 博文。
注:其他推荐系统相关文章链接由此进 -> 推荐系统文章汇总
相关文章
- 深入理解推荐系统:微软xDeepFM原理与实践
- AAAI'22「腾讯」多任务推荐系统中的跨任务知识蒸馏
- NIPS'21「微信」推荐系统:结合课程学习的多反馈表征解耦
- 阐述区块链NFT铸造分红DAPP项目系统开发分析(成熟案例)
- WWW2021 | 基于图卷积神经网络的多样化推荐系统
- 构建基于Transformer的推荐系统
- 推荐这款超牛的低码平台,日造系统不是梦!
- 推荐系统之用户多兴趣建模(一)
- 推荐系统遇上深度学习(十二)--推荐系统中的EE问题及基本Bandit算法
- 协同过滤在推荐系统中的应用详解大数据
- 深入Linux系统网络配置实战(查看linux网络配置)
- Linux系统CCS之旅(linuxccs)
- 改变Linux系统时间:一步一步(linux改变系统时间)
- 踏上Linux之旅:编译安装系统(编译安装linux系统)
- Linux系统自带的浏览器推荐(linux自带浏览器)
- Linux系统中关闭防火墙的步骤详解(linux关闭防火墙方法)
- 用光盘安装Linux系统的简易步骤(用光盘安装linux)
- 学习Linux?这里有一些精品视频教程推荐!(linux系统视频教程)
- 服务Linux系统快捷关闭HTTPd服务指南(linux关闭httpd)
- Linux系统 轻松装U盘(可以装u盘的linux)
- 开启Linux系统的音乐之旅(linux下的播放器)
- Linux系统推荐:开启新的计算世界(linux系统推荐)
- 如何解决Linux系统中g命令未找到问题(linuxg命令未找到)
- 在Linux系统中使用ffplay的简易介绍(ffplay linux)
- 推动系统营效率 尽情利用Redis(推荐系统 redis)
- 如何用深度学习推荐电影?教你做自己的推荐系统!