
【Pytorch Lighting】第 7 章:半监督学习
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
机器学习长期以来一直用于识别模式。然而,最近机器可以用来创建图案的想法引起了所有人的想象。机器能够通过模仿已知的艺术风格来创造艺术的想法,或者在给定任何输入的情况下,随着输出提供类似人类的视角已经成为机器学习的新前沿。
到目前为止,我们看到的大多数深度学习模型要么是关于识别图像(使用卷积神经网络(CNN) 架构)、生成文本(使用 Transformer)或生成图像(生成对抗网络)。然而,作为人类,我们在现实生活中并不总是将对象纯粹视为文本或图像,而是将它们视为它们的组合。例如,Facebook 帖子或新闻文章中的图像可能会伴随一些描述它的评论。模因是一种通过将吸引人的图像与智能文本相结合来创造幽默的流行方式。音乐视频是图像、视频、音频和文本的组合,所有这些都组合在一起。如果我们希望机器真正变得智能,它们需要足够聪明,能够解释媒体中的内容,并以人类能够理解的方式进行解释。这种多模式学习是机器智能的圣杯。
如前所述,ImageNet 通过实现接近人类的图像识别性能推动了深度学习的革命。它还为想象机器可以实现的新可能性打开了大门。一个这样的前景是要求机器不仅识别图像,而且用外行的术语描述图像内部发生的事情。这促使微软创建了一个名为COCO的新众包项目。具有人工策划的图像标题。这创建了一组模型,我们训练机器如何写作(例如通过向孩子展示苹果的图片来教孩子一种语言,然后在黑板上写下APPLE这个词,并希望孩子会使用这种技能来写新的字)。这也开辟了深度学习的新领域称为半监督学习。这种学习形式依赖于人类提供的输入来开始训练,因此它具有监督组件;但是,初始输入并没有完全用作基本事实或标签。相反,可以在有或没有任何提示的情况下以无人监督的方式生成输出。它位于监督到非监督频谱的中间,因此是称为半监督学习。然而,半监督学习的最大潜力在于可以教机器图像中的上下文概念。例如,汽车的图像意味着不同的事物,这取决于它是在移动、停放还是在陈列室中,让机器理解这些差异可以解释图像内部发生的事情。
在本章中,我们将了解如何使用 PyTorch Lightning 解决半监督学习问题。我们将专注于结合CNN和循环神经网络( RNN ) 架构的解决方案。
我们将在本章中介绍以下主题:
- 半监督学习入门
- 遍历 CNN-RNN 架构
- 为图像生成标题
技术要求
在本章中,我们将主要使用以下列出的 Python 模块及其版本:
- PyTorch Lightning (version 1.5.2)
- NumPy (version 1.19.5)
- torch (version 1.10)
- torchvision (version 0.10.0)
- NLTK (version 3.2.5)
- Matplotlib (version 3.2.2)
为了确保这些模块一起工作并且不会不同步,我们使用了特定版本的torch、 torchvision、 torchtext、 torchaudio和 PyTorch Lightning 1.5.2。您还可以使用相互兼容的最新版 PyTorch Lightning 和手电筒。更多详细信息可以在 GitHub 链接上找到:https ://github.com/PacktPublishing/Deep-Learning-with-PyTorch-Lightning 。
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0 --quiet
!pip install pytorch-lightning==1.5.2 --quiet本章使用以下源数据集:
- Microsoft Common Objects in Context ( COCO ) 数据集,可在 https://cocodataset.org/#download 获得。
半监督学习入门
正如我们在介绍中所看到的,半监督学习最令人惊奇的应用之一是教学的可能性机器如何解释图像。这样做不仅可以为某些给定的图像创建标题,还可以让机器写下它如何感知图像的诗意描述。
查看以下结果。左边是传递给模型的一些随机图像,右边是模型生成的一些诗歌。以下结果很有趣,因为很难确定这些抒情小节是由机器还是人类创建的:
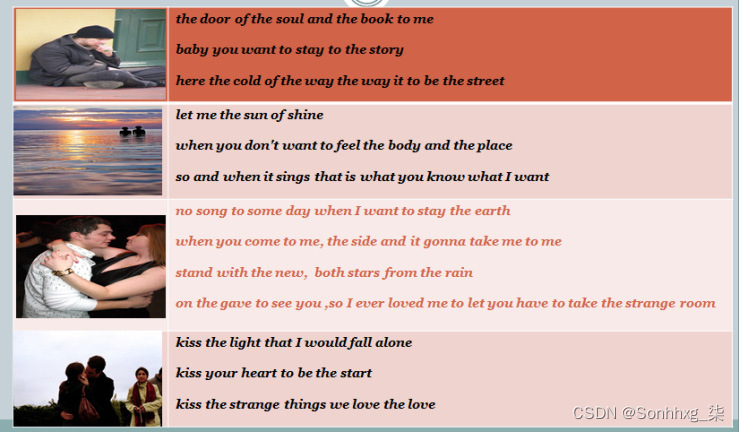
图 7.1 – 通过分析上下文为给定图像生成诗歌
例如,在顶部图像中,机器可以检测到门和街道,并写了一段关于它的内容。在第二张图片中,它检测到阳光并写下关于日落和爱情的抒情诗节。在底部的图像中,机器检测到一对情侣接吻,并写了几行关于吻和爱的文字。
在这个模型中,图像和文本一起训练,因此通过查看图像,机器可以推断出上下文。这在内部使用了各种深度学习方法,例如 CNN 和 RNN长短期记忆(LSTM)。它根据训练数据的风格给出给定对象的透视预测。例如,如果有一个墙的图像,那么我们可以使用它来生成文本,这取决于它可能是由唐纳德特朗普或希拉里克林顿或其他人说的。这一引人入胜的新发展使机器更接近艺术和人类感知。
要了解这是如何实现的,我们需要了解底层的神经网络架构。在第 2 章,第一个深度学习模型起步中,我们看到了 CNN 模型,在第 5 章,时间序列模型中,我们看到了 LSTM 模型的示例。我们将在本章中使用它们。
遍历 CNN-RNN 架构
虽然有半监督学习的许多可能应用和许多可能的神经架构,我们将从最流行的一种开始,它是一种结合了 CNN 和 RNN 的架构。
简单地说,我们将从图像开始,然后使用 CNN 识别图像,然后将 CNN 的输出传递给 RNN,RNN 进而生成文本:
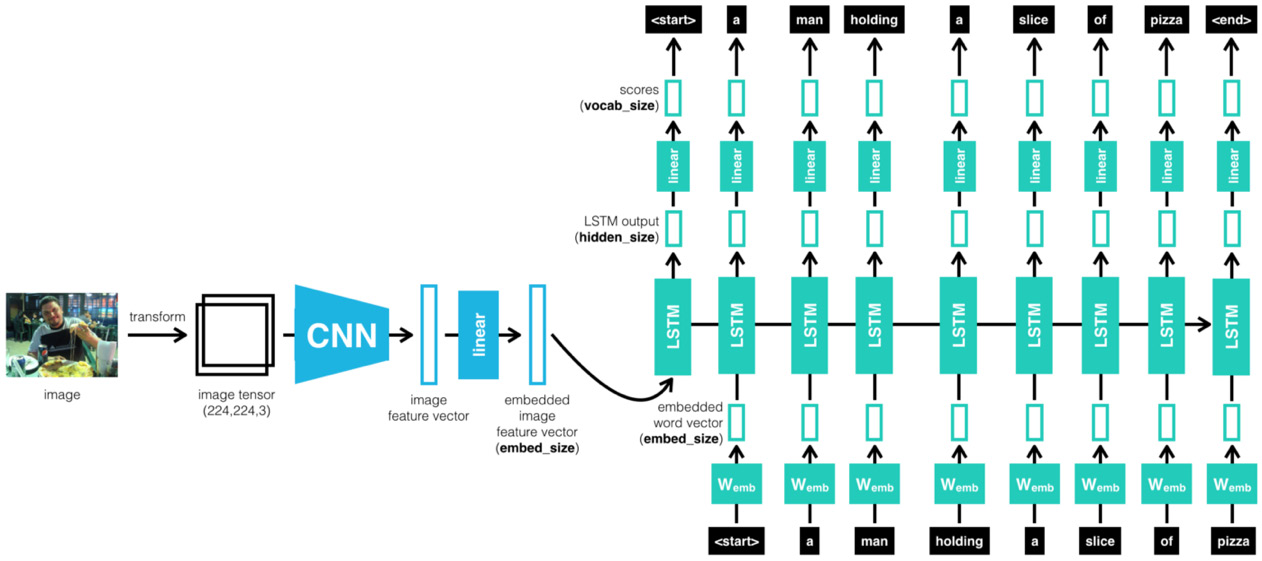
图 7.2 – CNN-RNN 级联架构
直观地说,该模型经过训练以识别图像及其句子描述,从而了解语言和视觉数据之间的联运对应关系。它使用 CNN 和多模式 RNN 来生成图像的描述。如上所述,LSTM 用于 RNN 的实现。
这种架构由 Andrej Karpathy 和他的博士生导师李飞飞在他们 2015 年的斯坦福论文题为Generative Text Using Images and Deep Visual-Semantic Alignments for Generating Image Descriptions中首次提出:
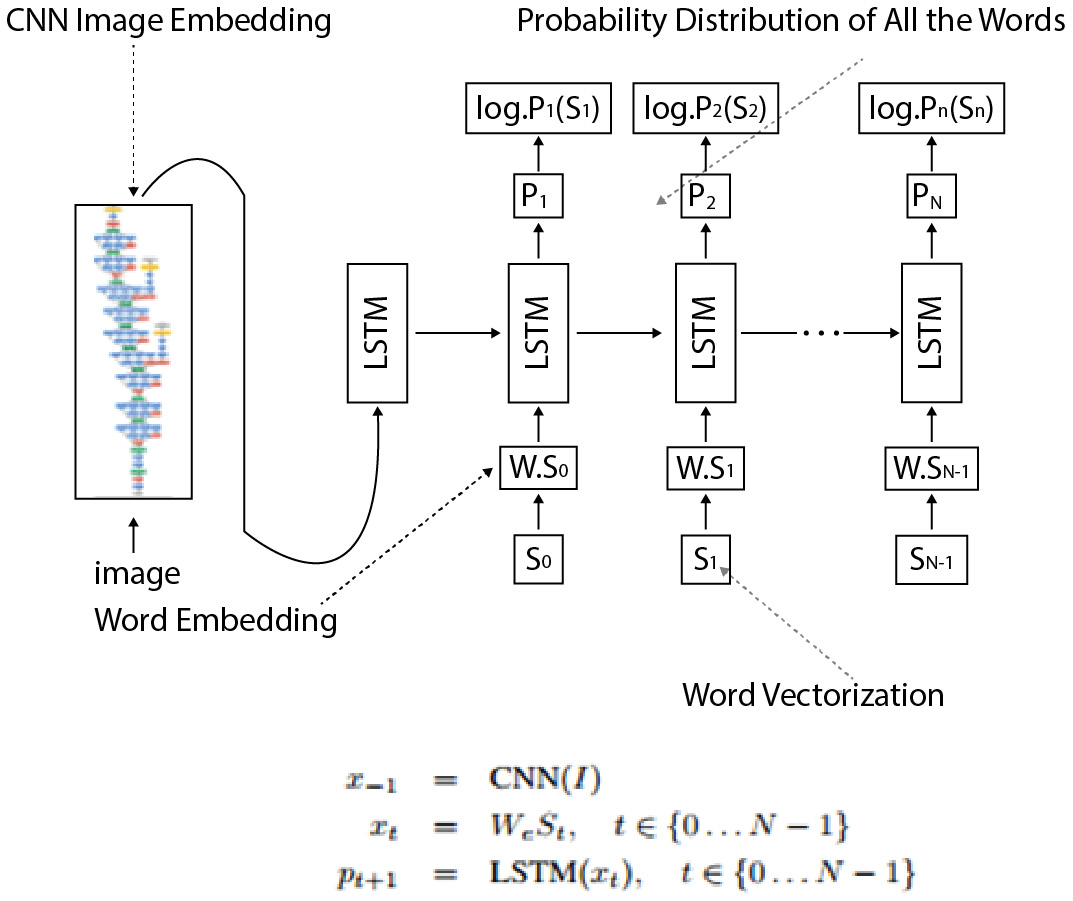
图 7.3 – LSTM 和 CNN 工作细节(图片来源 - Andrej Karpathy)
- 该数据集包含由人们编写的描述图像中发生的事情的句子。核心思想依赖于人们会频繁引用某些对象但它们发生的上下文这一事实。例如,Man is sitting on the bench有多个部分,man是对象,bench是位置,sitting是动作。它们共同定义了整个图像的上下文。
- 我们的目标是生成像人类一样描述图像中正在发生的事情的文本。为此,我们需要将问题转移到潜在空间并创建图像区域和单词的潜在表示。这种多模式嵌入将创建相似上下文的语义图,并可以为看不见的图像生成文本。
- 为了实现它,我们首先使用 CNN 作为编码器,并从 Softmax 之前的最后一层获取一个特征。为了提取图像和单词之间的关系,我们需要用与图像向量嵌入相同的形式来表示单词。因此,然后将图像的张量表示传递给 RNN 模态。
- 该架构使用 LSTM 架构来实现 RNN。特定的双向 RNN 采用一系列单词并将每个单词转换为一个向量。用于文本生成的 LSTM 的工作方式与我们在第 5 章“时间序列模型”中看到的时间序列非常相似,通过预测句子中的下一个单词。它通过在给定先前字母的整个历史的情况下一次预测每个字母来做到这一点,从而选择具有最大概率的字母。
- LSTM激活函数设置到一个Rectified Linear Unit ( ReLU ),RNN 的训练与之前模型中描述的完全一样。最后,优化方法是使用随机梯度下降( SGD ),使用小批量优化模型。
- 最后,在为了为看不见的图像生成描述性文本或标题,该模型首先使用 CNN 图像识别模型来检测对象区域并识别对象。然后这些对象成为我们 LSTM 模型的引物或种子,模型预测句子。句子预测通过拾取字符在分布上的最大概率 (Softmax) 一次发生一个字符。提供的词汇在可以生成什么文本方面起着关键作用。
- 如果您将词汇表从标题更改为诗歌,那么模型将学习生成诗歌。如果你给它莎士比亚,它会产生十四行诗,以及你能想象到的任何东西!
为图像生成标题
- 下载数据集
- 组装数据
- 训练模型
- 生成字幕
下载数据集
在这一步中,我们将下载 COCO 数据集我们将使用它来训练我们的模型。
COCO 数据集
这COCO 数据集是一个大规模的对象检测、分割和字幕数据集(https://cocodataset.org)。它有 150 万个对象实例,80 个对象类别,每张图片有 5 个标题。您可以通过过滤一种或多种对象类型来探索COCO - Common Objects in Context上的数据集,例如以下屏幕截图中显示的狗的图像。每个图像上方都有图块来显示/隐藏 URL、分段和标题:

图 7.4 – COCO 数据集

图 7.5 – 来自 COCO 网站主页的随机数据集示例
提取数据集
在本章中,我们将训练我们的混合 CNN-RNN 模型使用 COCO 2017 训练数据集中的 4,000 张图像以及这些图像的标题。COCO 2017 数据集包含超过 118,000 张图像和超过 590,000 个字幕。使用如此大的数据集训练模型需要很长时间,因此我们过滤掉了 4,000 张图像及其相关的标题,我们将在后面介绍。但首先,以下是将所有图像和标题下载到名为coco_data的文件夹的代码( Downloading_the_dataset.ipynb notebook)中的步骤:
!wget http://images.cocodataset.org/zips/train2017.zip
!wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
!mkdir coco_data
!unzip ./train2017.zip -d ./coco_data/
!rm ./train2017.zip
!unzip ./annotations_trainval2017.zip -d ./coco_data/
!rm ./annotations_trainval2017.zip
!rm ./coco_data/annotations/instances_val2017.json
!rm ./coco_data/annotations/captions_val2017.json
!rm ./coco_data/annotations/person_keypoints_train2017.json
!rm ./coco_data/annotations/person_keypoints_val2017.json在前面的代码中片段,我们使用wget命令从 COCO 网站下载 ZIP 文件。这相当于下载文件,在以下屏幕截图中使用红色箭头标记,取自 COCO 网站的下载页面(COCO - Common Objects in Context):
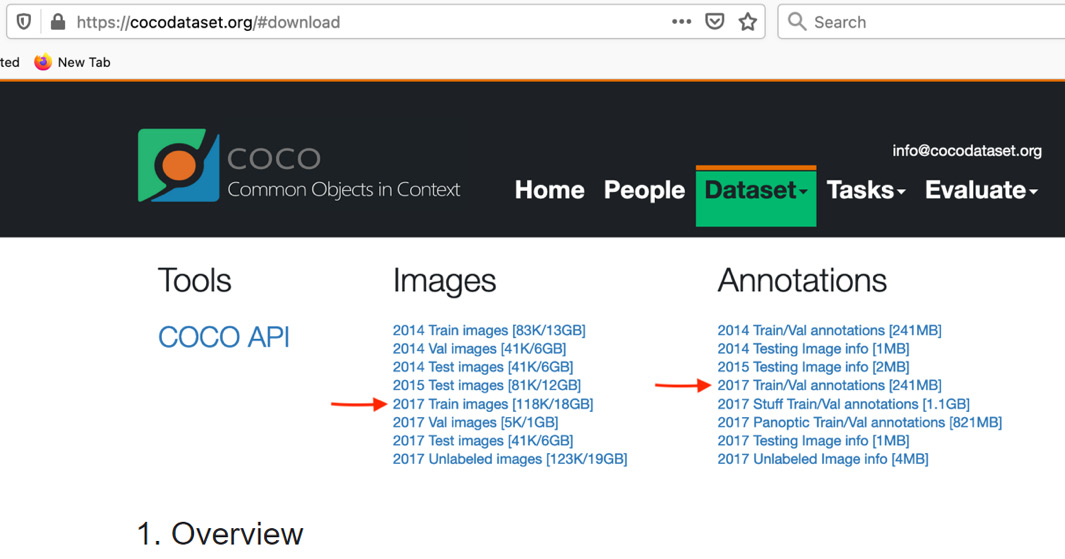
图 7.6 – COCO 网站的下载页面
我们解压缩 ZIP文件,然后删除它们。我们还删除了一些我们不会使用的提取文件,例如包含验证数据的文件。
以下屏幕截图显示了运行代码片段后coco_data目录的内容:
图 7.7 – 下载和提取的 COCO 数据
组装数据
虽然深度学习通常涉及大型数据集,例如 COCO 2017 中的所有图像和字幕,使用如此大的数据集训练模型需要强大的机器和大量的时间。我们将数据集限制为 4,000 张图像及其标题,以便本章描述的模型可以在几天而不是几周内完成训练。
在本节中,我们将描述我们如何处理 COCO 2017 数据,以过滤掉 4,000 张图像及其说明,调整图像大小,并根据说明创建词汇表。我们将在Assembling_the_data.ipynb笔记本中工作。我们将必要的包导入笔记本的第一个单元格,如以下代码块所示:
import os
import json
import random
import nltk
import pickle
from shutil import copyfile
from collections import Counter
from PIL import Image
from vocabulary import Vocabulary过滤图像及其标题
正如文中提到的在上一节中,我们通过过滤掉 1,000 张图像来限制训练数据集的大小,每张图像分为四个类别:摩托车、飞机、大象和网球拍。我们还过滤掉这些图像的标题。
首先,我们处理instance_train2017.json元数据文件中的注释。此文件包含对象检测信息(您可以在以下网页上参考此和其他 COCO 数据集注释的详细信息:https ://cocodataset.org/#format-data )。我们在对象检测注释中使用category_id、image_id和area字段用于以下两个目的:
- 列出图像中存在的各种类别。
- 按区域的降序对图像中的类别进行排序。这有助于我们在过滤过程中确定一个类别在图像中是否突出。例如COCO中下图中绿色标记的网球拍数据集不如人、汽车、行李等突出。所以字幕对于图像,不要提及网球拍:

图 7.8 – 非主要类别
按类别选择图像
在下面的代码中片段,我们首先读取 JSON 文件并初始化变量:
obj_fl = "./coco_data/annotations/instances_train2017.json"
with open(obj_fl) as json_file:
object_detections = json.load(json_file)
CATEGORY_LIST = [4, 5, 22, 43]
COUNT_PER_CATEGORY = 1000
category_dict = dict()
for category_id in CATEGORY_LIST:
category_dict[category_id] = dict()
all_images = dict()
filtered_images = set()对于CATEGORY_LIST ,我们在 JSON 中的类别数组中手动查找了四个类别的id 。例如,以下是一个类别的条目(您可以选择任何类别你希望的):
{"supercategory": "vehicle","id": 4,"name": "motorcycle"}
然后,我们在以下代码块中使用for循环来填充all_images和category_dict字典:
for annotation in object_detections['annotations']:
category_id = annotation['category_id']
image_id = annotation['image_id']
area = annotation['area']
if category_id in CATEGORY_LIST:
if image_id not in category_dict[category_id]:
category_dict[category_id][image_id] = []
if image_id not in all_images:
all_images[image_id] = dict()
if category_id not in all_images[image_id]:
all_images[image_id][category_id] = area
else:
current_area = all_images[image_id][category_id]
if area > current_area:
all_images[image_id][category_id] = area执行此for循环后,字典如下:
- all_images字典包含数据集中每个图像的类别及其区域。
- category_dict字典包含所有具有我们感兴趣的四个类别中的一个或多个类别的图像。
如果COUNT_PER_CATEGORY设置为-1,则表示您要过滤CATEGORY_LIST中指定类别的所有图像。因此,在if块中,我们只使用category_dict来获取图像。
否则,在else块中,我们过滤掉每个突出图像的COUNT_PER_CATEGORY数量四大类中。我们在else块中使用了两个for循环。第一个for循环,显示在以下代码块中,使用all_images字典中的图像特定类别和区域信息以按区域降序对每个图像的category_ids进行排序。换句话说,在这个for循环之后,字典中的值是一个类别列表,按照它们在图像中的显着性降序排列:
for image_id in all_images:
areas = list(all_images[image_id].values())
categories = list(all_images[image_id].keys())
sorted_areas = sorted(areas, reverse=True)
sorted_categories = []
for area in sorted_areas:
sorted_categories.append(categories[areas.index(area)])
all_images[image_id] = sorted_categorieselse块中的第二个for循环迭代存储在category_dict中的四个类别的图像,并使用存储在all_images字典中的信息过滤掉COUNT_PER_CATEGORY数量的最突出图像。这个for循环打印以下结果:

图 7.9 – 图像过滤代码的输出
选择字幕
在下一个单元格中笔记本,我们开始使用存储在captions_train2017.json元数据文件中的字幕。我们分离出与我们在前面的笔记本单元格中过滤的图像相关的标题,如以下代码块所示:
filtered_annotations = []
for annotation in captions['annotations']:
if annotation['image_id'] in filtered_images:
filtered_annotations.append(annotation)
captions['annotations'] = filtered_annotations在 JSON 文件中,标题存储在名为annotations的数组中。数组中的标题条目如下所示:
{"image_id": 173799,"id": 665512,"caption": "Two men herding a pack of elephants across a field."}
我们分离出image_id值在filters_images集中的标题。
字幕JSON 文件还有一个名为images的数组。在下一个for循环中,我们缩短图像数组以仅存储过滤图像的条目:
images = []
filtered_image_file_names = set()
for image in captions['images']:
if image['id'] in filtered_images:
images.append(image)
filtered_image_file_names.add(image['file_name'])
captions['images'] = images最后,我们将过滤后的字幕保存在名为coco_data/captions.json的新文件中,并将过滤后的图像文件(使用copyfile函数)复制到一个名为coco_data/images的新目录:

图 7.10 – 图像过滤代码的输出
这完成了我们的数据组装步骤,并为我们提供了一个包含 4,000 张图像和 20,000 个标题的训练数据集,涵盖 4 个类别。
调整图像大小
COCO 中的所有图片数据集是彩色的,但它们可以是各种大小。如下所述,所有图像都被转换为 3 x 256 x 256 的统一尺寸,并存储在名为images的文件夹中。以下代码块来自Assembling_the_data.ipynb笔记本中定义的resize_images函数:
def resize_images(input_path, output_path, new_size):
if not os.path.exists(output_path):
os.makedirs(output_path)
image_files = os.listdir(input_path)
num_images = len(image_files)
for i, img in enumerate(image_files):
img_full_path = os.path.join(input_path, img)
with open(img_full_path, 'r+b') as f:
with Image.open(f) as image:
image = image.resize(new_size, Image.ANTIALIAS)
img_sv_full_path = os.path.join(output_path, img)
image.save(img_sv_full_path, image.format)
if (i+1) % 100 == 0 or (i+1) == num_images:
print("Resized {} out of {} total images.".format(i+1, num_images))我们通过前面代码块中显示的resize_images函数的以下参数:
- input_path : coco_data/images文件夹,我们保存了来自 COCO 2017 训练数据集的 4,000 个过滤图像
- output_path : coco_data/resized_images文件夹
- new_size : 尺寸 [256 x 256]
在前面的代码片段中,我们遍历input_path中的所有图像,并通过调用其resize方法调整每个图像的大小。我们将每个调整大小的图像保存到output_path文件夹。
以下是resize_images函数发出的打印消息:
图 7.11 – 图像大小调整的输出
那么,在那同样的笔记本单元,我们使用以下命令将调整大小的图像移动到coco_data/images目录:
!rm -rf ./coco_data/images
!mv ./coco_data/resized_images ./coco_data/images调整图像大小后,我们建立词汇表。
建立词汇
在最后一个单元格在Assembling_the_data.ipynb笔记本中,我们使用build_vocabulary函数处理与过滤后的 COCO 数据集图像相关的标题。这个函数创建一个Vocabulary类的实例。Vocabulary类在单独的文件词汇表.py中定义,以便可以在训练和预测阶段重用该定义,如下所述。这就是为什么我们在这个笔记本的第一个单元格中添加了from 词汇表 import Vocabulary语句的原因。
以下代码块显示了words.py文件中的Vocabulary类定义:
class Vocabulary(object):
def __init__(self):
self.token_to_int = {}
self.int_to_token = {}
self.current_index = 0
def __call__(self, token):
if not token in self.token_to_int:
return self.token_to_int['<unk>']
return self.token_to_int[token]
def __len__(self):
return len(self.token_to_int)
def add_token(self, token):
if not token in self.token_to_int:
self.token_to_int[token] = self.current_index
self.int_to_token[self.current_index] = token
self.current_index += 1我们映射每个唯一的词 - 称为标记- 在整数的标题中。Vocabulary对象有一个字典命名为token_to_int以检索与令牌对应的整数和名为int_to_token的字典以检索与整数对应的令牌。
以下代码片段显示了Assembling_the_data.ipynb笔记本最后一个单元格中build_vocabulary函数的定义:
def build_vocabulary(json_path, threshold):
with open(json_path) as json_file:
captions = json.load(json_file)
counter = Counter()
i = 0
for annotation in captions['annotations']:
i = i + 1
caption = annotation['caption']
tokens = nltk.tokenize.word_tokenize(caption.lower())
counter.update(tokens)
if i % 1000 == 0 or i == len(captions['annotations']):
print("Tokenized {} out of total {} captions.".format(i, len(captions['annotations'])))
tokens = [tkn for tkn, i in counter.items() if i >= threshold]
vocabulary = Vocabulary()
vocabulary.add_token('<pad>')
vocabulary.add_token('<start>')
vocabulary.add_token('<end>')
vocabulary.add_token('<unk>')
for i, token in enumerate(tokens):
vocabulary.add_token(token)
return vocabulary
vocabulary = build_vocabulary(json_path='coco_data/captions.json', threshold=4)
vocabulary_path = './coco_data/vocabulary.pkl'
with open(vocabulary_path, 'wb') as f:
pickle.dump(vocabulary, f)
print("Total vocabulary size: {}".format(len(vocabulary)))我们通过字幕JSON ( coco_data/captions.json ) 的位置作为函数的json_path参数和4值作为阈值参数。
首先,我们使用json.load来加载 JSON。nltk代表自然语言工具包。我们使用 NLTK 的tokenize.word_tokenize方法将标题句子拆分为单词和标点符号。我们使用collections.Counter字典对象来计算每个标记的出现次数。在处理完for循环内的所有字幕后,我们丢弃出现频率低于阈值的标记。
然后我们实例化Vocabulary对象并为其添加一些特殊标记—— <start>和<end>用于句子的开头和结尾,< pad>用于填充,而用作返回值Vocabulary对象的__call__方法被要求为token_to_int字典中不存在的令牌返回一个整数。然后,我们在for循环中将其余标记添加到Vocabulary 。
重要的提示
在添加任何其他标记之前将<pad>标记添加到词汇表中很重要,因为它确保将0分配为该标记的整数值。这使得<pad>标记的定义与coco_collate_fn中的编程逻辑一致,其中在创建一批填充字幕时直接使用零(torch.zeros() )。
最后,使用pickle.dump方法将词汇表保存在coco_data目录中。
以下是build_vocabulary函数发出的打印消息:
图 7.12 – 标记化的输出
重要的提示
下载数据集和组装数据是一次性处理步骤。如果您正在重新运行模型以恢复或重新开始训练,那么您无需重复到此为止的步骤,并且可以在此之后开始。
训练模型
在本节中,我们描述模型训练。它涉及使用torch.utils.data.Dataset和torch.utils.data.DataLoader类加载数据,使用pytorch_lightning.LightningModule类定义模型,设置训练配置,以及使用 PyTorch Lightning 框架的Trainer启动训练过程。我们将在本节中使用Training_the_model.ipynb笔记本和model.py文件。
我们将必要的包导入到Training_the_model.ipynb笔记本的第一个单元格中,如以下代码块所示:
import os
import json
import pickle
import nltk
from PIL import Image
import torch
import torch.utils.data as data
import torchvision.transforms as transforms
import pytorch_lightning as pl
from model import HybridModel
from vocabulary import Vocabulary数据集
接下来,我们定义CocoDataset类,它扩展了torch.utils.data.Dataset类。CocoDataset是一个地图风格的数据集,所以我们在类中定义了__getitem__()和__len__()方法。__len __()方法返回数据集中的样本总数,而__getitem__()方法返回给定索引处的样本(方法的idx参数,如以下代码块所示):
class CocoDataset(data.Dataset):
def __init__(self, data_path, json_path, vocabulary, transform=None):
self.image_dir = data_path
self.vocabulary = vocabulary
self.transform = transform
with open(json_path) as json_file:
self.coco = json.load(json_file)
self.image_id_file_name = dict()
for image in self.coco['images']:
self.image_id_file_name[image['id']] = image['file_name']
def __getitem__(self, idx):
annotation = self.coco['annotations'][idx]
caption = annotation['caption']
tkns = nltk.tokenize.word_tokenize(str(caption).lower())
caption = []
caption.append(self.vocabulary('<start>'))
caption.extend([self.vocabulary(tkn) for tkn in tkns])
caption.append(self.vocabulary('<end>'))
image_id = annotation['image_id']
image_file = self.image_id_file_name[image_id]
image_path = os.path.join(self.image_dir, image_file)
image = Image.open(image_path).convert('RGB')
if self.transform is not None:
image = self.transform(image)
return image, torch.Tensor(caption)
def __len__(self):
return len(self.coco['annotations'])如本节后面所述,__init__接收图像目录 ( coco_data/images ) 作为data_path参数和标题JSON ( coco_data/captions.json ) 作为json_path参数。它还接收Vocabulary对象。字幕JSON 使用 json.load 加载并存储在self.coco变量中。__init__中的for循环创建了一个名为self.image_id_file_name的字典,它将图像 ID 映射到文件名。
重要的提示
COCO 数据集每张图片有五个标题。由于我们的模型处理每个图像-字幕对,因此数据集的长度等于字幕的总数,而不是图像的总数。
前面代码块中的__getitem__()方法返回给定索引的图像-标题对。它检索与idx索引对应的标题,对标题进行标记,并使用词汇表将标记转换为相应的整数。然后,它检索与idx对应的图像 ID ,使用self.image_id_file_name字典获取图像的文件名,从文件中加载图像,并根据transforms参数转换图像。
CocoDataset对象作为参数传递给DataLoader ,如本节后面所述。但是DataLoader还需要一个collate函数,我们将在下面进行描述。
整理功能
我们定义在Training_the_model.ipynb笔记本的下一个单元格中整理名为coco_collate_fn()的函数。如以下代码片段所示,coco_collate_fn()接收一批图像及其相应的标题作为输入,名为data_batch。它为批处理中的标题添加填充:
def coco_collate_fn(data_batch):
data_batch.sort(key=lambda d: len(d[1]), reverse=True)
imgs, caps = zip(*data_batch)
imgs = torch.stack(imgs, 0)
cap_lens = [len(cap) for cap in caps]
padded_caps = torch.zeros(len(caps), max(cap_lens)).long()
for i, cap in enumerate(caps):
end = cap_lens[i]
padded_caps[i, :end] = cap[:end]
return imgs, padded_caps, cap_lens我们首先按标题长度降序对data_batch进行排序,然后将图像 ( imgs ) 和标题 ( caps ) 列表分开。
让我们使用<batch_size>来表示imgs列表的长度。它包含 3 x 256 x 256 维图像。使用torch.stack()函数将其转换为<batch_size> x 3 x 256 x 256 大小的单个张量。
同样,caps列表总共有<batch_size>个条目,它包含各种长度的标题。让我们使用<max_caption_length>来表示批次中最长字幕的长度。for循环将caps列表转换为一个名为padded_caps的张量,其大小为<batch_size> x <max_caption_length>。字幕比<max_caption_length>短的会用零填充。
最后,函数返回imgs、padded_caps和cap_lens;cap_lens列表包含批次中字幕的实际(非填充)长度。
CocoDataset对象和coco_collat e_fn()作为参数传递给DataLoader,如下一节所述。
数据加载器
get_loader ()函数是在Training_the_model.ipynb笔记本的下一个单元格中定义,如以下代码块所示:
def get_loader(data_path, json_path, vocabulary, transform, batch_size, shuffle, num_workers=0):
coco_ds = CocoDataset(data_path=data_path,
json_path=json_path,
vocabulary=vocabulary,
transform=transform)
coco_dl = data.DataLoader(dataset=coco_ds,
batch_size=batch_size,
shuffle=shuffle,
num_workers=num_workers,
collate_fn=coco_collate_fn)
return coco_dl该函数实例化一个名为coco_ds的CocoDataset对象,并在实例化名为coco_dl的torch.utils.data.DataLoader类型的对象期间将其以及coco_collate_fn函数作为参数传递。最后,函数返回coco_dl对象。
混合 CNN-RNN 模型
这模型在单独的文件中定义命名为model.py,以便我们可以在预测步骤中重用代码,如下所述。在model.py文件中可以看到,首先我们导入必要的包:
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pack_padded_sequence as pk_pdd_seq
import torchvision.models as models
import pytorch_lightning as pl与往常一样,我们的HybridModel类扩展了LightningModule。在本节的其余部分,我们将描述 CNN 和RNN 层,以及训练配置,例如优化器设置、学习率、训练损失和批量大小。
CNN 和 RNN 层
我们的模型是CNN模型和RNN模型的混合。我们在HybridModel类定义的__init__()中定义了两个模型的顺序层,如以下代码块所示:
def __init__(self, cnn_embdng_sz, lstm_embdng_sz, lstm_hidden_lyr_sz, lstm_vocab_sz, lstm_num_lyrs, max_seq_len=20):
super(HybridModel, self).__init__()
resnet = models.resnet152(pretrained=False)
module_list = list(resnet.children())[:-1]
self.cnn_resnet = nn.Sequential(*module_list)
self.cnn_linear = nn.Linear(resnet.fc.in_features,
cnn_embdng_sz)
self.cnn_batch_norm = nn.BatchNorm1d(cnn_embdng_sz,
momentum=0.01)
self.lstm_embdng_lyr = nn.Embedding(lstm_vocab_sz,
lstm_embdng_sz)
self.lstm_lyr = nn.LSTM(lstm_embdng_sz,
lstm_hidden_lyr_sz,
lstm_num_lyrs,
batch_first=True)
self.lstm_linear = nn.Linear(lstm_hidden_lyr_sz,
lstm_vocab_sz)
self.max_seq_len = max_seq_len
self.save_hyperparameters()对于 CNN 部分,我们使用ResNet-152架构。我们将使用现成的torchvision.models.resnet152模型。但是,对于 CNN 模型的输出,我们不想要图像属于给定类别类型(例如大象或飞机)的概率预测。相反,我们将使用 CNN 输出的图像的学习表示,然后将其作为输入传递给 RNN 模型。
因此,我们移除最后一个全连接( FC ) Softmax 层模型使用list(resnet.children())[:-1]语句,然后我们使用nn.Sequential()重新连接所有其他层。然后,我们添加一个名为self.cnn_linear的线性层,然后是一个名为self.cnn_batch_norm的批量标准化层。批量归一化被用作一种正则化技术,以避免过度拟合并使模型层更加稳定。
重要的提示
请注意,在前面的代码片段中实例化预定义的torchvision.models.resnet152模型时,我们传递了 pretrained=False 。这是因为预训练的 ResNet-152 是使用 ImageNet 数据集而不是 COCO 数据集进行训练的,如 ResNet 部分所述:https ://pytorch.org/vision/stable/models.html#id10 。
您当然也可以尝试使用pretrained=True选项并探索模型的准确性。虽然在 ImageNet 上训练的模型可能会提取一些类,如第 3 章中所分享的,使用预训练模型进行迁移学习,但由于两个数据集中图像的复杂性完全不同,因此整体准确性可能会受到影响。在本节中,我们决定使用pretrained=False从头开始训练模型。
对于__init__()的 RNN 部分,我们定义了 LSTM 层,如前面的代码块所示。LSTM 层从 CNN 获取编码图像表示并输出一个单词序列——一个最多包含self.max_seq_len 个单词的句子。我们对max_seq_len参数使用默认值20 。
接下来,我们在model.py文件中描述HybridModel类中定义的训练配置。
优化器设置
torch.optim.Adam优化器由HybridModel类的configure_optimizers方法返回,如下代码片段所示:
def configure_optimizers(self):
params = list(self.lstm_embdng_lyr.parameters()) + \
list(self.lstm_lyr.parameters()) + \
list(self.lstm_linear.parameters()) + \
list(self.cnn_linear.parameters()) + \
list(self.cnn_batch_norm.parameters())
optimizer = torch.optim.Adam(parameters, lr=0.0003)
return optimizer在实例化torch.optim.Adam优化器时,我们将lr=0.0003作为参数传递。lr站对于学习率。
重要的提示
您可以使用许多优化器。优化器的选择是一个非常重要的超参数,对模型的训练方式有很大的影响。陷入局部最小值通常是一个问题,在这种情况下首先要尝试更改优化器。您可以在此处找到所有支持的优化器的列表:https ://pytorch.org/docs/stable/optim.html
更改为 RMSprop 优化器
你可以还将前面语句中的Adam优化器更改为RMSprop,如下所示:
optimizer = torch.optim.RMSprop(parameters, lr=0.0003)RMSprop与诸如此类的序列生成模型有特殊关系。居中的版本首先出现在 Geoffrey Hinton 题为“使用递归神经网络生成序列”的论文( https://arxiv.org/pdf/1308.0850v5.pdf ) 中,并且在字幕生成类型的问题上取得了非常好的结果。它可以很好地避免这种模型的局部最小值。该实现在添加epsilon之前采用梯度平均值的平方根。
为什么一个优化器在某些情况下比其他优化器工作得更好,这在深度学习中仍然有点神秘。在本章中,为了您的学习,我们使用Adam和RMSprop优化器实现了训练。这应该让您为未来的努力和尝试各种其他优化器做好准备。
训练损失
HybridModel类的training_step()方法使用torch.nn.CrossEntropyLoss计算损失,如下代码块所示:
def training_step(self, batch, batch_idx):
loss_criterion = nn.CrossEntropyLoss()
imgs, caps, lens = batch
outputs = self(imgs, caps, lens)
targets = pk_pdd_seq(caps, lens, batch_first=True)[0]
loss = loss_criterion(outputs, targets)
self.log('train_loss', loss, on_epoch=True)
return losstraining_step()方法的批处理参数只不过是前面描述的coco_collate_fn返回的值,因此我们将这些值分配给这些值。然后将它们传递给forward方法以生成输出,如output = self(imgs, caps, lens)语句中所示。目标变量用于计算损失。
self.log语句_使用 PyTorch Lightning 框架的日志功能来记录损失。这就是我们能够检索损失曲线的方式,稍后在我们描述训练过程时会显示。
重要的提示
有关如何在 TensorBoard 中可视化损失曲线的详细信息,请参阅第 10 章的管理训练部分,缩放和管理训练。
学习率
正如我们前面提到,可以在HybridModel类的configure_optimizers()方法中的如下语句中改变lr学习率:
optimizer = torch.optim.Adam(params, lr=0.0003)重要的提示
如Adam — PyTorch 1.13 documentation中所述,默认lr值为1e-3,即0.001。我们已将lr值更改为0.0003以更好地收敛。
批量大小
在另一方面,使用更大的批量大小可以让您使用更高的学习率,从而减少训练时间。您可以在Training_the_model.ipynb中的以下语句中更改批量大小,其中get_loader()函数用于实例化DataLoader:
coco_data_loader = get_loader('coco_data/images',
'coco_data/captions.json',
vocabulary,
transform,
256,
shuffle=True,
num_workers=4)LSTM 输出的句子应该理想地描述HybridModel训练后输入到 CNN 的图像。在下一步中,我们将描述如何使用 PyTorch Lightning 框架提供的Trainer来启动模型训练。我们还描述了前面代码片段中描述的coco_data_loader是如何作为参数传递给Trainer的。
启动模型训练
我们工作过在上一节中关于HybridModel类的model.py文件中。现在,回到Training_the_model.ipynb笔记本,我们将在笔记本的最后一个单元格中工作,如以下代码块所示:
transform = transforms.Compose([
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225))])
with open('coco_data/vocabulary.pkl', 'rb') as f:
vocabulary = pickle.load(f)
coco_data_loader = get_loader('coco_data/images',
'coco_data/captions.json',
vocabulary,
transform,
128,
shuffle=True,
num_workers=4)
hybrid_model = HybridModel(256, 256, 512,
len(vocabulary), 1)
trainer = pl.Trainer(max_epochs=5)
trainer.fit(hybrid_model, coco_data_loader)在训练过程中,图像根据预训练的 ResNet CNN 模型的要求,执行变换变量中指定的预处理和归一化变换。转换变量作为参数传递给我们在上一节中描述的get_loader()函数。
然后,从coco_data/vocabulary.pkl文件中加载使用pickle持久化的Vocabulary 。
接下来,通过调用前面描述的get_loader函数创建一个名为coco_data_loader的DataLoader对象。
然后,创建名为hybrid_model的HybridModel实例,并使用trainer.fit()开始模型训练。如前面的代码块所示,我们将hybrid_model和coco_data_loader作为参数传递给fit方法。这以下是 PyTorch Lightning 在训练期间产生的输出截图:
图 7.13 – 训练输出
重要的提示
您可能已经注意到,我们只通过在 pl.Trainer实例化期间设置max_epochs=5来训练模型 5 个epoch,如前面的代码片段所示。为了获得真实的结果,模型需要在 GPU 机器上训练数千个 epoch 才能收敛,如下一节所示。
训练进度
为了促进为了提高模型训练速度,我们使用了 GPU,并开启了 PyTorch Lightning Trainer的 16 位精度设置,如下代码语句所示。如果您的底层基础架构具有 GPU,则可以使用gpu=n选项启用该选项,其中n是要使用的 GPU 数量。要使用所有可用的 GPU,请指定gpu=-1,如下所示:
trainer = pl.Trainer(max_epochs=50000,
precision=16, gpus=-1)使用较低的学习率有助于模型更好地训练,但训练需要更多时间。下图使用黑色箭头显示了lr=0.0003的损失曲线,与lr=0.001的另一条曲线相比:
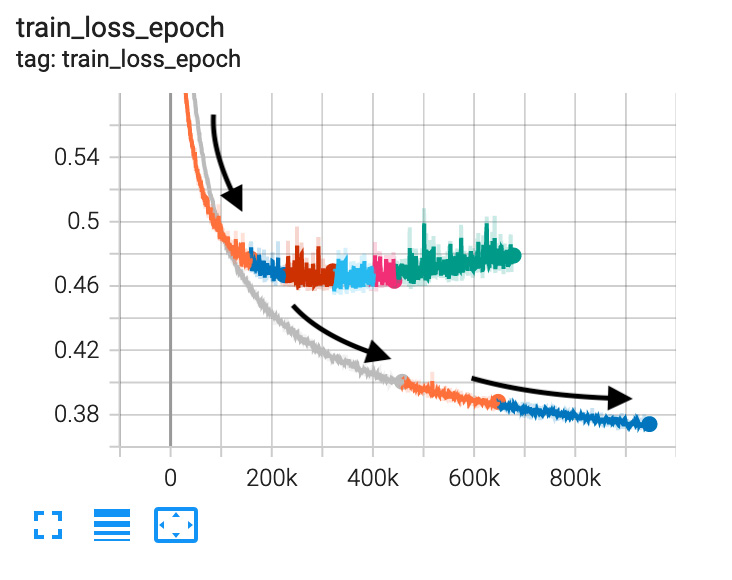
图 7.14 – 不同学习率的损失轨迹 – 越低越好
训练使用 RMSprop 优化器向我们展示了丢失率的良好下降,如下图所示:
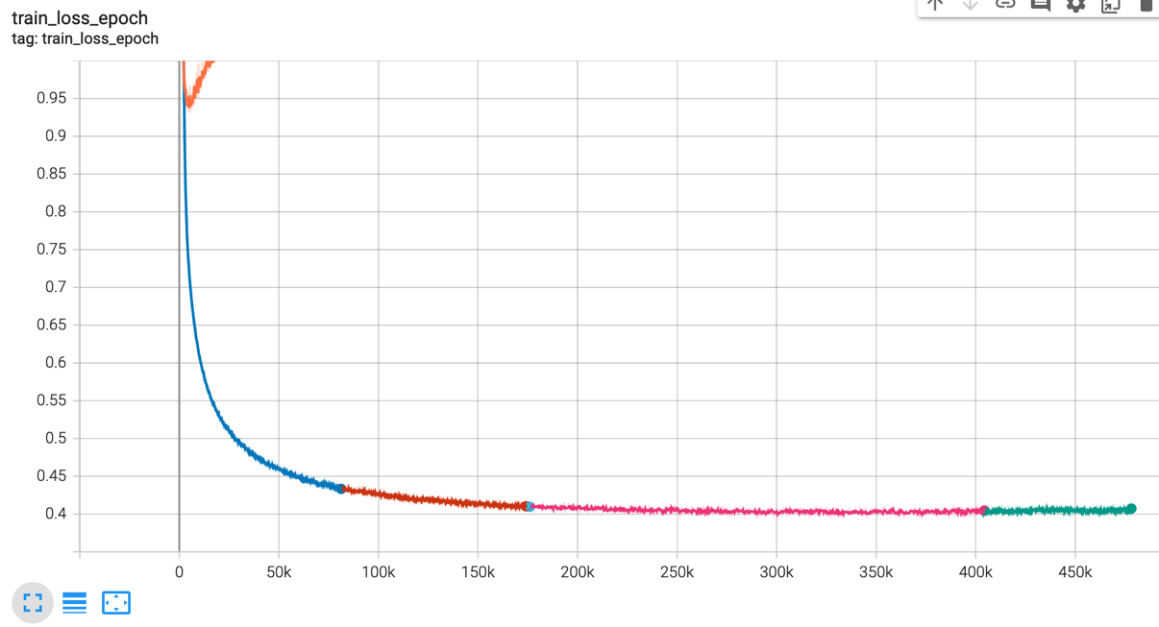
图 7.15 – RMSprop 的训练损失
生成字幕
我们在model.py文件中的HybridModel定义有几个特殊的实现用于预测的必要细节。我们将首先描述这些特性,然后我们将描述Generating_the_caption.ipynb笔记本中的代码。
HybridModel类中有get_caption方法,将调用该方法为图像生成标题。该方法将图像作为输入,通过 CNN 进行前向传递以生成 LSTM 的输入特征,然后使用贪婪搜索以最大概率生成标题:
def get_caption(self, img, lstm_sts=None):
def get_caption(self, img, lstm_sts=None):
"""CNN"""
features = self.forward_cnn_no_batch_norm(img)
"""LSTM: Generate captions using greedy search."""
token_ints = []
inputs = features.unsqueeze(1)
for i in range(self.max_seq_len):
hddn_vars, lstm_sts = self.lstm_lyr(inputs, lstm_sts)
model_outputs = self.lstm_linear(hddn_vars.squeeze(1))
_, predicted_outputs = model_outputs.max(1)
token_ints.append(predicted_outputs)
inputs = self.lstm_embdng_lyr(predicted_outputs)
inputs = inputs.unsqueeze(1)
token_ints = torch.stack(token_ints, 1)
return token_ints此外,我们在HybridModel类中名为forward_cnn_no_batch_norm()的单独方法中分离了 CNN 的前向逻辑的一部分。如前面的代码片段所示,这是get_caption用于通过 CNN 前向传递的方法,以便为 LSTM 生成输入特征,因为在CNN 的预测阶段将省略cnn_batch_norm模块:
def forward_cnn_no_batch_norm(self, input_images):
with torch.no_grad():
features = self.cnn_resnet(input_images)
features = features.reshape(features.size(0), -1)
return self.cnn_linear(features)对于剩下的在本节中,我们将在Generating_the_caption.ipynb笔记本中工作。首先,我们在 notebook 的第一个单元格中导入必要的包,如以下代码块所示:
import pickle
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from model import HybridModel
from vocabulary import Vocabulary在 notebook 的第二个单元格中,我们使用load_image函数来加载图像,对其进行转换并显示,如以下代码片段所示:
def load_image(image_file_path, transform=None):
img = Image.open(image_file_path).convert('RGB')
img = img.resize([224, 224], Image.LANCZOS)
plt.imshow(np.asarray(img))
if transform is not None:
img = transform(img).unsqueeze(0)
return img
# Prepare an image
image_file_path = 'sample.png'
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225))])
img = load_image(image_file_path, transform)然后,我们创建一个通过将检查点传递给HybridModel.load_from_checkpoint()来创建HybridModel实例,如以下代码块所示:
hybrid_model = HybridModel.load_from_checkpoint("lightning_logs/version_0/checkpoints/epoch=4-step=784.ckpt")
token_ints = hybrid_model.get_caption(img)
token_ints = token_ints[0].cpu().numpy()
# 将整数转换为字符串
with open('coco_data/vocabulary.pkl', 'rb') as f:
vocabulary = pickle.load(f)
predicted_caption = []
for token_int in token_ints:
token = vocabulary.int_to_token[token_int]
predicted_caption.append(token)
if token == '<end>':
break
predicted_sentence = ' '.join(predicted_caption)
# 打印生成的标题
print(predicted_sentence)我们通过将图像转换为模型的get_caption方法。get_caption方法返回与标题中的标记对应的整数,因此我们使用词汇表来获取标记并生成标题句子。我们终于打印了标题。
图片说明预测
现在我们可以传递一个看不见的图像(它不是训练集的一部分)并要求模型为我们生成标题。虽然我们的模型生成的句子还不完美(可能需要数万个 epoch 才能收敛),但在captions.json文件中快速搜索整个句子就会发现模型是自己创建的。该句子不是我们用来训练模型的输入数据的一部分。
中间结果
该模型由从图像中理解类,然后使用 RNN LSTM 模型为这些类和子类动作生成文本。您会在早期的预测中注意到一些噪音。
以下是 200 个 epoch 后的结果:
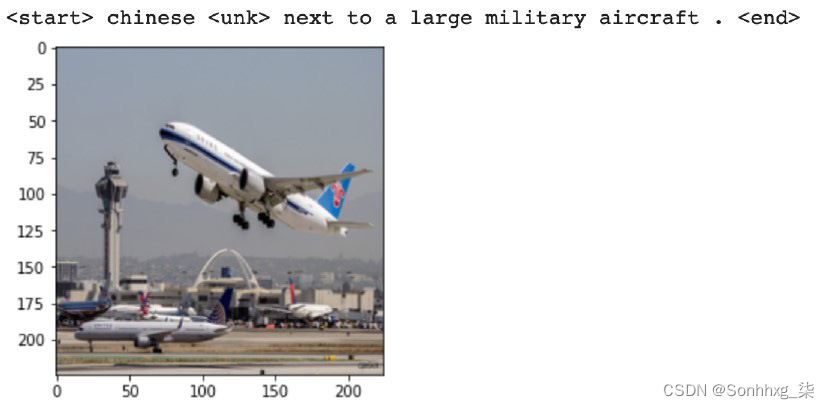
图 7.16 – 200 个 epoch 后的结果

图 7.17 – 1000 个 epoch 后的结果
以下是 2,000 个 epoch 后的结果:

图 7.18 – 2000 个 epoch 之后的附加结果
结果
你可能会发现在 10,000 个 epoch 之后,生成的字幕开始变得更像人类。随着更多的时期,结果将继续变得更好。但是,不要忘记我们只在 4,000 个图像集上训练了这个模型。这限制了它可以学习的所有上下文和英语词汇的范围。如果这是在数百万张图像上进行训练,那么在看不见的图像上的结果会好得多。
我们训练了这个模型在 GPU 服务器上,我们花了 4 天多的时间才完成。以下是 7,000 个 epoch 后对 RMSprop 的一些字幕预测,批量大小为 256,学习率为0.001:

图 7.19 – RMSprop 7000 epoch 后的结果
10,000 个 epoch 后的结果如下:

图 7.20 – 10,000 个 epoch 后的结果
如您所见,我们是为我们的模型获得有趣的结果,尤其是在更高的时期。现在我们可以要求机器像人类一样生成字幕。
下一步
现在我们已经展示了机器如何为图像生成标题,作为附加练习,您可以尝试以下方法来提高您的技能:
- 尝试各种其他训练参数组合,例如不同的优化器、学习率或多个 epoch。
- 尝试将 CNN 架构从 ResNet-152 更改为 ResNet-50 或其他类似 AlexNet 或 VGGNet。
- 尝试使用不同数据集的项目。在半监督领域中还有其他可用的数据集,其中包含特定于应用程序的标题,例如制造业或医学图像。
- 如前面关于半监督学习介绍的部分所示,您可以使用任何风格,例如莎士比亚的诗歌或文本,而不是生成简单的英语字幕,首先在这些文本上训练模型,然后使用风格- 生成字幕的传输机制。要重新创建之前显示的结果,您可以在歌词数据集上进行训练,并让机器模仿他们的诗歌风格。
- 最后,为了进一步扩展您的视野,您可以尝试结合其他模型。音频也是序列的一种形式,您可以尝试为某些给定图像自动生成音频评论的模型。
概括
我们在本章中看到了 PyTorch Lightning 如何使用许多开箱即用的功能轻松创建半监督学习模型。我们已经看到了如何使用机器为图像生成标题的示例,就好像它们是由人类编写的一样。我们还看到了结合 CNN 和 RNN 架构的高级神经网络架构的代码实现。
使用机器学习算法创作艺术为该领域的工作开辟了新的可能性。我们在这个项目中所做的是对该领域最近开发的算法的适度包装,将它们扩展到不同的领域。生成文本中经常出现的一个挑战是上下文准确性参数,它根据问题衡量创建的歌词的准确性,这对人类有意义吗?提出某种技术标准来衡量此类模型在这方面的准确性是未来非常重要的研究领域。
这种多模式学习的想法也可以扩展到带有音频的视频。在电影中,屏幕上发生的动作(例如打斗、浪漫、暴力或喜剧)与播放的背景音乐之间存在很强的相关性。最终,应该可以将多模态学习扩展到视听领域,预测/生成短视频的背景乐谱(甚至可以使用机器学习生成的背景乐谱重新创建查理卓别林电影!)。
相关文章
- shiro简单学习的简单总结
- Java核心知识点学习----线程同步工具类,CyclicBarrier学习
- 性能测试需要系统的学习一下,这个对提升自己对架构的认识非常的有用,
- 机器学习笔记 - pytorch + unet + 数据科学碗竞赛 医学图像分割
- 机器学习笔记 - Kornia:结合OpenCV的PyTorch框架
- 想比较全面地学习 SAP XXX,能指导下从哪儿开始学习吗?
- SAP Spartacus Loader Meta Reducer学习笔记 - loaderReducer
- Flutter从入门到进阶实战携程网app开发&Flutter学习笔记
- linux学习:虚拟机VMware安装CentOS 7.4的方法
- DL框架:主流深度学习框架(TensorFlow/Pytorch/Caffe/Keras/CNTK/MXNet/Theano/PaddlePaddle)简介、多个方向比较、案例应用之详细攻略
- JavaSE进阶 | 常用类学习(String类和StringBuffer类)
- 数学建模学习(34):自组织神经网络,讲解+代码
- pytorch不同的层设置不同的学习率
- 效率倍增啊,20个面向数据科学家的自动机器学习(AutoML)库来了
- 推荐收藏:Pytorch深度学习建模流程总结
- 自适应学习率调整:AdaDelta
- 【统计学习方法】1、统计学习方法概论
- 机器学习基本算法的sklearn接口
- 【修改数百次】全网最适合零基础人群入门网络安全的学习路线来啦
- 【Pytorch Lighting】第 3 章:使用预训练模型进行迁移学习
- 【Pytorch Lighting】第 1 章:PyTorch Lightning adventure
- OpenCV-Python学习(1)—— OpenCV历史与安装
- 如何获取和处理数据以供机器学习使用?
- pytorch学习笔记(十):卷积神经网络CNN(进阶篇)
- pytorch学习笔记(四):线性回归(用pytorchAPI)