
【统计学习方法】2、EM算法及其推广
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计。
EM算法的每次迭代由两步组成:E步(求期望)+M步(求极大值)
EM算法:期望极大算法(expectation maxmization algorithm)
9.1 EM算法的引入
EM算法就是还有隐变量的概率模型参数的极大似然估计法,或极大后验概率估计法。
首先介绍一下极大似然估计:
给定:模型(参数全部或者部分未知)和数据集(样本)
估计:模型的未知参数。
在最大释然估计中,我们试图在给定模型的情况下,找到最佳的参数,使得这组样本出现的可能性最大。
极大似然估计,只是一种概率论在统计学中的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次实验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率值最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
最大似然估计你可以把它看作是一个反推。多数情况下我们是根据已知条件来推算结果,而最大似然估计是已经知道了结果,然后寻求使该结果出现的可能性最大的条件,以此作为估计值。比如,如果其他条件一定的话,抽烟者发生肺癌的危险时不抽烟者的5倍,那么如果现在我已经知道有个人是肺癌,我想问你这个人抽烟还是不抽烟。你怎么判断?你可能对这个人一无所知,你所知道的只有一件事,那就是抽烟更容易发生肺癌,那么你会猜测这个人不抽烟吗?我相信你更有可能会说,这个人抽烟。为什么?这就是“最大可能”,我只能说他“最有可能”是抽烟的,“他是抽烟的”这一估计值才是“最有可能”得到“肺癌”这样的结果。这就是最大似然估计。
一般步骤:
(1)写出似然函数;
(2)对数似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求。


9.1.1 EM算法

中间推导:
∵
\because
∵
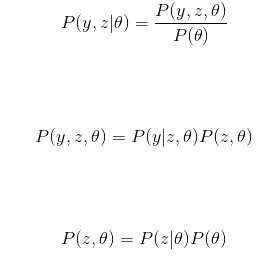
所以有:



EM算法:


9.1.2 EM算法的导出
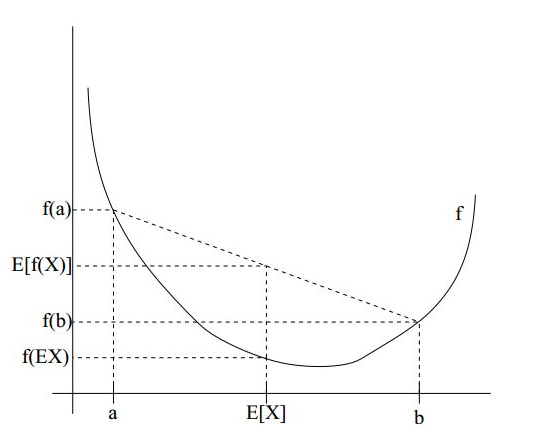
Jensen 不等式: E [ f ( x ) ] > = f ( E [ x ] ) E[f(x)]>=f(E[x]) E[f(x)]>=f(E[x])

EM算法:
我们面对一个含有隐变量的概率模型,目标是极大化观测数据(不完全数据) Y Y Y关于参数 θ \theta θ的对数似然函数,即极大化:
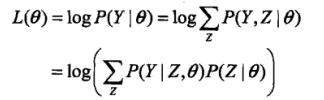
极大化的困难:上式含有未观测数据并包含积分的对数
极大化 L ( θ ) L(\theta) L(θ)的过程:迭代方法,逐步极大化

EM算法步骤:
- 初始化参数 θ ( 0 ) \theta^{(0)} θ(0),开始迭代;
- E步:假设
θ
(
i
)
\theta^{(i)}
θ(i)为第
i
i
i次迭代参数
θ
\theta
θ的估计值,则在第
i
+
1
i+1
i+1次迭代中,计算
Q
i
(
z
)
Q_i(z)
Qi(z):
Q i ( z ) = P ( Z ∣ Y , θ ( i ) ) Q_i(z)=P(Z|Y,\theta^{(i)}) Qi(z)=P(Z∣Y,θ(i)) - M步:求使得
l
(
θ
(
i
)
)
l(\theta_{(i)})
l(θ(i))极大化的
θ
\theta
θ,确定第
i
+
1
i+1
i+1次的参数估计值
θ
(
i
+
1
)
\theta^{(i+1)}
θ(i+1):
θ ( i + 1 ) = a r g m a x θ Q ( θ , θ ( i ) ) \theta^{(i+1)}=arg max_{\theta}Q(\theta,\theta^{(i)}) θ(i+1)=argmaxθQ(θ,θ(i)) - 重复2~3步,直到收敛
9.1.3 EM算法在非监督学习中的应用

9.2 EM算法的收敛性
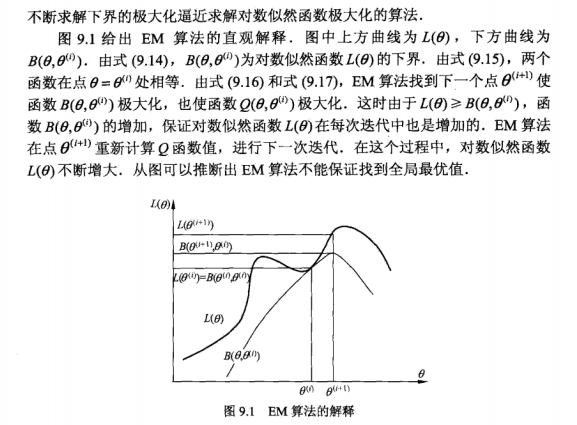
EM算法提供一种近似计算含有隐变量概率模型的极大似然估计的方法,其最大的优点是简单性和普适性,那么EM算法得到的估计序列是否收敛?如果收敛,是否收敛到全局或局部极大值?


只能得到局部极值点,不能得到全局极值点。
举例:
假定有训练集 x ( 1 ) , x ( 2 ) , … , x ( m ) {x(1), x(2), …, x(m)} x(1),x(2),…,x(m),包含 m m m个独立样本,希望从中找到该组数据的模型$p(x,z) 的参数,这里 的参数,这里 的参数,这里z$是模型的隐变量。
写出对数似然函数:
高斯式解释:
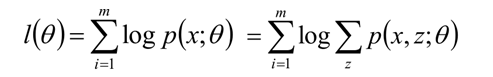
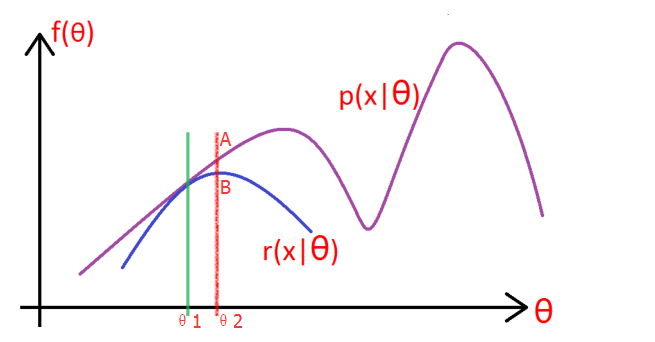
如上图所示,紫色的线是我们的目标模型p(x| θ) 的曲线。
-
因为这个模型含有隐变量z,所以为了消除z的影响,就先做一个除了不含有z模型:r(x| θ),使得r(x| θ) ≤ p(x| θ)。(你先别管这个r怎么得到,方法之后会说,反正总能给一个r满足这个条件吧!),取一个值令 r(x|θ1) = p(x|θ1),如绿线所示,然后对r(x| θ) 求极大似然,得到r的极值点B,和此时r的参数 θ2,如红线所示。
-
这一步上图没有给出,就是:将r的 参数从θ1变成θ2,此时r的图像就向右上方移动,与p相交于A,此时仍然有r≤p。
-
重复第二步和第三部,直到收敛。
从上图可以看出,EM算法只能求得局部极值点。
相关文章
- 编写一个函数,计算字符串中含有的不同字符的个数。字符在ACSII码范围内(0~127)。不在范围内的不作统计。
- pandas学习(常用数学统计方法总结、读取或保存数据、缺省值和异常值处理)
- [代码质量] Git统计本次提交新增代码行数,建议每个评审commit新增行数小于400行
- 利用JS跨域做一个简单的页面访问统计系统
- Java实现 LeetCode 466 统计重复个数
- Java实现 蓝桥杯VIP 算法训练 统计单词个数
- Lintcode---统计比给定整数小的数的个数
- Data - 深入浅出学统计 - 下篇
- 多变量频率统计——r
- python统计一个文本中重复行数的方法
- 研究人员用数据统计的方法来做文学研究
- Leetcode.1814 统计一个数组中好对子的数目
- atitit.提升备份文件复制速度(1) -----分析统计问题and解决方案
- 考研:研究生考试(七天学完)之《概率与统计》研究生学霸重点知识点总结之考试内容各科占比及常考知识重点梳理(随机事件和概率、一维随机变量及其分布、多维随机变量及其分布、随机变量的数字特征、大数定律和中心
- NLP:自然语言处理技术之NLP技术实践—自然语言/人类语言“计算机化”的简介、常用方法分类(基于规则/基于统计,离散式/分布式)之详细攻略
- ML之FE:特征工程/数据预处理之构造特征之特征分箱/数据分桶的常用六大类方法—基于统计(等距/等频+分位数+标准差/f方差)、基于数据分布(自然断点+重尾分布)、基于评价指标的自适应(卡方/Bes
- NLP:N-Gram(gram窗口分段再统计)基于概率统计语言模型的简介(包括马尔可夫假设概述)、使用方法、案例应用之详细攻略
- 100天精通Python(数据分析篇)——第62天:pandas常用统计方法大全(含案例)
- SQL VQ15 统计不同类型题目的刷题数,并按刷题数进行升序排列
- 【华为机试真题详解 Python实现】统计差异值大于相似值二元组个数【2023 Q1 | 100分】
- 统计学习方法-提升方法
- 统计学习方法中的标注问题
- 参数检验——当总体分布已知(如总体为正态分布),根据样本数据对总体分布的统计参数进行推断 非参数检验——利用样本数据对总体分布形态等进行推断的方法。
- 电商热门商品统计
- Python:统计大小写字母个数和数字个数