
403_交通数据综合分析实验
1、数据准备
1.1在master节点创建实验文件夹,拷贝数据文件
1.1.1在zkpk家目录下创建实验文件夹taxifx,并进入实验文件夹taxifx
[zkpk@master ~]$ mkdir taxifx
[zkpk@master ~]$ cd taxifx
1.1.2拷贝实验数据到实验文件夹中
[zkpk@master taxifx]$ cp ~/experiment/taxi.csv ./
1.1.3CSV 格式是数据分析工作中常见的一种数据格式。CSV意为逗号分隔值(Comma-Separated Values),其文件以纯文本形式存储表格数据(数字和文本)。每行只有一条记录,每条记录被逗号分隔符分隔为字段,并且每条记录都有同样的字段序列。
2、解析csv数据
2.1使用由 DataBricks 公司提供的第三方 Spark CSV 解析库来读取
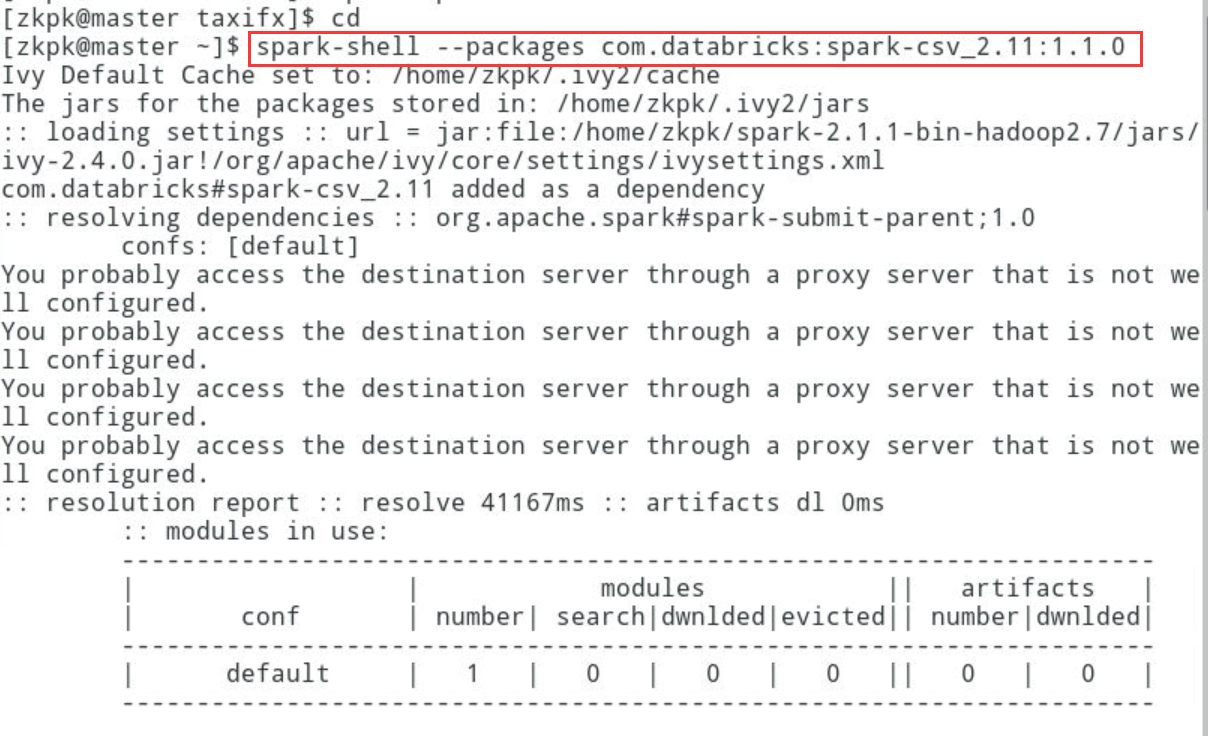
2.1.1加载csv第三方插件,启动spark-shell(加载csv解析插件),出现如下结果即为csv解析包下载成功
[zkpk@master taxifx]$ cd
[zkpk@master ~]$ spark-shell --packages com.databricks:spark-csv_2.11:1.1.0
2.1.2导入数据
2.1.2.1导入实验所需的spark包
[zkpk@master ~]$ cd spark-2.1.1-bin-hadoop2.7/
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ bin/spark-shell

scala> import org.apache.spark._
import org.apache.spark._
scala> import org.apache.spark.sql._
import org.apache.spark.sql._
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._
scala> import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.feature.VectorAssembler
scala> import org.apache.spark.ml.clustering.KMeans
import org.apache.spark.ml.clustering.KMeans
2.1.2.2利用StructType定义字段格式,这里应该和csv数据集中的字段一一对应,StructField中的三个参数为字段名称,数据类型,和是否不允许为空
val fieldSchema =StructType(Array(
StructField("TID",StringType,true),
StructField("Lat",DoubleType,true),
StructField("Lon",DoubleType,true),
StructField("Time",StringType,true)
))

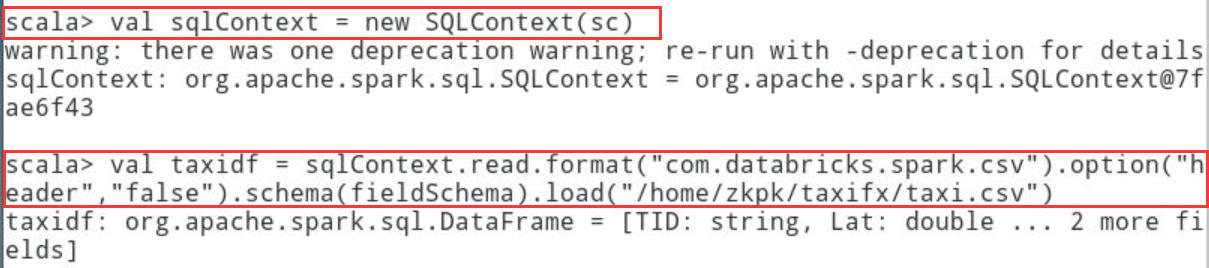
2.1.2.3利用sc创建sqlContext,用于执行SparkSQL,利用sqlContext对象的read接口,加载格式format为com.databricks.spark.csv的数据文件,并赋值给DataFrame对象taxidf
scala> val sqlContext = new SQLContext(sc)
scala> val taxidf = sqlContext.read.format("com.databricks.spark.csv").option("header","false").schema(fieldSchema).load("/home/zkpk/taxifx/taxi.csv")
2.1.2.4利用taxidf对象的printSchema方法打印输出该对象的字段格式
scala> taxidf.printSchema()

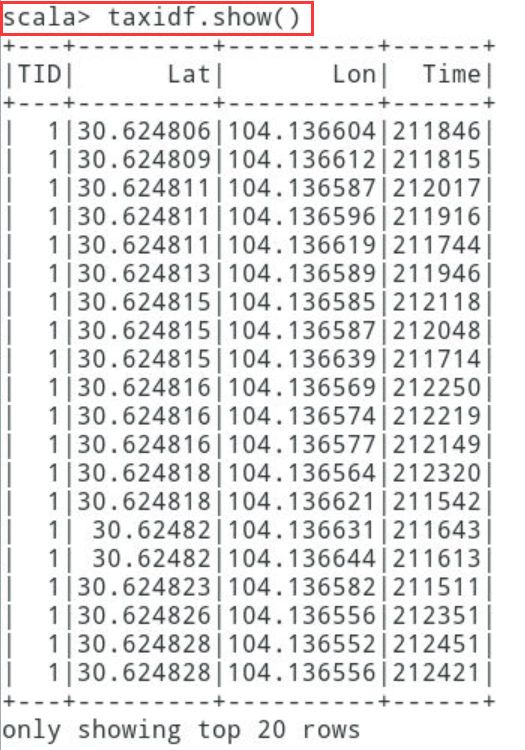
2.1.2.5利用taxidf对象的show方法打印输出前20条数据(默认为输出前20条数据)
scala> taxidf.show()
3、构建特征向量
3.1转换数据字段中的经纬度,定义特征数组
scala> val columns = Array("Lat","Lon")

3.2创建向量装配器VetorAssembler,并设置相关属性
scala> val va = new VectorAssembler().setInputCols(columns).setOutputCol("features")

3.3利用向量装配器的transform方法对导入的数据taxidf进行转化,并赋值给taxidf2
scala> val taxidf2 = va.transform(taxidf)

3.4利用taxidf2对象的show方法打印前20条数据查看
scala> taxidf2.show()

4、聚类模型训练
4.1进行K-Means聚类模型训练
4.1.1K-Means是迭代算法,所以将数据缓存到内存中加快计算速度
4.1.1.1Spark命令行方法,没有具体参数的话,可以加上括号,也可以不加
scala> taxidf2.cache

4.1.2将数据集划分比例分别作为训练集和测试集
scala> val trainTestRatio = Array(0.7,0.3)

4.1.3对数据集进行随机划分,randomSplit 的第二个参数为随机数的种子
scala> val Array(trainingData,testData) = taxidf2.randomSplit(trainTestRatio,2333)

4.1.4设置K-Means模型参数,创建模型
4.1.4.1setK():是一个 “Parameter setter”,用于设置聚类的簇数量
4.1.4.2setFeaturesCol():设置数据集中的特征列所在的字段名称
4.1.4.3setPredictionCol:设置生成预测值时使用的字段名称
scala> val km = new KMeans().setK(10).setFeaturesCol("features").setPredictionCol("prediction")

4.1.5利用fit方法将Kmeans对象对指定数据的特征进行匹配适应,训练模型
4.1.5.1fit():将 KMeans 对象对指定数据的特征进行匹配适应,训练模型
scala> val kmModel = km.fit(taxidf2)

4.1.6获取Kmeans模型的聚类中心,可以看到之前设定数量为 10 的聚类结果
scala> val Result = kmModel.clusterCenters

4.1.7将结果转换为RDD类型,进行经纬度互换,调用RDD对象的saveAsTextFile方法保存结果到本地
scala> val kmRDD1 = sc.parallelize(Result)
scala> val kmRDD2 = kmRDD1.map(x=>(x(1),x(0)))
scala> kmRDD2.saveAsTextFile("/home/zkpk/taxifx/kmResult")

5、聚类模型测试
5.1.对测试集进行聚类分析
5.1.1调用Kmeans模型的transform方法对测试数据进行聚类,结果赋值给predictions对象
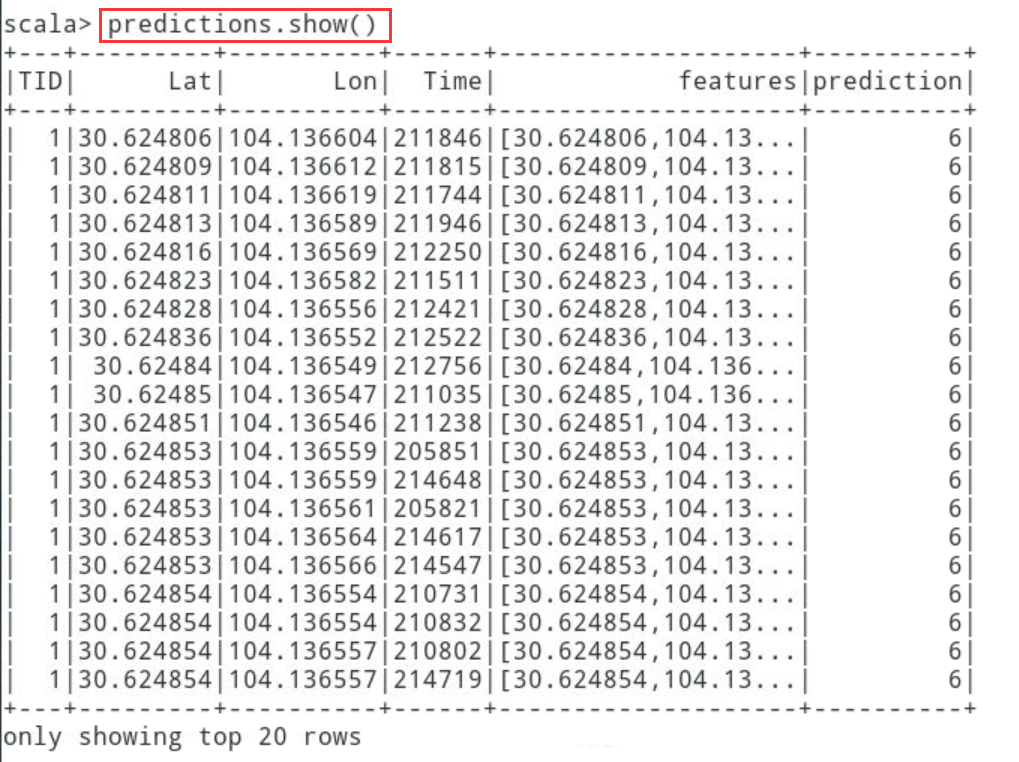
scala> val predictions = kmModel.transform(testData)

5.1.2调用predictions对象的show方法,输出预测结
scala> predictions.show()
6、分析预测结果
6.1预测结果为DataFrame,我们先将其注册为临时表perdictions,然后使用SQL查询功能
scala> predictions.registerTempTable("predictions")

6.2利用SQL查询”每天哪个时段的出租车最繁忙”和“每天哪个时段的出租车最空闲”需求
6.2.1提取出 Time 字段的前 2 位作为一天之中的小时数
6.2.2基于小时数进行不同预测类型的数量进行统计
scala> val tmpQuery = predictions.select(substring($"Time",0,2).alias("hour"),$"prediction").groupBy("hour","prediction")

6.2.3利用聚焦函数agg的count实现,并以desc降序输出结果
scala> val predictCountdesc = tmpQuery.agg(count("prediction").alias("count")).orderBy(desc("count"))

6.2.4可以发现某一区域在前20条数据中出现次数较高,此区域即为出租车最繁忙区域,如4号区域,可以看到在下午14-15点这一时间段,4号区域的载客量为5552最多最繁忙,,因此我们在对表predictions进行where查询,找出4号区域的经纬度记录下来,稍后我们看一下这个位置具体在哪里
scala> predictCountdesc.show()

scala> val busyarea = predictions.select($"Lat",$"Lon").where("prediction=4")
scala> busyarea.show()

6.2.4.1可以看出繁忙的4区域的经纬度基本在[104.072959,30.658476]左右
6.2.5再次利用聚焦函数agg的count实现,并以asc降序输出结果
scala> val predictCountasc = tmpQuery.agg(count("prediction").alias("count")).orderBy(asc("count"))

6.2.6可以发现某一区域在前20条数据中出现次数较高,此区域即为出租车最空闲区域,例如9号区域,可以发现在早上8点到10点时间段,9号区域的载客量为最少最空闲,因此我们在对表predictions进行查询,找出9号区域的经纬度记录下来,稍后我们看一下这个位置具体在哪里
scala> predictCountasc.show()

scala> val notbusyarea = predictions.select($"Lat",$"Lon").where("prediction=9")
scala> notbusyarea.show()
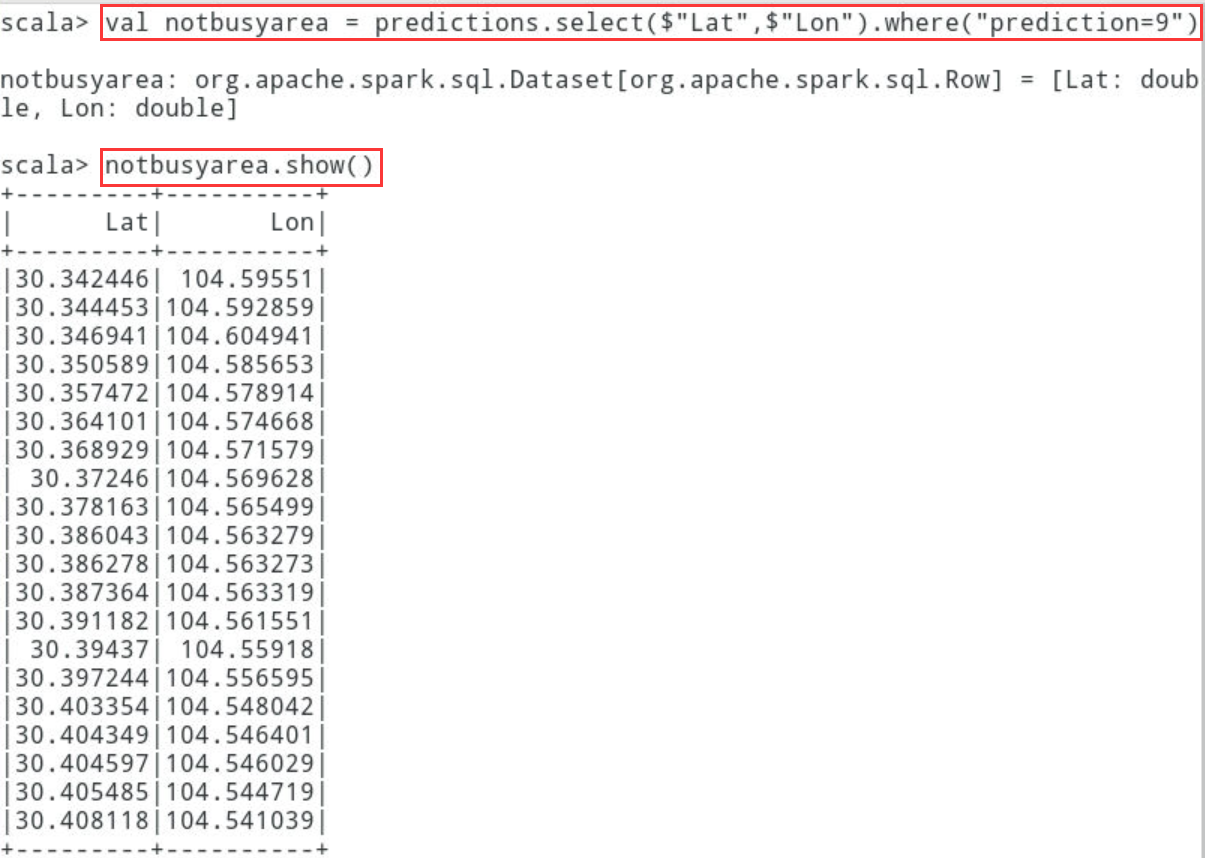
6.2.6.1可以看到不繁忙区域9的经纬度在[104.571579,30.368929]左右
6.3利用SQL查询“每天哪个区域的出租车最繁忙”和“每天哪个区域的出租车最空闲”需求
6.3.1这里的结果可以对聚类区域进行分组统计操作,即可得到每个区域的出租车载客次数总计
scala> val busyZones = predictions.groupBy("prediction").count()
scala> busyZones.show()

6.3.1.1可以看到每天区域4最繁忙,载客次数为68366
6.3.1.2可以看到每天区域9最空闲,载客次数为141
6.3.2调用busyZones对象的write.csv(“路径”)方法,保存结果到本地
scala> busyZones.write.csv("/home/zkpk/taxifx/busyZones")

6.3.3利用:quit退出spark shell

7、数据可视化
7.1本实验利用百度地图的相关API实现出租车数据地图可视化
7.2注册百度地图开放平台和创建自己的应用
7.2.1现在浏览器中打开百度地图开放平台(http://lbsyun.baidu.com),使用百度账户登录(若没有账户请自行创建)
7.2.2登录完成后,在导航栏输入百度地图开放平台控制台页面(http://lbsyun.baidu.com/apiconsole/key)
7.2.3进入如下界面

7.2.4在API控制台的“查看应用”界面,点击“创建应用”按钮
7.2.5填写创建应用表单
7.2.5.1应用名称可自定义
7.2.5.2应用类型选择浏览器端
7.2.5.3白名单为*号
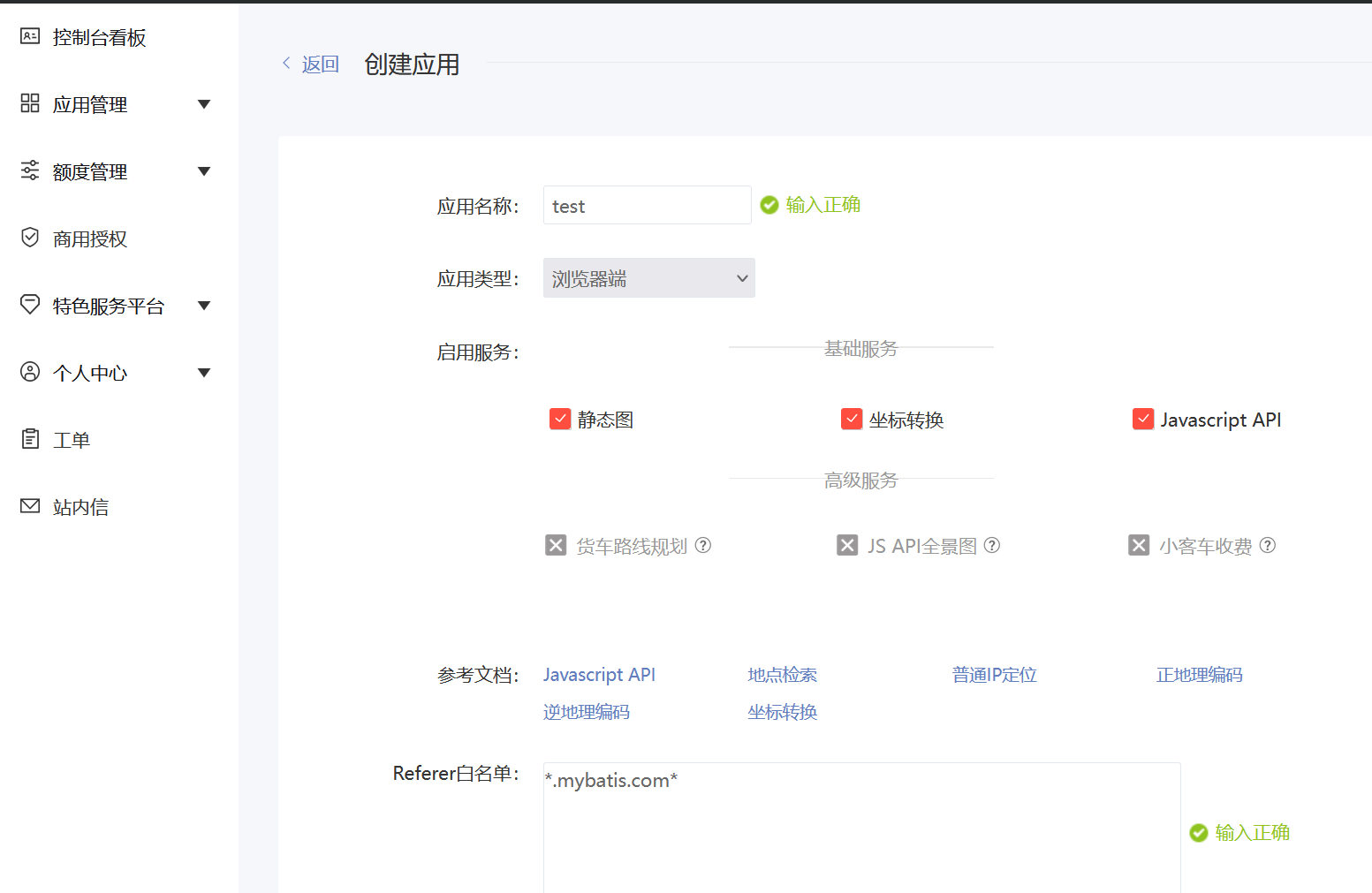
7.2.5.4点击“提交”按钮
7.2.6应用创建成功后,可在应用列表中看到相应应用信息
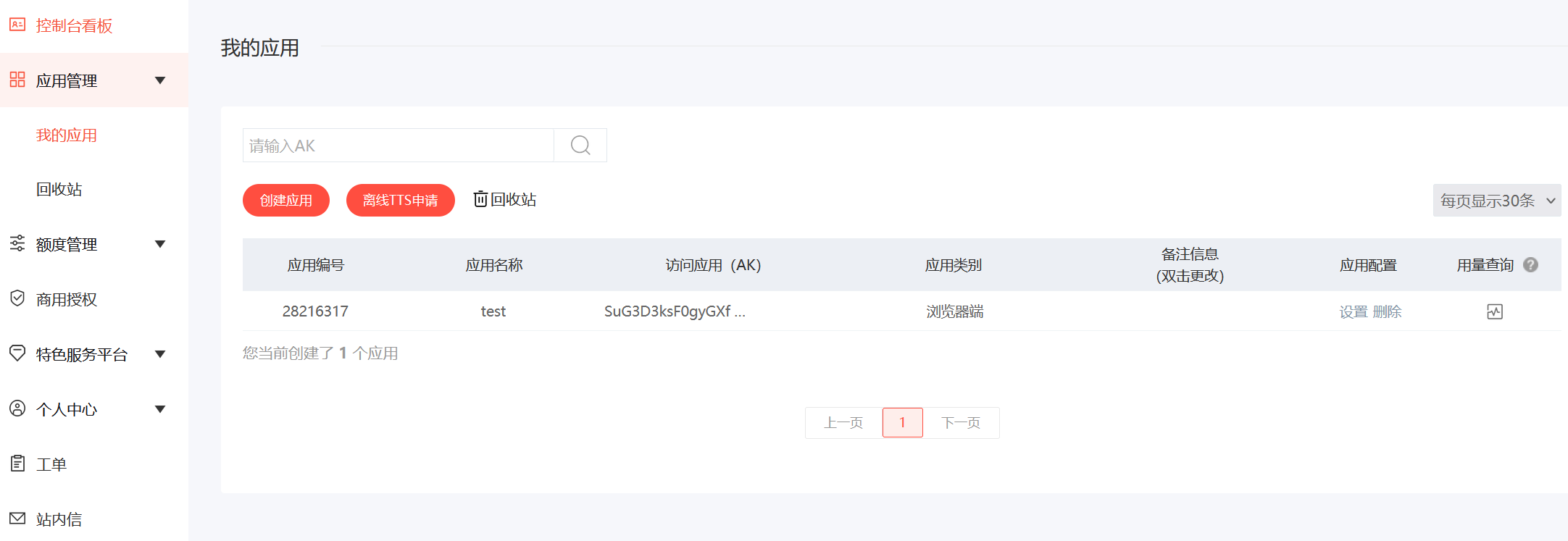
7.2.7记住上图的应用AK,稍后我们会用此AK去调用百度地图的相关服务
7.2.8在测试数据使用聚类模型进行数据分析中,我们将结果保存在/home/zkpk/taxifx/kmResult目录中
7.2.9数据处理
7.2.9.1利用cat重定向将分散在各个文件中的结果合并在单个文件中
[zkpk@master ~]$ cd taxifx/kmResult
[zkpk@master kmResult]$ cat part-* >> kmresult.csv

7.2.9.2利用sed命令来指定字符的删除操作,正则表达式s/^.//匹配了行首的第一个字符(左括号),正则表达式s/.$//匹配了行末的最后一个字符(右括号)
[zkpk@master kmResult]$ sed 's/^.//' kmresult.csv >> test1.csv
[zkpk@master kmResult]$ sed 's/.$//' test1.csv >> test2.csv

7.2.9.3将所有的换行符替换为分隔符“|”, 正则表达式 :a;N;$!ba;s/\n/|/g 中: a
用于创建一个标记,通过 N 追加当前行和下一行到模式区域。 $!ba
的意思是如果处于最后一行前,则跳转到之前的标记处。最后定义好的置换操作,把模式区域(即整个文件)的每一个换行符
\n 换成一个分隔符“|”
[zkpk@master kmResult]$ sed ':a;N;$!ba;s/\n/|/g' test2.csv >> test3.txt
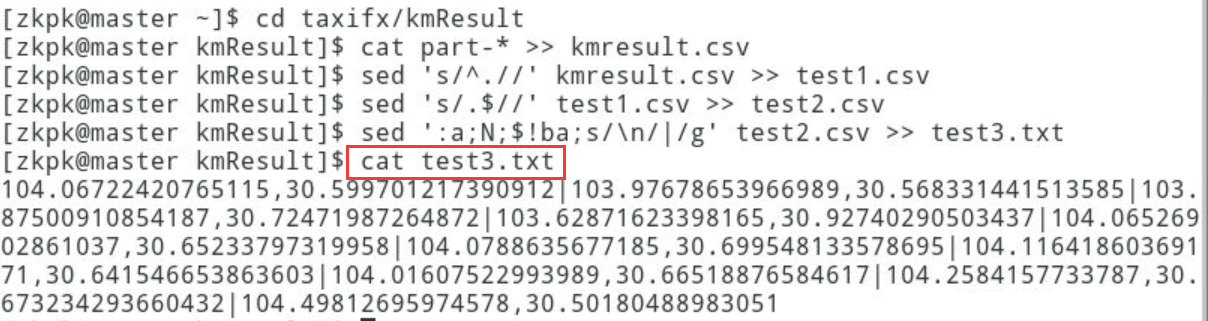
7.2.9.4用cat打开test3.txt查看并复制所有参数作为请求后面的参数
[zkpk@master kmResult]$ cat test3.txt
7.2.10设置请求百度地图API的相关参数
7.2.10.1应用授权码AK(此处的ak码为你创建应用时的ak码)
ak= FNlqH4eBZmMCyCELAz4VWsNcZH******
7.2.10.2设置图片的宽高度
height=650width=1000
7.2.10.3设置地图中心点的经纬度
center=104.072959,30.658476
7.2.10.4设置经纬度列表(直接粘贴刚才赋值的test3.txt的内容即可)
markers=104.06722420765115,30.599701217390912|103.97678653966989,30.568331441513585|103.87500910854187,30.72471987264872|103.62871623398165,30.92740290503437|104.06526902861037,30.65233797319958|104.0788635677185,30.699548133578695|104.11641860369171,30.641546653863603|104.01607522993989,30.66518876584617|104.2584157733787,30.673234293660432|104.49812695974578,30.50180488983051
7.2.10.5设置地图缩放级别
zoom=11
7.2.11我们将上述各项参数结合起来拼接成API请求即可向百度地图开放平台提交请求(下面的URL只是一个例子,ak请替换成自己创建的)
http://api.map.baidu.com/staticimage/v2?width=1000&height=650¢er=104.072959,30.658476&markers=104.06722420765115,30.599701217390912|103.97678653966989,30.568331441513585|103.87500910854187,30.72471987264872|103.62871623398165,30.92740290503437|104.06526902861037,30.65233797319958|104.0788635677185,30.699548133578695|104.11641860369171,30.641546653863603|104.01607522993989,30.66518876584617|104.2584157733787,30.673234293660432|104.49812695974578,30.50180488983051&zoom=11&ak=FNlqH4eBZmMCyCELAz4VWsNcZH******
7.2.12在浏览器打开输入URL回车,即可得到聚类结果的10个簇中心在地图上的位置,如下图所示:

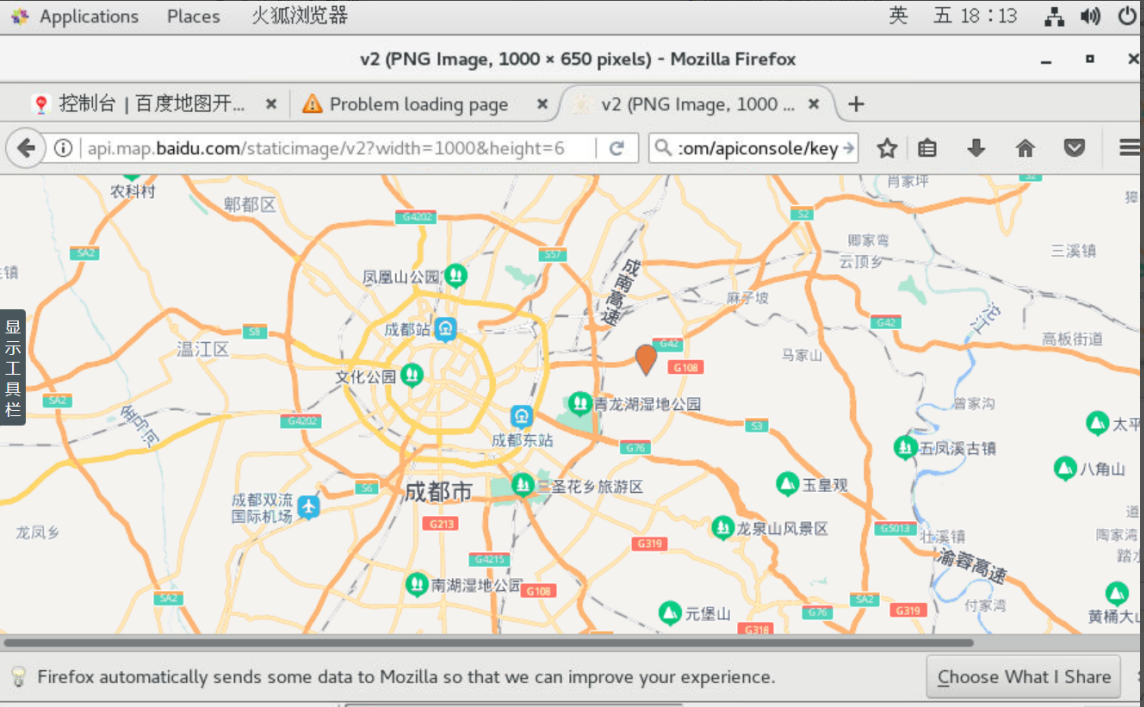
7.2.13针对每天哪个时段的出租车最繁忙和最空闲这一需求,前面我们已经在解决这一问题时保存了在某一时段最繁忙和最空闲的两个区域的经纬度,这里我们将URL的markers参数修改为4号区域的经纬度,并输入在浏览器中,即可知道出租车最繁忙的4号区域地理位置,如下图
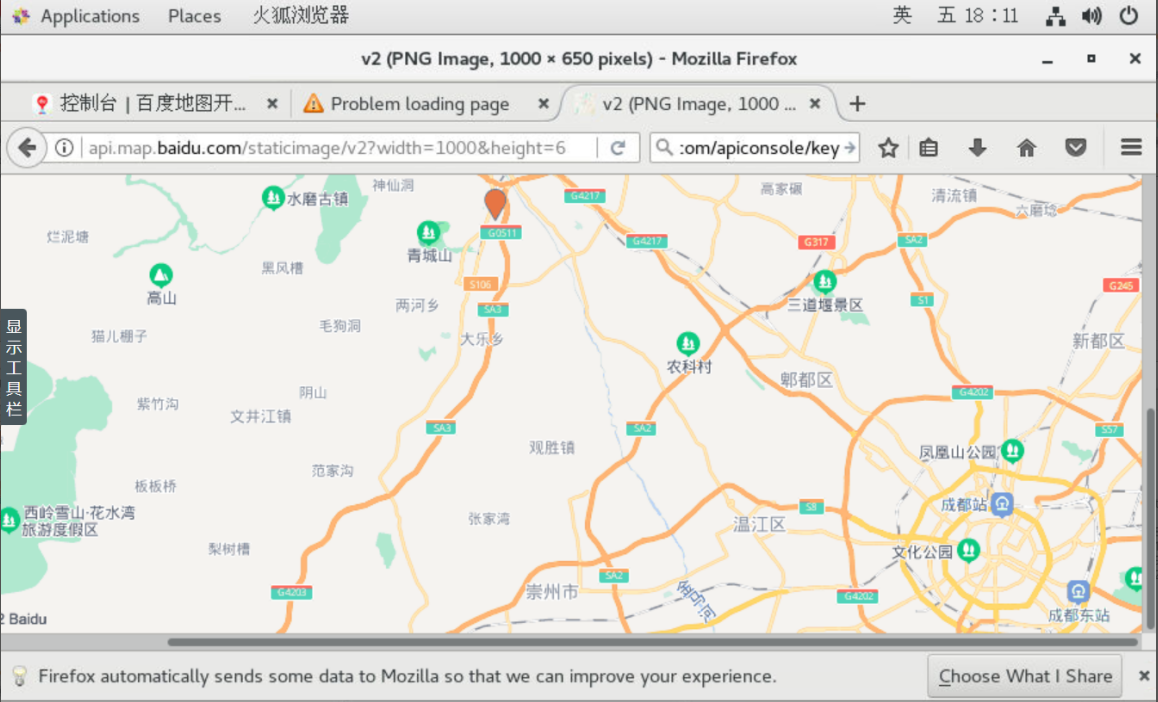
7.2.14这里我们将URL中的markers参数修改为9号区域的经纬度,并输入在浏览器中,即可知道出租车最空闲的9号区域的地理位置,如下图
7.2.15我们还可以通过查询百度地图经纬度,修改center参数和缩放级别达到查看具体地址的效果,这里就不在赘述了
7.3通过绘制柱状图比较不同的数据
7.3.1创建项目:这里我们需要使用提供好的D3.js和其他的javascript脚本文件来构建效果网页
7.3.2创建一个新的文件夹Visualization,并在此文件夹下创建名为data和js的两个文件夹
[zkpk@master kmResult]$ cd
[zkpk@master ~]$ cd taxifx
[zkpk@master taxifx]$ mkdir Visualization
[zkpk@master taxifx]$ cd Visualization
[zkpk@master Visualization]$ mkdir data
[zkpk@master Visualization]$ mkdir js

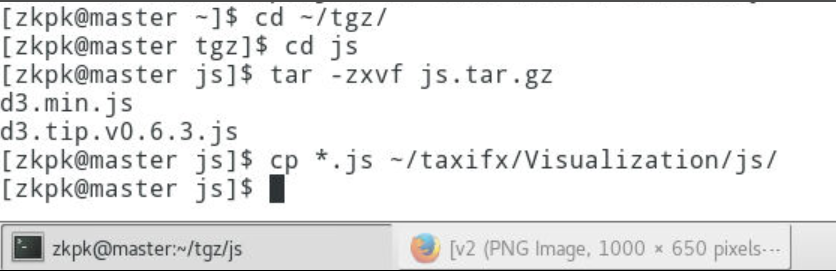
7.3.3解压并拷贝所有的js文件到此js目录中
[zkpk@master Visualization]$ cd ~/tgz/
[zkpk@master tgz]$ tar -zxvf js.tar.gz
[zkpk@master tgz]$ cd js
[zkpk@master js]$ cp *.js ~/taxifx/Visualization/js/
7.3.4将数据聚类分析的结果busyZones合并成单个文件
[zkpk@master js]$ cd
[zkpk@master ~]$ cd taxifx/busyZones
[zkpk@master busyZones]$ cat part-* >> data.csv

7.3.5在csv文件的首行加上字段名称
[zkpk@master busyZones]$ sed -i "1i zone,numOfServices" data.csv
7.3.6将数据文件data.csv拷贝到data文件夹下
[zkpk@master busyZones]$ cp data.csv ~/taxifx/Visualization/data/

7.3.7在Visualization目录下创建编辑index.html文件(如果对html语言不太熟悉,我们也提供了写好的html在/home/zkpk/tgz目录下,直接拷贝到指定位置使用亦可)
[zkpk@master busyZones]$ cd
[zkpk@master ~]$ cd taxifx/Visualization
[zkpk@master Visualization]$ vim index.html

7.3.8在html文件中插入基本的HTML元素

<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Chengdu Taxi Services by Zones</title>
</head>
<body>
</body>
</html>7.3.9因为我们会用到d3.js的相关API来绘图,所以在body中引用相关js文件(js文件已经拷贝到js文件夹下了)
7.3.10在body中填充画布的JavaScript代码(以下代码是包含在一个script标签中)
7.3.10.1script标签开始,设置画布大小和边距

7.3.10.2设置X方向的范围和序数

7.3.10.3设置Y方向的范围

7.3.10.4设置X轴的大小和位置

7.3.10.5设置Y轴的大小和位置
7.3.10.6设置鼠标指针指向矩形时的提示框属性和内容
7.3.10.7设置画布,在body标签内动态添加svg标签,同时设置画布的宽高和边距

7.3.10.8调用显示框组件

7.3.10.9读取data目录下的data.csv文件

7.3.10.10设置x、y方向上要显示的数据

7.3.10.11在画布上绘制x轴

7.3.10.12在画布上绘制y轴,并设置标签和属性

7.3.10.13在画布上绘制矩形满招每项数据占总量的比例来绘制高度,同时为每个矩形设置事件监听器,在鼠标进入和移出当前元素时触发

7.3.10.14定义用于计算数据总量的函数,script标签结束

7.3.11绘制图形结束后,我们需要在head标签中的title标签下方添加style标签,在style标签中添加以下内容,用于美化图形
7.3.11.1style标签开始,设置坐标轴的颜色和边缘属性
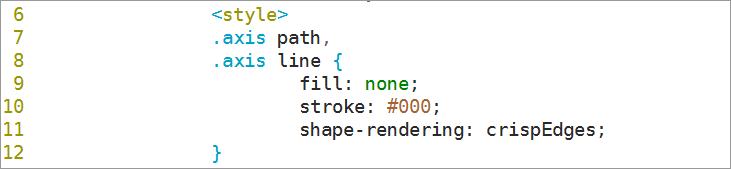
7.3.11.2设置矩形的填充颜色

7.3.11.3设置矩形被选中时的填充颜色

7.3.11.4设置Tip提示框大小、间距、颜色等属性

7.3.11.5在Tip提示框所在的圆角矩形下方添加一个小的三角形并设置它的大小和颜色
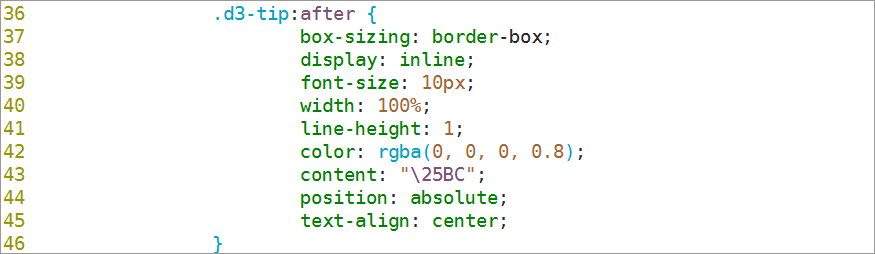
7.3.11.6设置三角形的位置,style标签结束

<!DOCTYPE html>
<!DOCTYPE html>
<meta charset="utf-8">
<style>
/* 设置坐标轴的颜色和边缘属性 */
.axis path,
.axis line {
fill: none;
stroke: #000;
shape-rendering: crispEdges;
}
/* 设置矩形的填充颜色 */
.bar {
fill: #08bf91;
}
/* 设置矩形被选中时的填充颜色 */
.bar:hover {
fill: #003cff;
}
/* 设置 Tip 提示框的大小、间距和颜色等属性 */
.d3-tip {
line-height: 1;
font-weight: bold;
padding: 12px;
background: rgba(0, 0, 0, 0.8);
color: #fff;
border-radius: 2px;
}
/* 在 Tip 提示框所在的圆角矩形下方添加一个小的三角形,并设置它的大小和颜色 */
.d3-tip:after {
box-sizing: border-box;
display: inline;
font-size: 10px;
width: 100%;
line-height: 1;
color: rgba(0, 0, 0, 0.8);
content: "\25BC";
position: absolute;
text-align: center;
}
/* 单独设置三角形的位置 */
.d3-tip.n:after {
margin: -1px 0 0 0;
top: 100%;
left: 0;
}
</style>
<body>
<script src="js/d3.min.js"></script>
<script src="js/d3.tip.v0.6.3.js"></script>
<script>
// 设置画布大小和边距
var margin = {top: 40, right: 20, bottom: 30, left: 100},
width = 960 - margin.left - margin.right,
height = 500 - margin.top - margin.bottom;
// 设置 X 方向的范围和序数
var x = d3.scale.ordinal()
.rangeRoundBands([0, width], .1);
// 设置 Y 方向的范围
var y = d3.scale.linear()
.range([height, 0]);
// 设置 X 轴的大小和位置
var xAxis = d3.svg.axis()
.scale(x)
.orient("bottom");
// 设置 Y 轴的大小和位置
var yAxis = d3.svg.axis()
.scale(y)
.orient("left")
.tickFormat(d3.format("1"));
// 设置鼠标指向矩形时显示的提示框组件的属性、文字位置偏移量和文字内容
var tip = d3.tip()
.attr('class', 'd3-tip')
.offset([-10, 0])
.html(function(d) {
return "<strong>Services:</strong> <span style='color:red'>" + d.numOfServices + "</span>";
})
/*
* 设置画布,在 body 标签内动态添加 svg 标签
* 同时设置画布的宽高和边距
*/
var svg = d3.select("body").append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform", "translate(" + margin.left + "," + margin.top + ")");
// 调用提示框组件
svg.call(tip);
// 读取 data 目录下的 data.csv 文件
d3.csv("data/data.csv", type, function(error, data) {
// 设置 X、Y 方向上要显示的数据
x.domain(data.map(function(d) { return d.zone; }));
y.domain([0, d3.max(data, function(d) { return d.numOfServices; })]);
// 在画布上绘制 X 轴
svg.append("g")
.attr("class", "x axis")
.attr("transform", "translate(0," + height + ")")
.call(xAxis);
// 在画布上绘制 Y 轴,设置轴标签及属性
svg.append("g")
.attr("class", "y axis")
.call(yAxis)
.append("text")
.attr("transform", "rotate(-90)")
.attr("y", 6)
.attr("dy", ".71em")
.style("text-anchor", "end")
.text("Number Of Services");
// 在画布上绘制矩形,按照每项数据占总量的比例来绘制高度
// 为每个矩形设置事件监听器,在鼠标进入和移出当前元素时触发
svg.selectAll(".bar")
.data(data)
.enter().append("rect")
.attr("class", "bar")
.attr("x", function(d) { return x(d.zone); })
.attr("width", x.rangeBand())
.attr("y", function(d) { return y(d.numOfServices); })
.attr("height", function(d) { return height - y(d.numOfServices); })
.on('mouseover', tip.show)
.on('mouseout', tip.hide)
});
// 用于计算数据总量的函数
function type(d) {
d.numOfServices =+ d.numOfServices;
return d;
}
</script>
7.3.12页面编辑完成之后利用:wq保存并退出,然后在浏览器中打开文件URL,查看可视化结果

相关文章
- HDFS读文件过程分析:读取文件的Block数据
- 新闻发布项目——数据实现类(commentDaoImpl)
- 在JSP页面中输出JSON格式数据
- EntityFramework数据持久化 Linq介绍
- 第二十节,基本数据类型,集合set、综合应用新数据更新老数据
- 大数据项目失败的原因分析
- 分析了10个垂直行业后,告诉你大数据应用面临哪些挑战
- vue框架,数据展示和分析,报告管理界面
- R语言实现金融数据的时间序列分析及建模
- Python数据挖掘之决策树DTC数据分析及鸢尾数据集分析
- 没有基础,如何成为数据分析师?
- SAP Cloud for Customer(C4C)前台显示的数据是如何从后台读取的
- Python之pandas:将dataframe数据写入到xls表格的多个sheet内(防止写入数据循环覆盖sheet表)
- 数据挖掘工具分析北京房价 (一) 数据爬取采集
- 【成为架构师课程系列】大数据技术体系精华总结【值得收藏!】
- SpringBoot学习笔记(6) SpringBoot数据缓存Cache [Guava和Redis实现]
- LabVIEW编程LabVIEW开发高级数据采集技术 计数器定时器的操作 例程与相关资料
- 【SQL开发实战技巧】系列(二十三):数仓报表场景☞ 如何对数据排列组合去重以及通过如何找到包含最大值和最小值的记录这个问题再次用执行计划给你证明分析函数性能不一定高
- 基于sklearn随机森林算法对鸢尾花数据进行分类
- 多传感器时频信号处理:多通道非平稳数据的分析工具(Matlab代码实现)
- 初识Hadoop,轻松应对海量数据存储与分析所带来的挑战
- Docker 数据迁移
- 【大数据开发运维解决方案】sqoop避免输入密码自动增量job脚本介绍
- 自动驾驶数据采集和分析平台--ADAS Logger