
【Transformer】6、Twins:Revisiting the Design of Spatial Attention in Vision Transformers

代码: https://github.com/Meituan-AutoML/Twins
一、背景
最近以来,Transformer 取得了很大的关注,相比 CNN 而言,Transformer 有更强的捕获 long-range dependencies 的能力,且可以处理文本、语音、图像等任务。
虽然Transformer效果也挺好的,但其由于spatial self-attention 而导致的高计算量一直是个问题,其计算量是输入图像大小的二次方。
Transformer最初被应用在视觉领域的分类任务上,如VIT和DeiT,取得了较好的效果。
但对于密集预测任务(检测/分割)来说,需要大分辨率的输入+金字塔特征图,这大大增加了Transformer的计算复杂度,计算复杂度很大程度上源于self-attention。
二、动机
应对上述大计算量问题有以下方法:
- 使用 locally-grouped self-attention,即将图像分块,在图像块内部做self-attention。这种方法虽然可以降低计算量,但是局部图像块之间缺乏了相互感知,违背了大感受野的初衷。
- Swin 提出了一个 shifted window 的操作来应对上述问题,也就是windows的边界会移动,不会永远在同一个地方。但这样也会导致另外一个问题,就是这些windows大小不一,会导致使用现有深度学习框架有困难。
- PVT为上述问题提出了解决方案,PVT中,每个query不和所有输入都做attention,而是只和一部分做attention。
本文和上述几种方法一样,从降低计算量的角度出发,也就是从设计一个更高效的 spatial self-attention角度出发,来设计网络。
结构一:Twins-PCPVT
结构二:Twins-SVT
三、方法
3.1 Twins-PCPVT
PVT引入金字塔多级设计来很好的应对稠密估计任务,如目标检测和语义分割,但 PVT 比 Swin-Transformer 的效果略低,作者发现导致效果略低的原因应该就在于 PVT 的 ”绝对位置编码” 方法。因为分类任务和稠密预测任务有很大的不同,尤其在训练阶段,分类任务只需要处理输入大小固定的图片,而检测等任务的输入大小是不同的,提前设定好的绝对位置编码难以处理不同输入大小,而且会破坏平移不变性。
但 Swin-Transformer 使用了相对位置编码,会克服上述困难。
于是作者就使用了CPVT[9] 中提出的 conditional position encoding (CPE),克服了上述困难,在分类和其他任务上都取得了性能提升,可以媲美 Swin-Transformer,由于条件位置编码 CPE 支持输入可变长度,使得 Transformer 能够灵活处理不同尺度的输入。
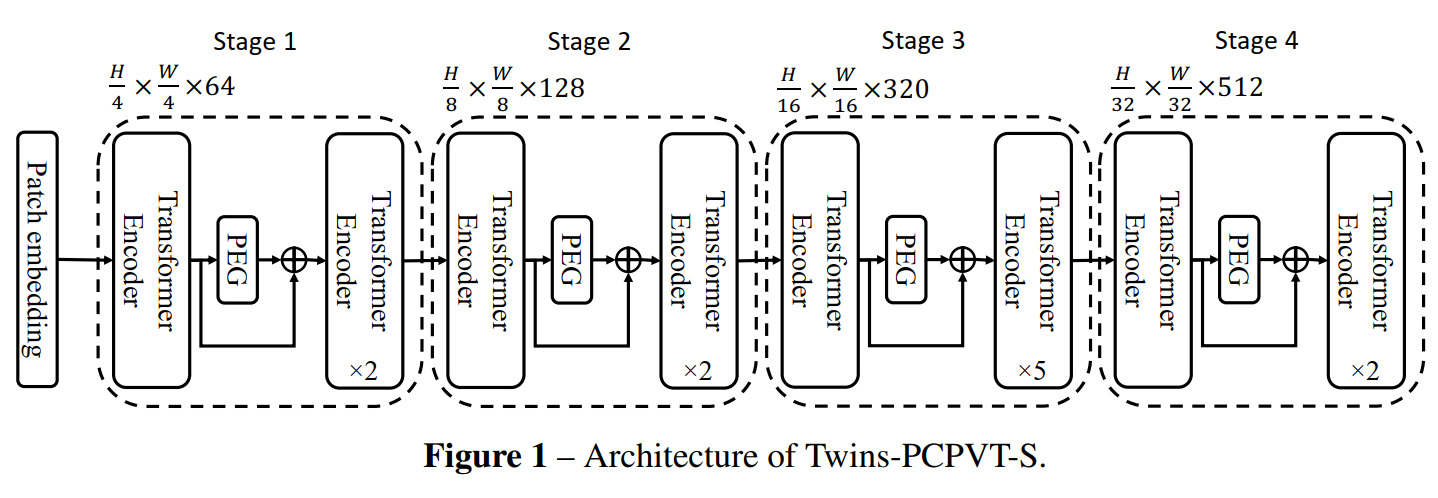
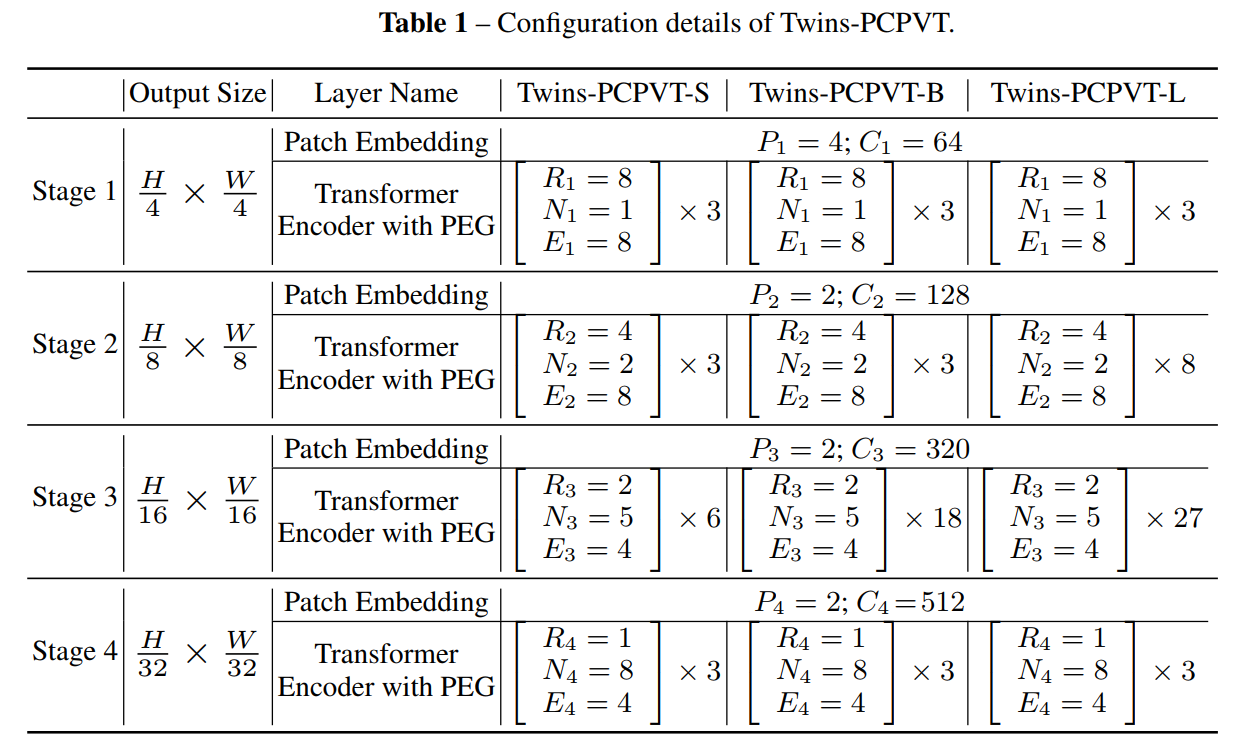
3.2 Twins-SVT
由于Transformer面临的最大问题就是稠密预测导致的大计算量,所以作者提出了 spatially separable self-attention(SSSA),也叫空间可分离注意力,也就是对特征的空间维度进行分组计算各组的注意力,然后再从全局对分组注意力结果进行融合,SSSA 由两部分组成:
- locally-grouped self-attention (LSA)
- global sub-sampled attention (GSA)
SSSA 使用局部-全局注意力交替的机制,可以大幅降低计算量。
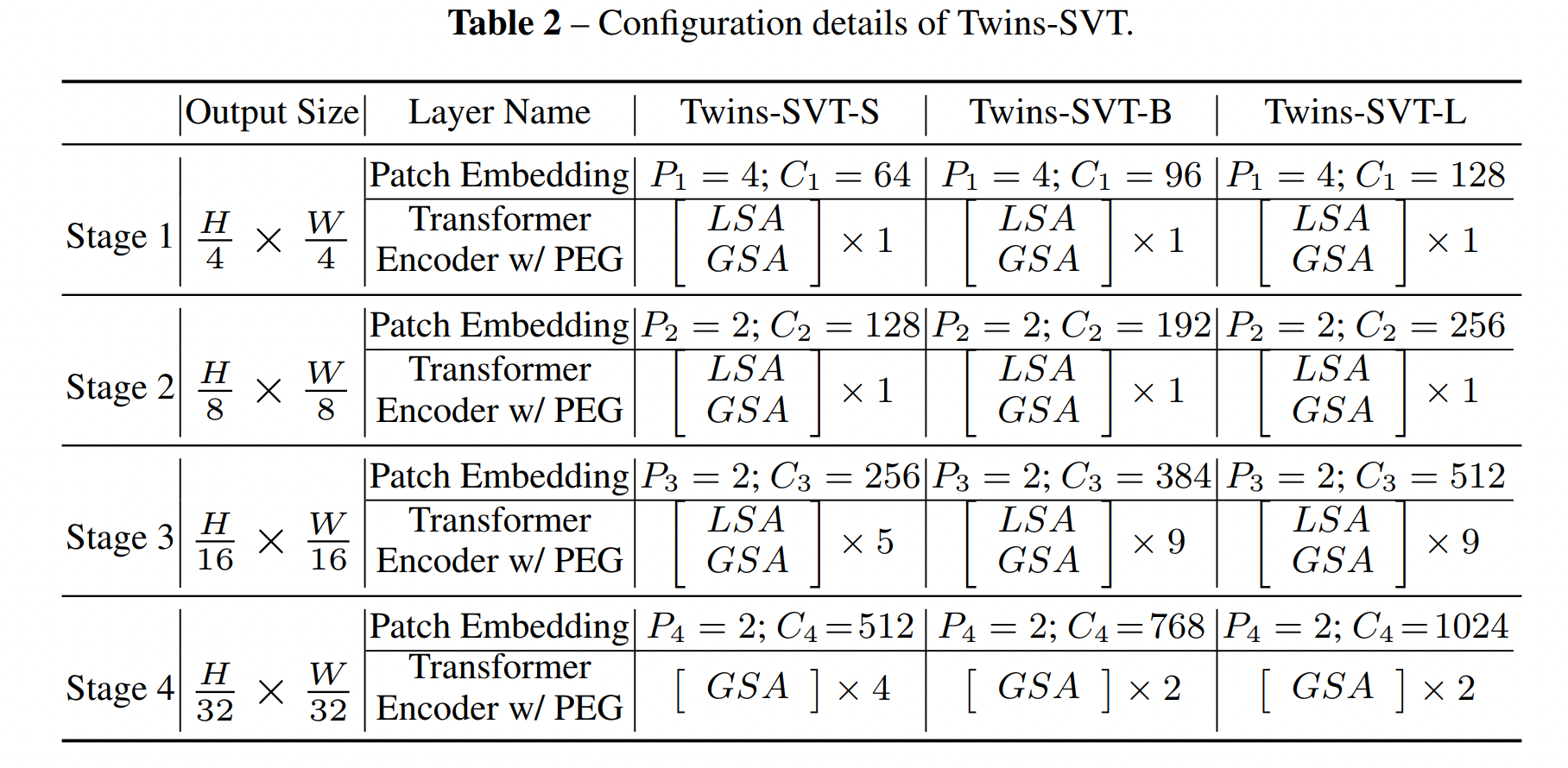
3.2.1 LSA
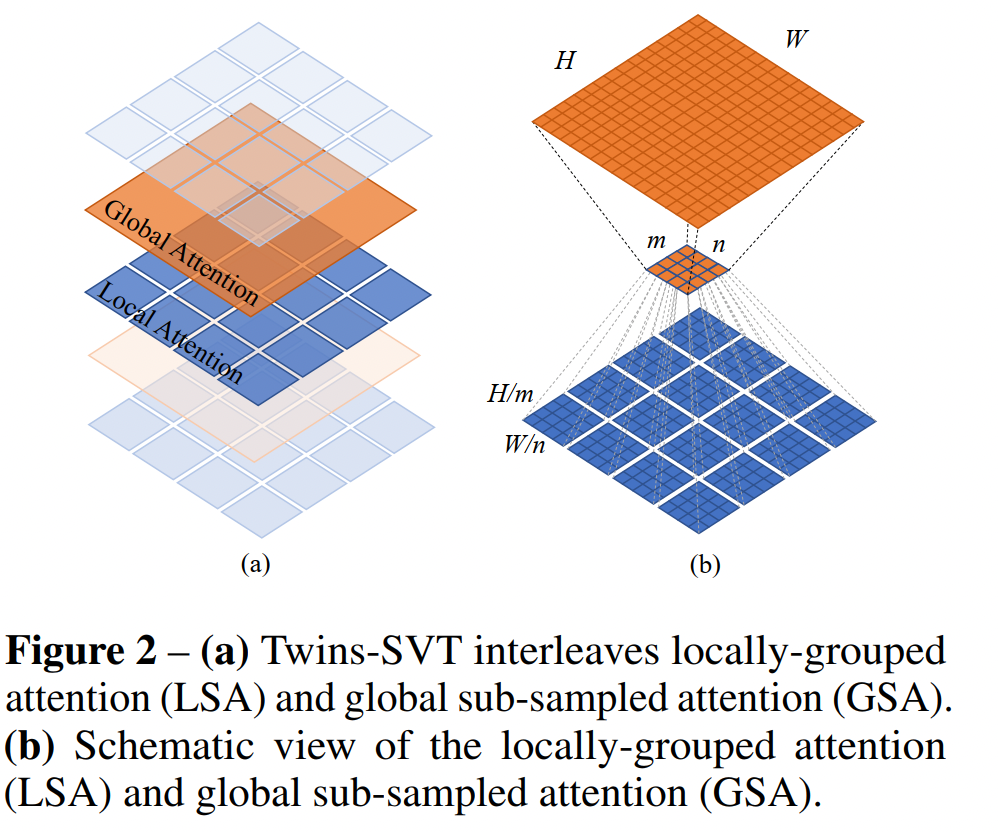
为了提高推理效率,作者将特征图划分为 m × n m \times n m×n 个 sub-windows, k 1 = H m , k 2 = W n k_1=\frac{H}{m}, k_2=\frac{W}{n} k1=mH,k2=nW,大大降低了计算量,但考虑到 sub-windows 间没有进行通讯,所以会像 swin-transformer 那样使用子块间能进行通讯的方式。这也从另外一个角度证明了在CNN中,不能全部使用深度可分离卷积来替代所有的标准卷积。

3.2.2 GSA
考虑到对不同子块进行交互,最简单的解决方式就是在每层 local attention block 后面,添加一个额外的标准全局self-attention层,作者用实验证明了这种操作能够提升,但计算量很大,为 O ( H 2 W 2 d ) O(H^2W^2d) O(H2W2d)。
改进:如果使用一个有代表性的值来代表每个 sub-windows,那么全局 attention 的计算量就为 O ( H 2 W 2 d k 1 k 2 ) O(\frac{H^2W^2d}{k_1k_2}) O(k1k2H2W2d),这也就是相当于将其作为self-attention 中的 key,所以称为 global sub-sampled attention。为了保持通用性,一般 k 1 = k 2 k_1=k_2 k1=k2,作者设定 stage1 的特征图大小为 56 × 56 56 \times 56 56×56,故 k 1 = k 2 = 56 = 7 k_1=k_2=\sqrt{56}=7 k1=k2=56=7
下采样方式的选择:从平均池化、depth-wise convolution、常规 convolution中选择,实验发现常规的卷积效果是最好的。
Transformer block 的形式表达:

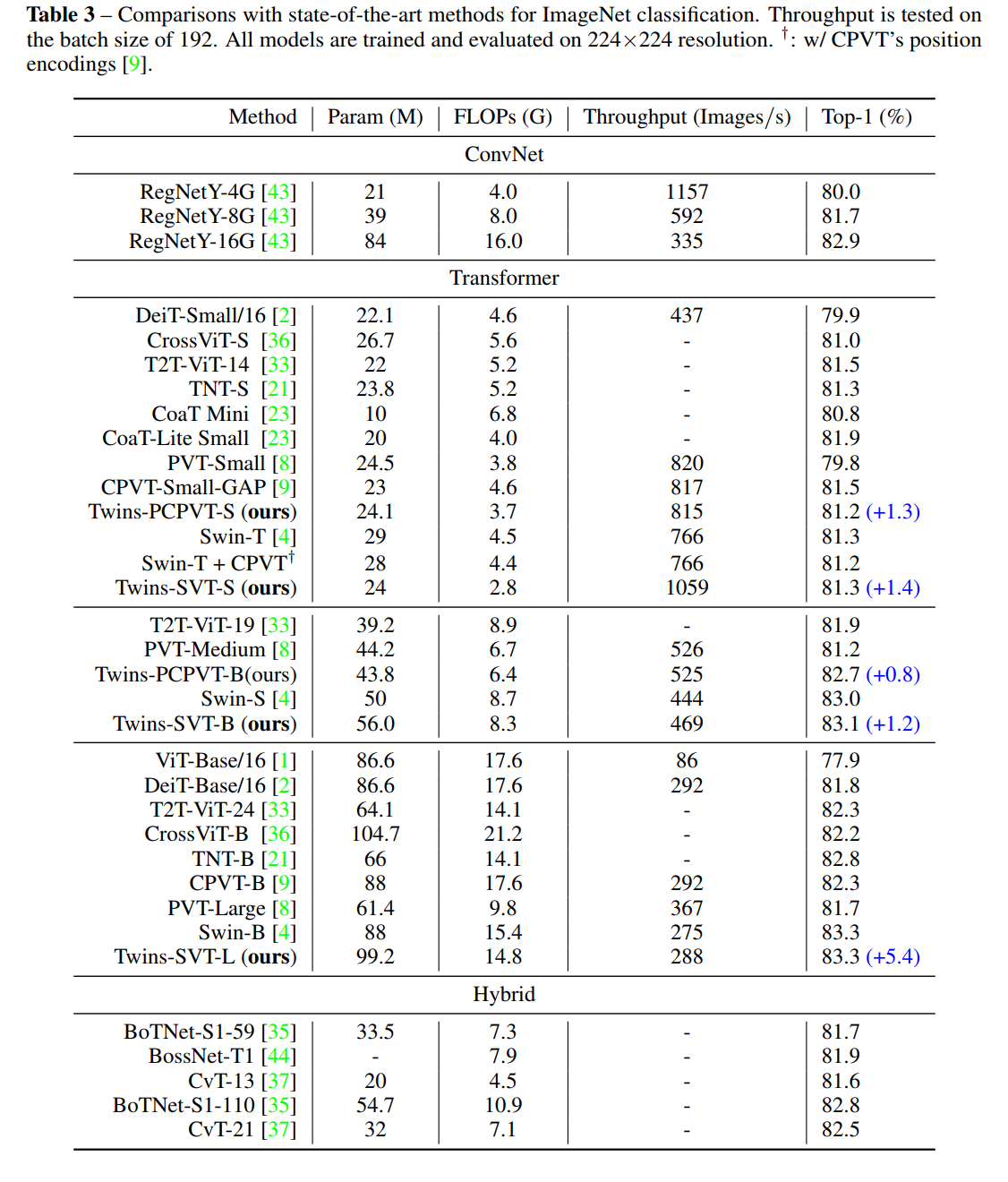
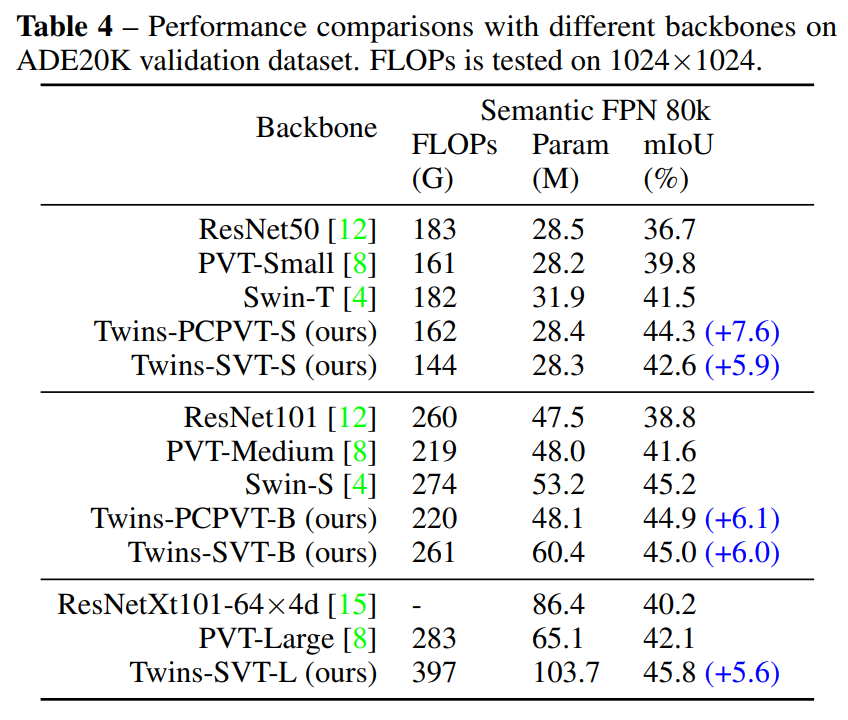
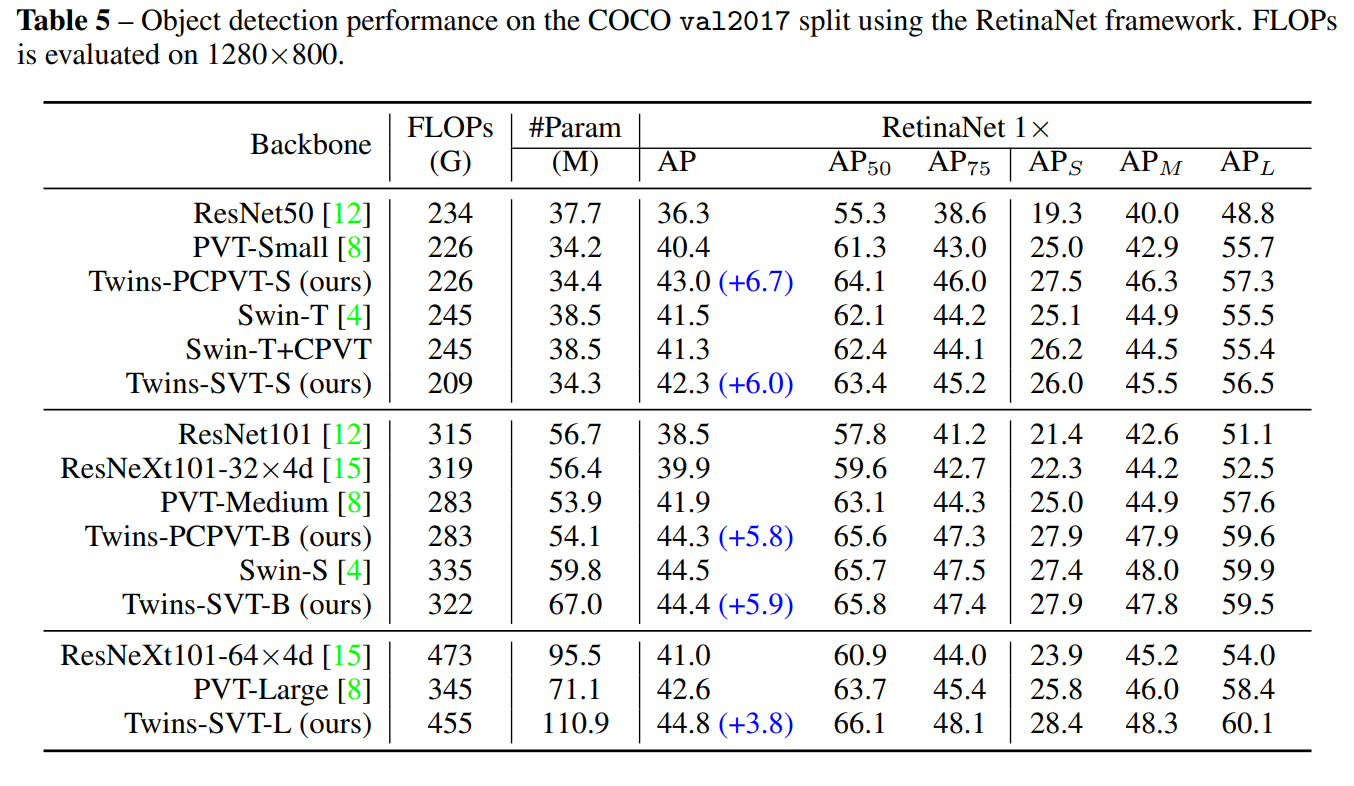
四、实验
相关文章
- 创龙OMAPL138开发板测试Device is held in reset. Take the device out of reset, and retry the operation.
- Eclipse和Maven的结合使用--Please make sure the -vm option in eclipse.ini
- [Typescript] Use the Nullish Coalescing Operator in TypeScript (isNil)
- [TypeScript] Deeply mark all the properties of a type as read-only in TypeScript
- [Typescript] Installing Promise Type Definitions Using the lib Built-In Types
- Android开发 Error:The number of method references in a .dex file cannot exceed 64K.Android开发 Error:The number of method references in a .dex file cannot exceed 64K
- [React] Handle Deep Object Comparison in React's useEffect hook with the useRef Hook
- [Tools] Create Files in the Terminal from the Clipboard with PBPaste
- 已解决:initialize specified but the data directory has files in it. Aborting
- The size of tensor a (4) must match the size of tensor b (3) at non-singleton dimension 0
- Sqlachemy的警告SAWarning: The IN-predicate on "sns_object.BIZ_ID" was invoked with an empty sequence. This results in a contradiction, which nonetheless can be expensive to evaluate.
- Which of the following can’t be used in memset?(多选)
- 【成为架构师课程系列】使用 Cache-Aside 模式将数据存储在缓存中( Using the Cache-Aside pattern to store data in the cache)
- The encryption certificate of the relying party trust identified by thumbprint is not valid
- Eclipse集成Maven打包时报错:[ERROR] Unknown lifecycle phase "mvn". You must specify a valid lifecycle phase or a goal in the format
- 论文解读《Research on the application of contrastive learning in multi-label text classification》
- 问题解决:The connection to the server xxxxx:6443 was refused - did you specify the right host or port?
- java.lang.IllegalStateException: The specified child already has a parent. You must call removeView() on the child's parent first.
- 【2023年4月美赛加赛】Z题:The Future of the Olympics 思路、建模方案、数据来源、相关资料
- 论文阅读《The Funny Thing About Incongruity: A Computational Model of Humor in Puns》
- Sentinel采用SphO方式定义资源,报错:The order of entry exit can‘t be paired with the order of entry