
《Attention is all you need》论文学习
1.Transformer结构
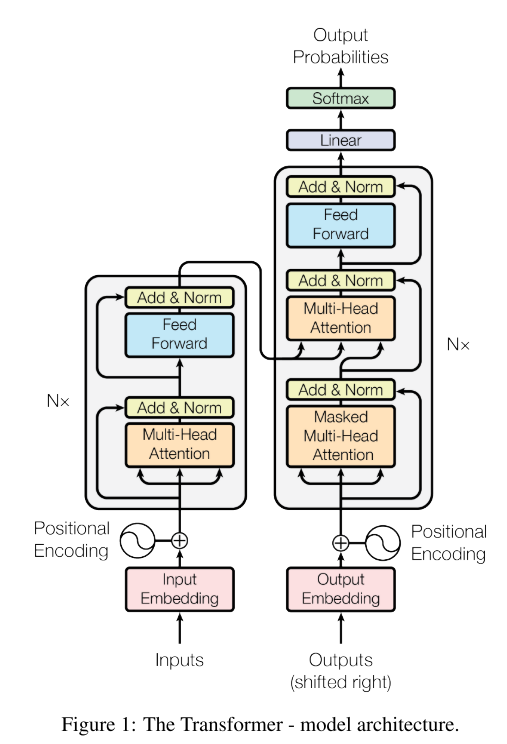
//这里为什么有两个output??什么意思?已经完全看不懂了。。
Transformer使用栈式自注意力机制,编码器和解码器的逐点完全连接层。
https://www.jianshu.com/p/e7d8caa13b21,这篇有讲到,Encoder的输出可以变换为注意力矩阵K和V,然后在解码的时候当然也要输入之前的输出?
但是比如说下面是用来翻译的,previous outputs那个I是从哪里来的?我就可能对机器翻译这个整个的过程都不懂啊!
下面的过程就是说,decoder的时候这个I am ... 什么的怎么就出来了???从哪里来的?
怎么产生预测的下一个单词的output呢?
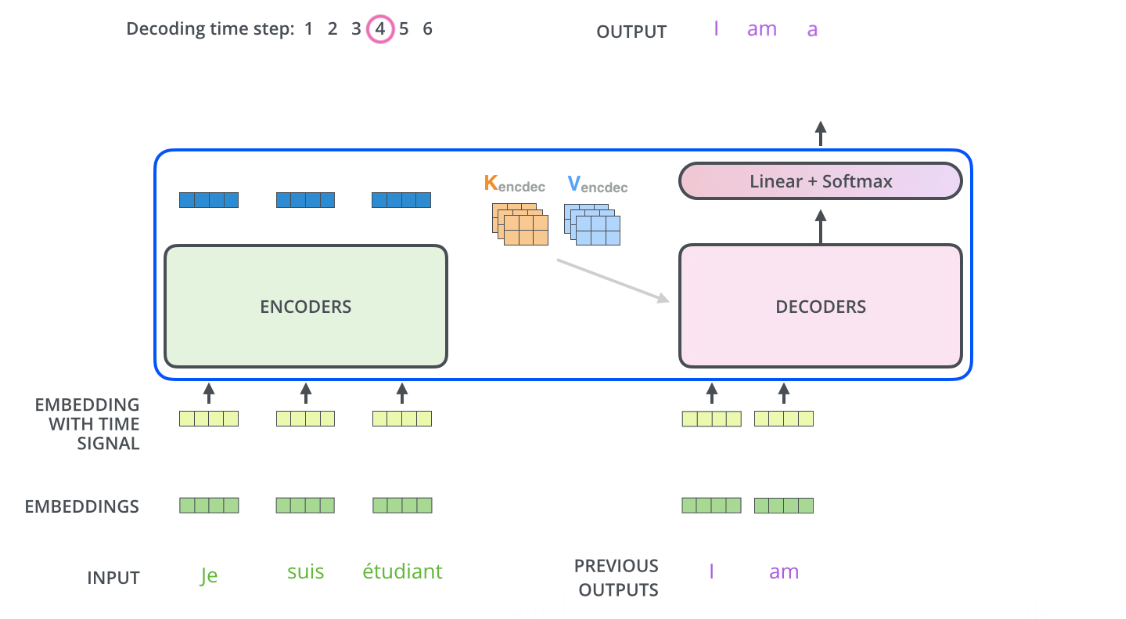
反正我还是看不太懂它的整个过程。我还是慢慢来看懂吧。
2.位置编码positional encodings
https://www.zhihu.com/question/347678607/answer/835053468,为什么引入位置编码?

但是上面的什么attention 映射我还不懂,需要之后学到再回来理解一下。
在bert中需要输入的三个参数为,input id,padding,segment,第一个就是序列token,第二个1表示有单词,0表示是pad补齐的, segment表示是a句还是b句。
其实这上面三个是没有看到位置编码出现在哪里的,应该是在forward的时候处理的,需要看源码实现。
https://zhuanlan.zhihu.com/p/48508221
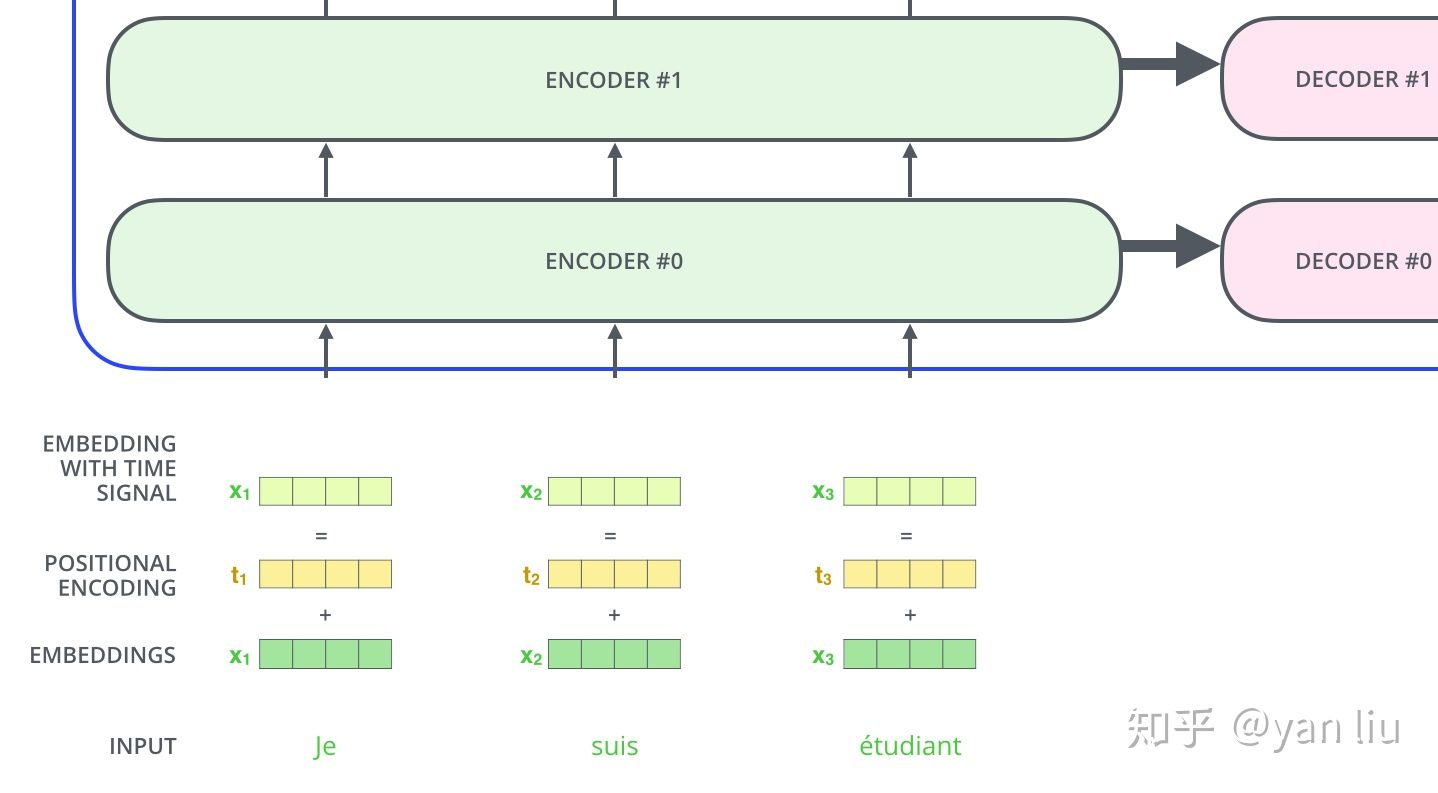
//上图是不是有问题?怎么每层的encoder都会输入到decoder呢?不是只有最后一层吗?
可以看到,嵌入向量和位置编码连接concat形成了最终的有 时间信号的嵌入。公式是这样的:
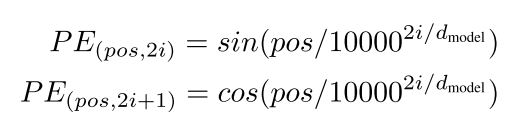
其中i是单词维度,dmodel是位置编码的维度,pos是单词的位置。那我就很迷惑了,针对一个单词它获取到的不就是一个标量值吗?何来位置向量呢?
https://blog.csdn.net/Flying_sfeng/article/details/100996524
https://zhuanlan.zhihu.com/p/57732839
经过上面的这两个我终于看明白了,首先源码:
class PositionalEncoding(nn.Module): "Implement the PE function." def __init__(self, d_model, dropout, max_len=5000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) # Compute the positional encodings once in log space. pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len).unsqueeze(1)#它是对应每一个word的 div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))#即pos/下面的项 pe[:, 0::2] = torch.sin(position * div_term)#对于每一个word偶位置的词向量的位置编码 pe[:, 1::2] = torch.cos(position * div_term)#奇位置的 pe = pe.unsqueeze(0) self.register_buffer('pe', pe) def forward(self, x): x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) return self.dropout(x)
div_term通过这个计算:
![]()
那么在公式中,pos指的是word的位置,i是一个emb_dim/2的长度的向量,在这里emb_dim与d_model维度要求是一样的,因为之后要进行相加操作。
举例,假如pos=3,d_model=128,那么当前word的位置编码向量为:
![]()
这样的话词向量能够结合位置信息了。sin和cos函数值域是[-1,1],从下面这张图可以看到位置编码向量的大约表示。

而且根据公式:![]() ,
,![]() ,K+P位置的单词的位置信息可以表示为K和P位置的线性组合,就从而能够比较方便地获取到单词之间的相对位置关系。
,K+P位置的单词的位置信息可以表示为K和P位置的线性组合,就从而能够比较方便地获取到单词之间的相对位置关系。
3.位置编码和三角函数有何关系?
https://www.zhihu.com/question/347678607,这个问题正是我要提问的。
我目前的一个想法是除以了10000的幂次之后,使得能够表示的总句子长度增加,根据三角函数曲线的特性,在(0,2pi)范围内值域是不重复的,这个就可以用来很好地表示位置信息。
//这个回答我没有仔细看,但是稍微看了一下跟我想的类似。
4.具体的计算过程
为什么能够并行运算呢?
https://zhuanlan.zhihu.com/p/44731789,这个讲的十分详细,让我对self-att的结构有了深入理解:
1.多头注意力是将原本词向量大小的QKV切分为等大小的?
我的理解是,它和词向量很有关系,切分了部分,就只是词向量局部和词向量局部去比较?这里不太明白。
https://www.zhihu.com/question/350369171
“
作者:徐啸
链接:https://www.zhihu.com/question/350369171/answer/860552006
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
”
计算难度下降,从不同的子空间当中都获取到信息。
2.layer normalization层归一化
专门写一篇进行学习
3. shifted right右移一位 如何实现的?
4.encoder/decoder钟qkv到底是如何输出?
谁输入谁?谁和谁一样?
encoder的时候三者来源都是相同的。
5.residual connection
6.为什么要有qkv呢?
//只有q和v不行吗?为啥还要多个key呢?
7.为何要将词向量放大?
https://www.zhihu.com/question/356184149
因为位置编码中式正弦曲线,之后加和,词向量又Xavier初始化的,它的范围比较小,扩大后能够增大词向量的权重和影响。
//其实这个不是特别重要吧?还是理解模型更重要!
5.源码阅读
6.中翻译为英例子
https://zhuanlan.zhihu.com/p/62397974,这个讲的真的不错!

//一开始词向量随机初始化,是因为原来的单词是没有联系上下文的,所以差别不大,之后就在学习中学习到了上下文的语义表示。
encoder中的qkv来源是一样的,那么输出的z到底是什么呢?它的shape和输入的是一样的,难道这个z就表示每个词和其他词的相关度吗?但是它还是512维的,难道说前64维表示和其他的?又64维表示和另几个单词的?我无法理解,图转自:https://zhuanlan.zhihu.com/p/44731789。

1.z最终表示的是什么意思?
如何从z的内容上理解它的含义?
在解码过程中:
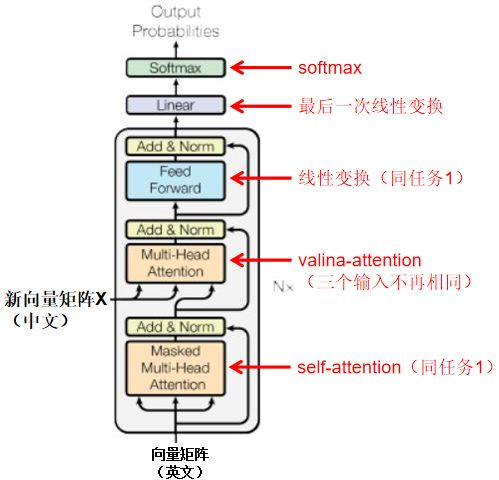
可以看到它也有self-att的过程,qk是来自编码的输出,qk应该就直接是encoder的输出,是一样的,然后经过不同的全连接层。
v是英文的,然后softmax输出长度为英文词表长度?
//我不太明白的是,源和目标语言长度不一定相同,那这个是如何控制的呢?应该就是下一次单词预测为了一些结束符号吧!
相关文章
- 有了这个机器学习画图神器,论文、博客都可以事半功倍了!
- 干货 | YOLOv7目标检测论文解读与推理演示
- [AI安全论文] 19.USENIXSec21 DeepReflect:通过二进制重构发现恶意行为(经典)
- 可信联邦学习线上分享:杨强教授带领四篇论文解读最前沿研究
- GoogLeNet论文学习笔记
- IJCV收录!深度去模糊综述论文来了
- python+windows画图工具--复现别人论文中的colormap
- word文档页码不连续编号怎么办_怎样给论文加页码
- CVPR 2023放榜,录用率25.78%!2360篇论文被接收,提交量暴涨至9155篇
- 论文/代码速递2022.12.1!
- PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]
- [JCIM | 论文简读] 图神经网络预测亲核性
- [Genome Biology | 论文简读] 通过解释深度学习模型识别癌症的常见转录组特征
- [CVPR | 论文简读] 基于双交叉注意学习的细粒度视觉分类和对象再识别
- [IJCAI | 论文简读] 利用图对比学习增强数据推荐
- [Bioinformatics | 论文解读] 基于生成对抗网络的单细胞半监督注释和降维框架
- [Nature Communications | 论文简读] 使用弱监督深度学习进行准确的体细胞变异检测
- [Nature Biomedical Engineering | 论文简读] 通过深度学习检测眼部照片中的疾病迹象
- [Nature Communications | 论文简读] 通过多视图图协同学习从空间分辨的转录组学数据中阐明肿瘤异质性
- [Nat. Mach. Intell. | 论文简读] 对比学习可以快速映射到数百万规模的多模态单细胞图谱
- [JCIM | 论文简读] 用于检测β-内酰胺酶-抑制剂相互作用的可转移多通道模型
- [NC | 论文简读] devCellPy是一个机器学习支持的管道,用于自动注释复杂的多层单细胞转录组数据
- [arxiv | 论文简读] CLASSIC: 方面级情感分类任务的持续和对比学习
- [Nature Machine Intelligence | 论文简读]三种类型的增量学习
- [Nature Communications | 论文简读] 用于人工神经网络持续学习的大脑启发回放
- 【重磅最新】ICLR2023顶会376篇深度强化学习论文得分出炉(376/4753,占比8%)
- 百岁汇编语言之母逝世!71岁时她还在和儿子合写神经网络论文
- 寒假干点啥?看懂这25个核心概念,就没有啃不动的机器学习论文
- 学术科研无从下手?27 条机器学习避坑指南,让你的论文发表少走弯路
- 机器学习嵌入物理知识成为「时尚」,MIT讲师解读Nature子刊综述论文
- ICLR 2021杰出论文公布:清华、上财校友一作获奖
- Oracle 云计算技术的研究与应用(oracle 云 论文)