
tensor2tensor-transformer源码学习
1.多头注意力
多头注意力,我们可以看到源码中是进行了切割,从return的shape可以看出来。
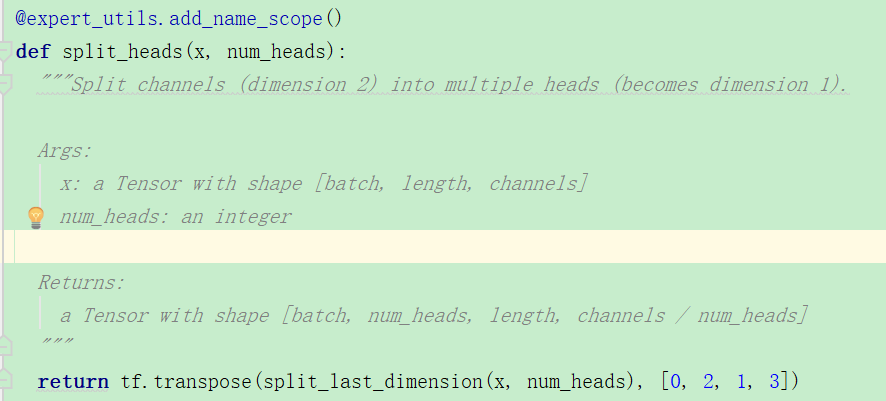
2.transformer编码部分
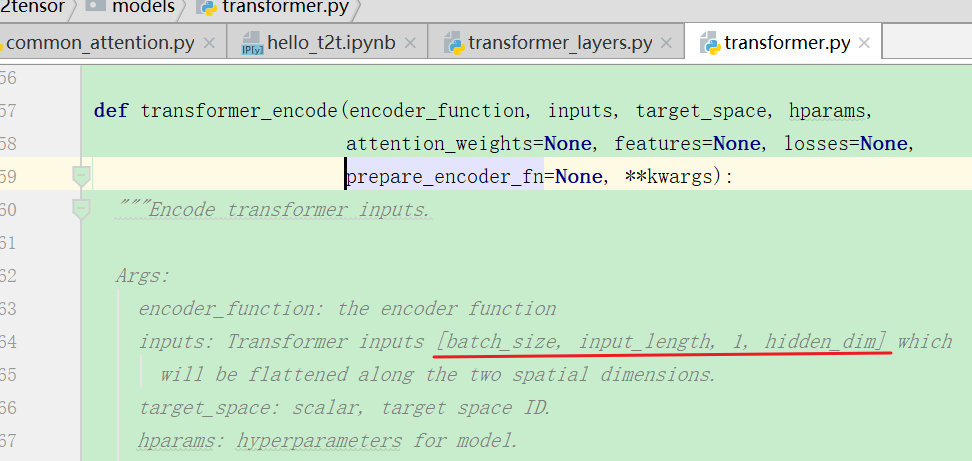
可以看到它的输入就是经过emb和位置编码求和之后的输入。下面是正式使用到的编码函数:
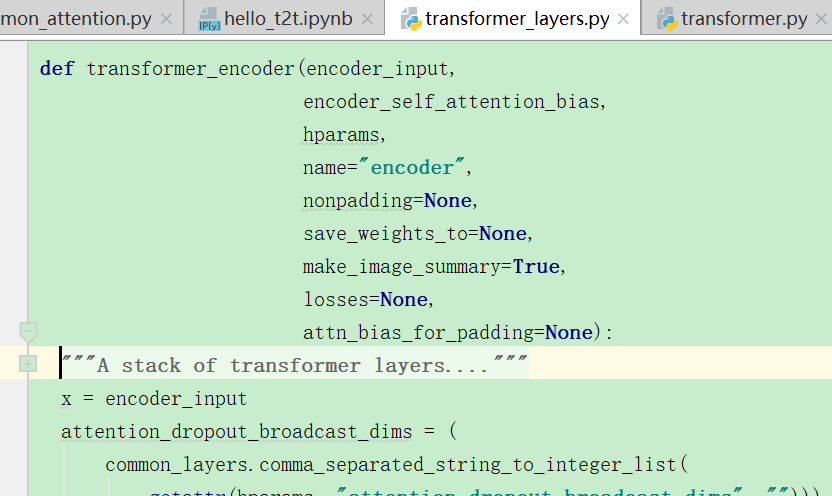
上面的编码函数中,主要调用还是多头注意力这个函数:
调用的语句:

//注意,这里每次调用的时候第二个参数,也就是memory都是None,也就是query=momery。
可以看到下面的query_antecedent就是经过预处理之后的输入,memory一开始是为None的。
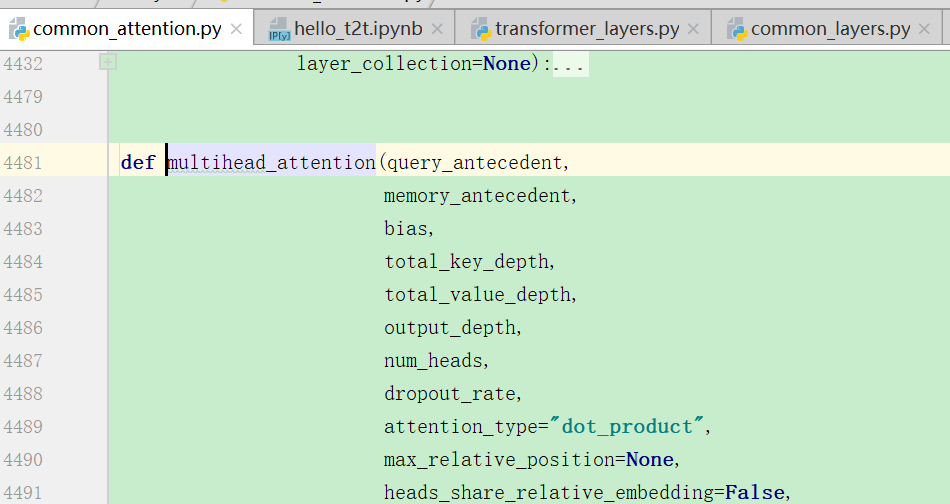
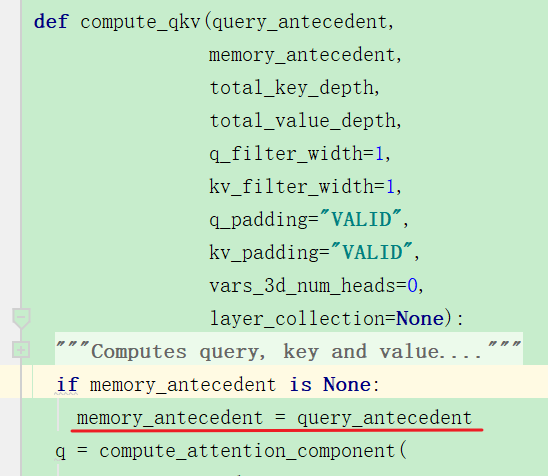
进入上面的函数后,因为一开始的时候memory是None,那么就调用计算qkv的函数:

首先是对Q的计算:

在compute_attention_component函数中,看起来这个过程也非常地简单,就是之前输入的变换*一个var(服从正态分布的随机取样的矩阵),Q=pre_process(input)*var
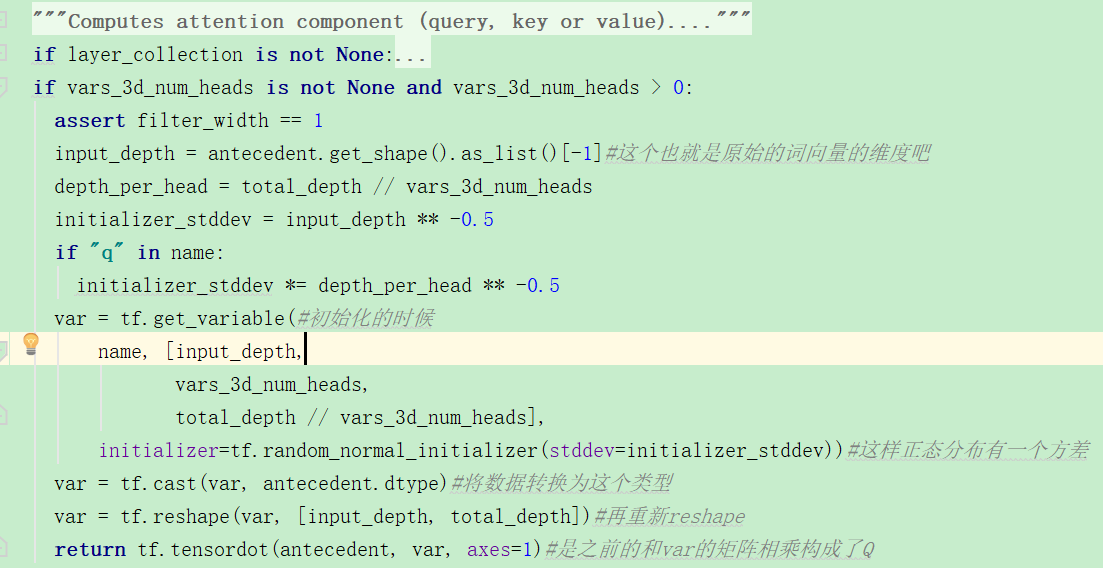
计算KV也是调用同样的函数,但是所用的ante不同,kv需要的是memory,但是此时因为memory是None,

compute一开始将query赋值给了memory:
然后把qkv切成了8个部分进行之后的

下面进行attention操作:

具体的公式操作的部分标注出来:
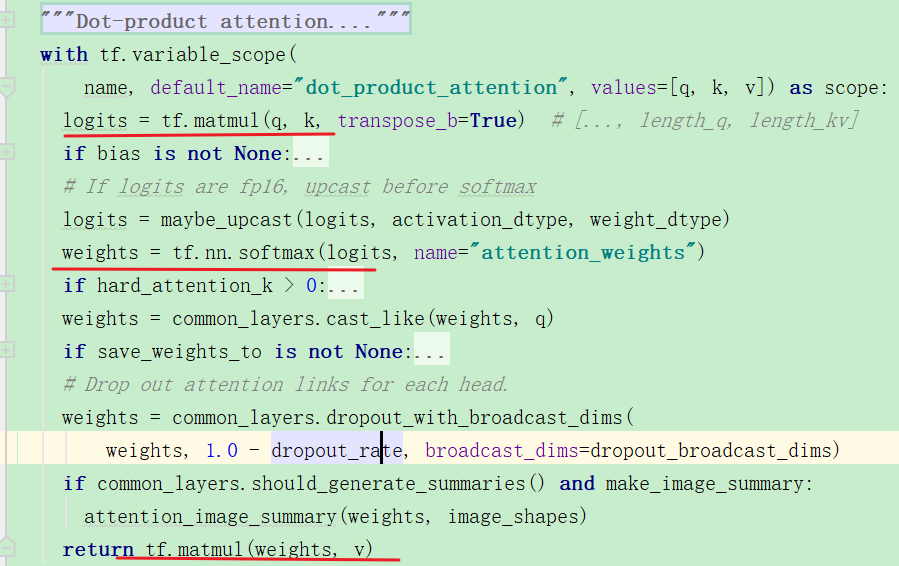
上面计算完attention之后,又有了一个o:

但是我不太明白这个o是干嘛用的,也许它只是用来做一个变换。
在transformer_layers.py文件中,在调用了common_attention.multihead_attention:
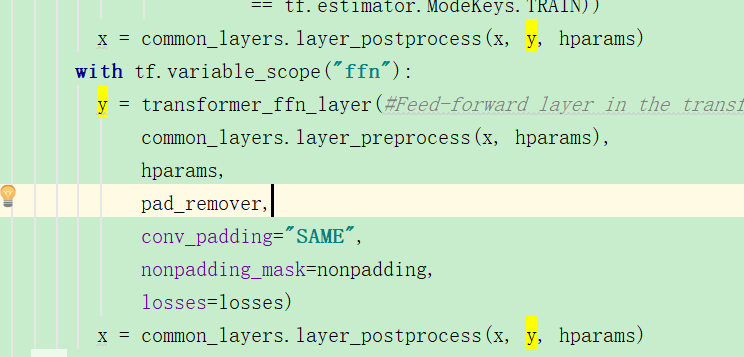
可以看到返回y之后,然后进行了后处理得到x,之后又进行了全连接层,之后又后处理,然后有一个for循环,共有几层,encoder应该是6层,那么就是6次循环了。这样就获取到了encoder的输出:

之后就返回到了这里?encoder输出结果。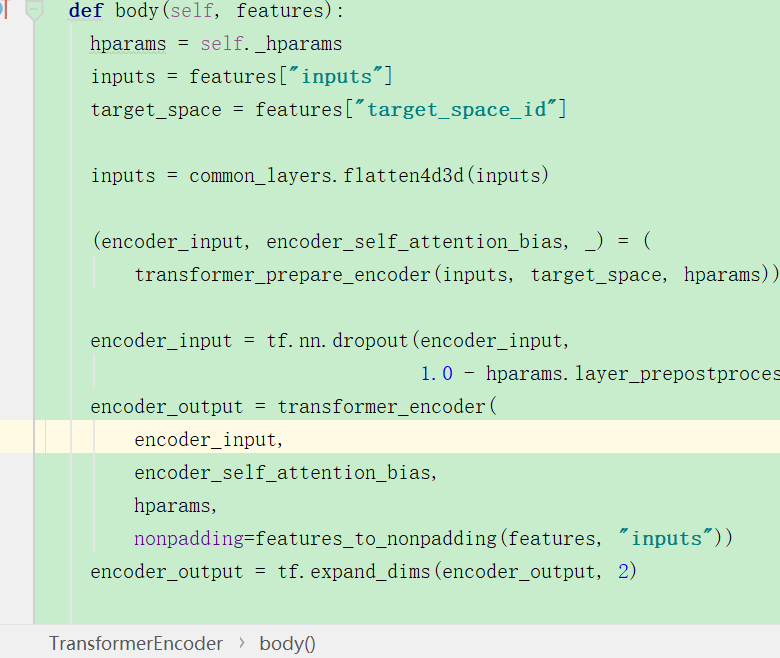
3.解码部分
transformer类的body函数就主要是进行调用encode和decode的,可以看到它的输入features的要求: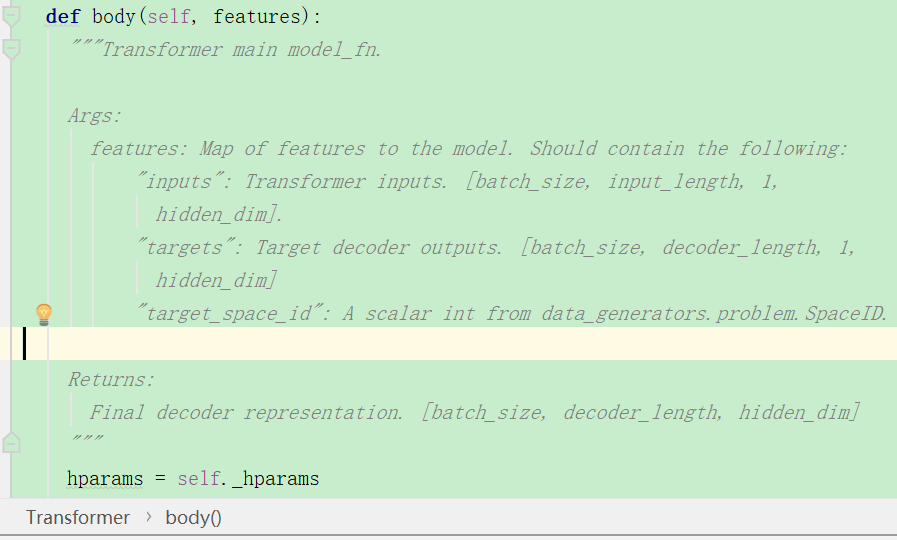
应该包含inputs和targets和id。 下面decoder,也就是targets(这个是针对机器翻译吗?)首先要对它预处理

预处理中,首先是对输出的输入进行右移的操作:

也就是在每一个seq上面都加上一行0,表示右移一位,而且第二维上还进行了[:-1]表示遗弃了最后一个word,以保证固定的seq_len长度?
可以看到在transformer_self_attention_layer函数中,包括了self与encode的attention:

首先是self的部分,和之前的encode调用方式是一样的:

但实际上内部应该是进行的不一样的,因为这个应该是有个mask的吧?需要把后面的单词挡住,看到下面的地方我明白了:
common_attention.py文件中,multihead_attention函数内,有不同的attention方法:
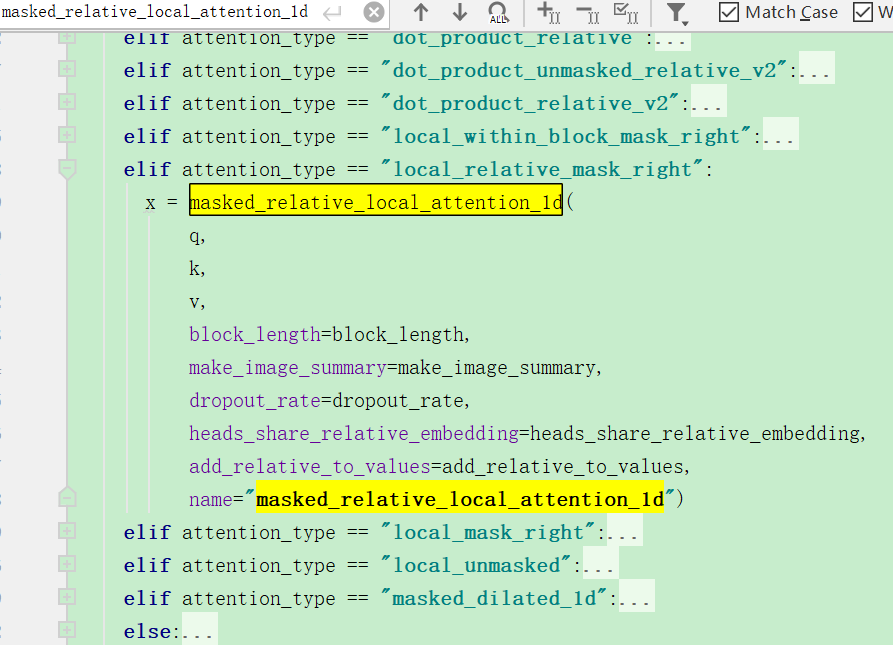
对于encoder的部分:

如果说第二个参数memory不是None的话,这样的话在计算KV的时候就可以使用encoder的输出了。
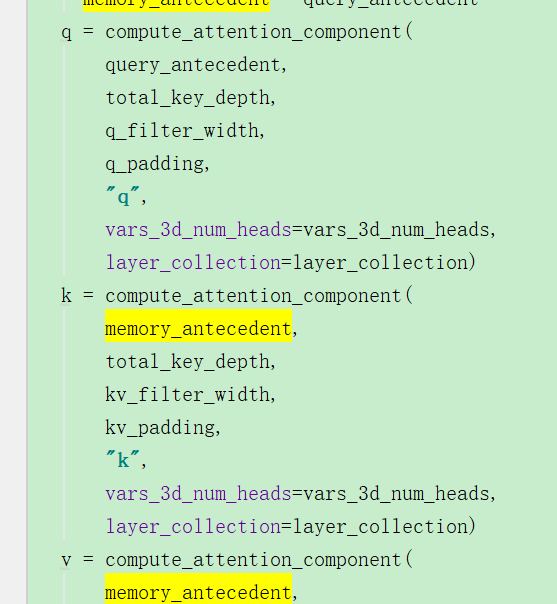
此时Q是由解码的输入确定的,KV是由encoder的输出确定的。
相关文章
- dojo/dom源码学习
- Hadoop源码学习:RPC
- xgboost 源码学习
- 自制小工具含源码——SPTC上海交通卡余额查询
- java中的==、equals()、hashCode()源码分析
- 【转载】RecyclerView源码解析
- MFC Windows 程序设计[189]之滑动窗口页签(附源码)
- Android版OpenCV图像处理技术亲自验证[三十九]之图片旋转(附源码)
- Spring读源码系列之AOP--09---aop源码流程一把拿下
- Spring contextLoaderListener源码学习
- 【项目实战】从0开始入门JDK源码 - ArrayList源码 之 overflow-conscious code
- ZLMediaKit源码学习WebRTC之UDP收报
- 从源码分析DEARGUI之add_window
- 毕业设计 Spring Boot的在线音乐网站系统(含源码+论文)
- linux内核radeon gpu源码解析5 —— drm_get_pci_dev函数详解2
- ubuntu下使用自带的openJDK查看java源码
- 第二人生的源码分析(二十八)UDP发送数据的可靠性控制
- 开源DDos 机器学习思路求解的一些源码——TODO 待分析
- 企业级Android音视频开发学习路线+项目实战+源码解析(WebRTC Native 源码、X264源码、FFmpeg、Opus源码.....)
- [spring学习]2、spring基本使用及源码分析
- [springMVC学习]6、视图解析器,debug源码
- 【java】Spring Cloud --OpenFeign源码解析学习
- 【飞桨PaddlePaddle】迁移学习快速入门,完整源码+讲解演示
- Faster RCNN网络源码解读(Ⅺ) --- 预测结果后处理及预测过程(完结撒花)
- AppArmor零知识学习九、源码构建(6)
- linux内核radeon gpu源码解析7 —— radeon_driver_load_kms函数详解2
- Scheme学习系列一 :源码安装Gambit