
【深度强化学习】Policy Gradient算法
Policy Gradient算法
Trajectory

Trajectory表示一个回合的状态-动作序列,记为
τ
\tau
τ,其发生的概率记为
p
θ
(
τ
)
p_{\theta}(\tau)
pθ(τ),计算公式如上图所示。
Policy Gradient
我们希望通过最大化下图中的Expected Reward,来进行策略的学习。

其梯度计算如下:

因此我们可以设计下图所示的损失函数,其中
θ
\theta
θ为策略神经网络的参数,其输出为每个动作的概率值
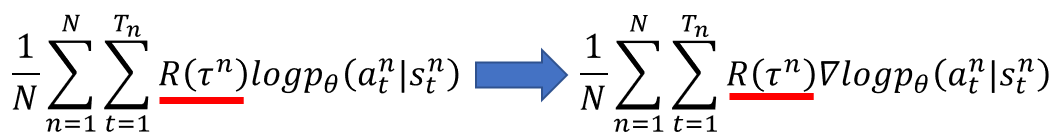
改进一
考虑到
R
(
τ
n
)
R(\tau^n)
R(τn)有可能总是正的,这会导致没有被采样到的动作其执行概率会下降,因此我们对它进行一个Add a Baseline操作,即减去它们的均值,使其既有正值又有负值。有些情况下还会除以标准差,即进行归一化操作
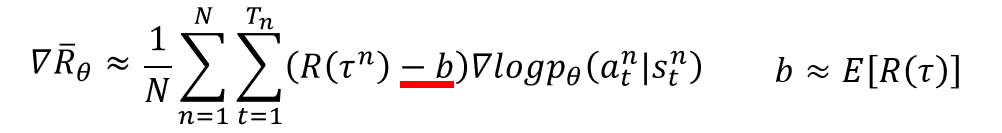
改进二
如下图所示修改
R
(
τ
n
)
R(\tau^n)
R(τn)

总结
∇ R θ ‾ = 1 N Σ n = 1 N Σ t = 1 T n Σ t ′ = t T n γ t ′ − t ∗ r t ′ n − μ σ ∇ l o g p θ ( a t n ∣ s t n ) \nabla \overline{R_{\theta}}=\dfrac{1}{N}\Sigma^N_{n=1}\Sigma^{T_n}_{t=1}\dfrac{\Sigma^{T_n}_{t^{'}=t}\gamma^{t^{'}-t}*r^n_{t^{'}}-\mu}{\sigma}\nabla log{p_{\theta}}(a_t^n|s_t^n) ∇Rθ=N1Σn=1NΣt=1TnσΣt′=tTnγt′−t∗rt′n−μ∇logpθ(atn∣stn)
代码实现
PG.py
import argparse
import gym
import numpy as np
from itertools import count
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.99, metavar='G',
help='discount factor (default: 0.99)')
parser.add_argument('--seed', type=int, default=543, metavar='N',
help='random seed (default: 543)')
parser.add_argument('--render', action='store_true',
help='render the environment')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='interval between training status logs (default: 10)')
args = parser.parse_args()
env = gym.make('CartPole-v1')
env.seed(args.seed)
torch.manual_seed(args.seed)
class Policy(nn.Module):
def __init__(self):
super(Policy, self).__init__()
self.affine1 = nn.Linear(4, 128)
self.dropout = nn.Dropout(p=0.6)
self.affine2 = nn.Linear(128, 2)
self.saved_log_probs = []
self.rewards = []
def forward(self, x):
x = self.affine1(x)
x = self.dropout(x)
x = F.relu(x)
action_scores = self.affine2(x)
return F.softmax(action_scores, dim=1)
policy = Policy()
optimizer = optim.Adam(policy.parameters(), lr=1e-2)
eps = np.finfo(np.float64).eps.item()
def select_action(state):
state = torch.from_numpy(state).float().unsqueeze(0)
probs = policy(state)
m = Categorical(probs)
action = m.sample()
policy.saved_log_probs.append(m.log_prob(action))
return action.item()
def finish_episode():
R = 0
policy_loss = []
returns = []
for r in policy.rewards[::-1]:
R = r + args.gamma * R
returns.insert(0, R)
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + eps)
for log_prob, R in zip(policy.saved_log_probs, returns):
policy_loss.append(-log_prob * R)
optimizer.zero_grad()
policy_loss = torch.cat(policy_loss).sum()
policy_loss.backward()
optimizer.step()
del policy.rewards[:]
del policy.saved_log_probs[:]
def main():
running_reward = 10
for i_episode in count(1):
state, ep_reward = env.reset(), 0
for t in range(1, 10000): # Don't infinite loop while learning
action = select_action(state)
state, reward, done, _ = env.step(action)
if args.render:
env.render()
policy.rewards.append(reward)
ep_reward += reward
if done:
break
running_reward = 0.05 * ep_reward + (1 - 0.05) * running_reward
finish_episode()
if i_episode % args.log_interval == 0:
print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(
i_episode, ep_reward, running_reward))
if running_reward > env.spec.reward_threshold:
print("Solved! Running reward is now {} and "
"the last episode runs to {} time steps!".format(running_reward, t))
torch.save(policy.state_dict(), 'hello.pt')
break
if __name__ == '__main__':
main()
pg_test.py
import torch
import gym
from PG import Policy
from torch.distributions import Categorical
model = Policy()
model.load_state_dict(torch.load('hello.pt'))
model.eval()
def select_action(state):
state = torch.from_numpy(state).float().unsqueeze(0)
probs = model(state)
m = Categorical(probs)
action = m.sample()
return action.item()
env = gym.make('CartPole-v1')
t_all = []
for i_episode in range(2):
observation = env.reset()
for t in range(10000):
env.render()
cp, cv, pa, pv = observation
action = select_action(observation)
observation, reward, done, info = env.step(action)
if done:
# print("Episode finished after {} timesteps".format(t+1))
print("倒了")
t_all.append(t)
break
env.close()
print(t_all)
print(sum(t_all) / len(t_all))
运行结果

相关文章
- 深度学习经典算法 | 粒子群算法详解
- 机器学习十大经典算法之朴素贝叶斯分类
- 简单易学的机器学习算法——Mean Shift聚类算法
- 缩点求强连通分量——Kosaraju算法 学习笔记
- Bandit算法学习与总结(二):Disjoint LinUCB、Hybrid LinUCB
- 产品能力|算法基础-哈夫曼树14天阅读挑战赛
- 【漫画算法学习笔记】第二章——2.1数组
- 【说站】python最短路径算法如何选择
- http基数树路由算法和Go源码分析
- javacv学习之实现matlab中imfill算法(孔洞填充)
- 深度学习CNN算法原理
- 刷爆Leetcode!字节算法大佬进阶专属算法笔记:GitHub标星97k+
- 上交最新深度元学习推荐算法综述
- 人工智能基础:机器学习常见的算法介绍
- 十进制转换为二进制java_二进制转八进制算法
- 【算法】实现一个魔法字典
- 《异常检测——从经典算法到深度学习》6 基于重构概率的 VAE 异常检测
- 算法学习之路 | 希尔排序[Php]
- 带你从0->1学习双指针算法
- 【深度学习】深度图像检测算法总结与对比
- 收藏 | 从SGD到NadaMax,深度学习十种优化算法原理及实现(附代码)
- 面向算法选择的元学习研究综述
- AI 黑箱难题怎么破?基于神经网络模型的算法使机器学习透明化
- 算法在Oracle中实现md5算法数据加密(Oracle中有md5)
- javascript算法学习(直接插入排序)