
Python 解析含有命名空间(xmlns)的xml文件(基于ElementTree)
2023-09-14 09:08:34 时间
Outline
为什么会有命名空间?
XML的元素名字是不固定的,当两个不同的文档,使用同样的名称描述两个不同类型的元素的时候,或者一个同样的标记表示两个不同含义的内容的时候,就会发生命名冲突。
这时,命名空间是可以解决这个问题的;
命名空间(Namespace),对于每一套特定应用的DTD,给它一个独一无二的标志来代表,如果在XML中使用DTD中定义的元素,需将 DTD的标志和元素名,属性连在一起使用,相当于指明了元素来自什么地方,这样就不会同其他同名元素混淆了。
命名空间允许我们在一个文档中结合不同的元素和属性定义,并指明这些元素和属性的定义来自那里。
命名空间语法结构:
xmlns:[prefix]=”[url of name]” 其中“xmlns:”是必须的属性。“prefix”是命名空间的别名,它的值不能为xml。 <sample xmlns:ins=”http://www.lsmx.net.ac”> <ins:batch-list> <ins:batch>Evening Batch</ins:batch> </ins:batch-list> </sample>
遇到的问题
在用ElementTree解析xml时,一直很顺利,都能解析成功;但突然出现解析不出xml情况,文本编辑器打开xml文档发现里面是有内容的;
仔细观察了下发现根标签中有一个 xmlns 属性,查了下原来是 命名空间, xml中有命名空间的情况下,获取子标签内容的话,就需要通过命名空间去唯一标识这个标签。

现在知道xml文件中的xmlns了,剩下就是结合xmlns解析数据了;
debug观察标签情况
简单debug下,看下包含xmlns的标签是什么样子的;
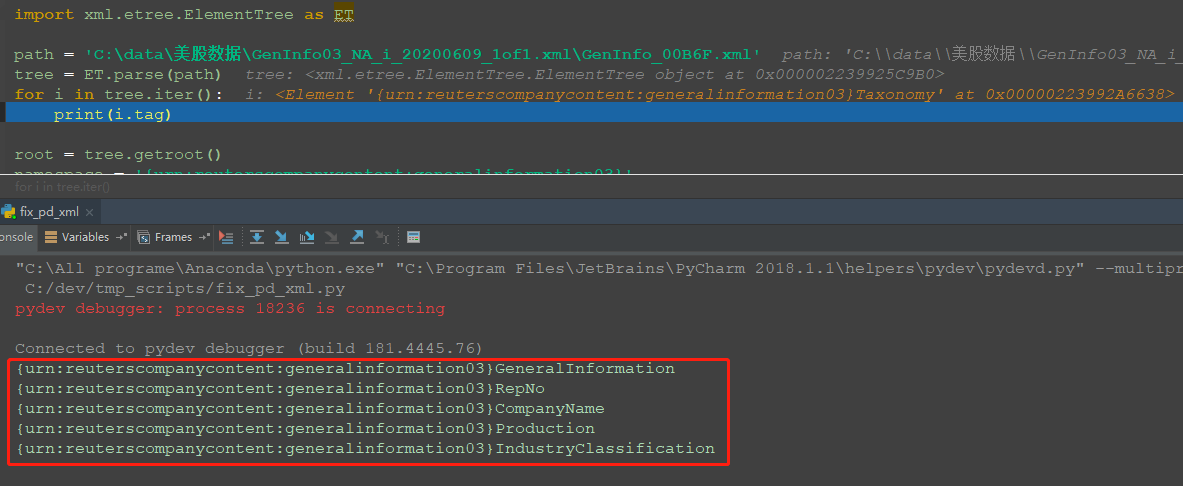
发现包含命名空间的xml,解析时(或者去定位标签时)标签的构成是:命名空间+标签名
解析数据
通过上面操作已经知道当前xml文本的xmlns是什么了,所以就直接给标签拼接上xmlns,这样获取的内容就都是该命名空间下的内容了。
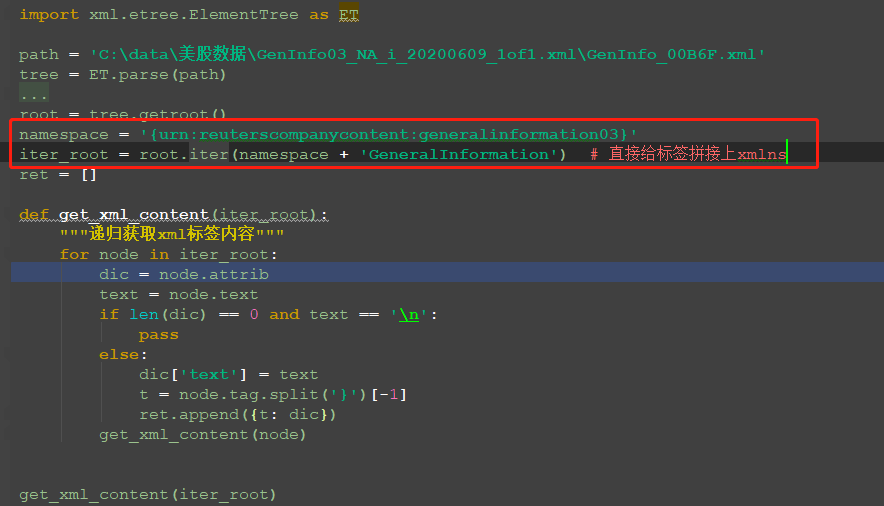
import xml.etree.ElementTree as ET path = 'C:\data\美股数据\GenInfo03_NA_i_20200609_1of1.xml\GenInfo_00B6F.xml' tree = ET.parse(path) # for i in tree.iter(): # print(i.tag) root = tree.getroot() namespace = '{urn:reuterscompanycontent:generalinformation03}' iter_root = root.iter(namespace + 'GeneralInformation') # 直接给标签拼接上xmlns ret = [] def get_xml_content(iter_root): """递归获取xml标签内容""" for node in iter_root: dic = node.attrib text = node.text if len(dic) == 0 and text == '\n': pass else: dic['text'] = text t = node.tag.split('}')[-1] ret.append({t: dic}) get_xml_content(node) get_xml_content(iter_root)
参考信息
How does XPath deal with XML namespaces?相关文章
- 配置豆瓣镜像作为python 库的下载源
- Python遍历路径下文件并转换成UTF-8编码
- python导入csv文件出现SyntaxError问题分析
- Python中生成器和yield语句的用法详解
- python分片下载文件
- python处理xml文件
- Python可视化数据分析08、Pandas_Excel文件读写
- 〖Python自动化办公篇⑧〗- word文件自动化 - 创建并生成 word 文档
- 基于改进的蚂蚁群算法求解最短路径问题、二次分配问题、背包问题【Matlab&Python代码实现】
- Python爬虫基础讲解:数据持久化——文件操作 及 Excel
- Python 实现循环的最快方式对比,结论却出乎意料
- 【华为机试真题 Python实现】括号匹配II
- 【 华为OD机试 2023】 最大连续文件之和 / 区块链文件转储系统(C++ Java JavaScript Python)
- python判断文件类型是否是gz、tar、zip类型的文件(亲测可用)
- python之合并文件
- Python:psd-tools解析PSD文件
- Python编程:Python2.7环境下的中文文件读写
- python XML文件解析:用xml.dom.minidom来解析xml文件
- python 读csv文件时,在csv类型上执行类型转换
- 零基础学python-2.17 文件、open()、file()
- 使用 profile 进行python代码性能分析
- Python可视化数据分析07、Pandas_CSV文件读写
- 〖Python自动化办公篇⑧〗- word文件自动化 - 创建并生成 word 文档
- windows下运行python文件路径总是出错?
- Python for循环举例