
Pandas 之 过滤DateFrame中所有小于0的值并替换
pandas 所有 替换 过滤 小于
2023-09-14 09:08:35 时间
Outline
前几天,数据清洗时有用到pandas去过滤大量数据中的“负值”;
把过滤出来的“负值”替换为“NaN”或者指定的值。
故做个小记录。
读取CSV文件
代码:
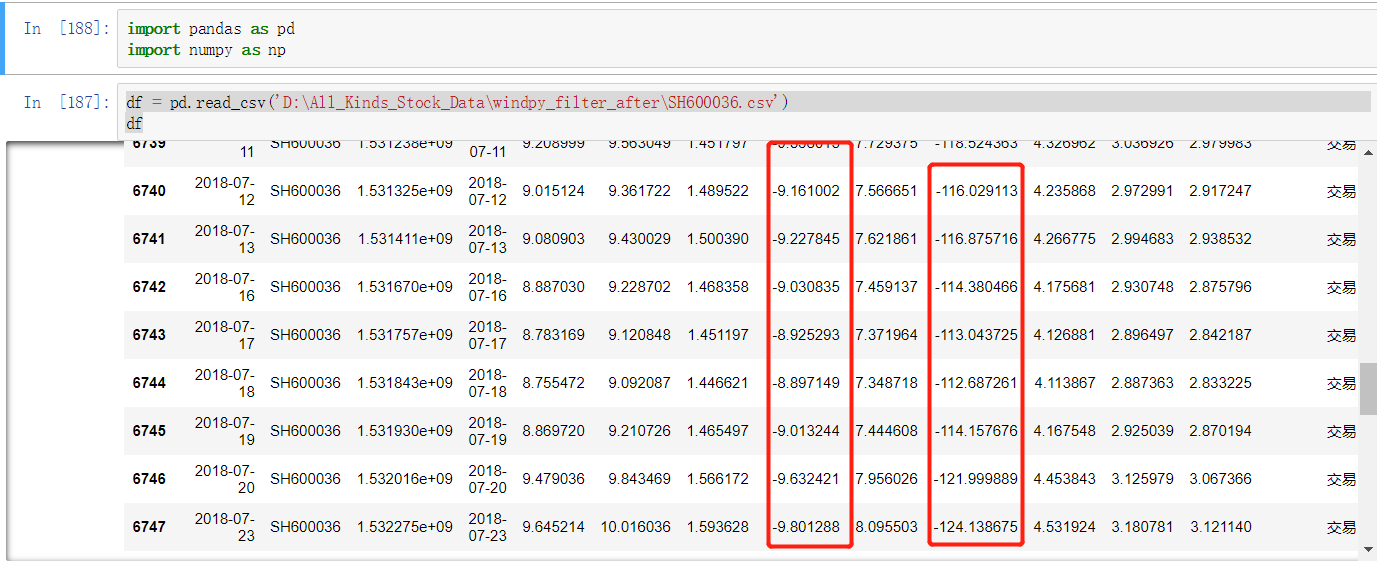
import pandas as pd import numpy as np df = pd.read_csv('D:\All_Kinds_Stock_Data\windpy_filter_after\SH600036.csv') df # 开发环境: ipython notebook 下
读取本地csv文件,输出结果如下:
可见里面有很多“负值”。
目的就是将这些“负值”替换掉。
过滤“负值”
代码:
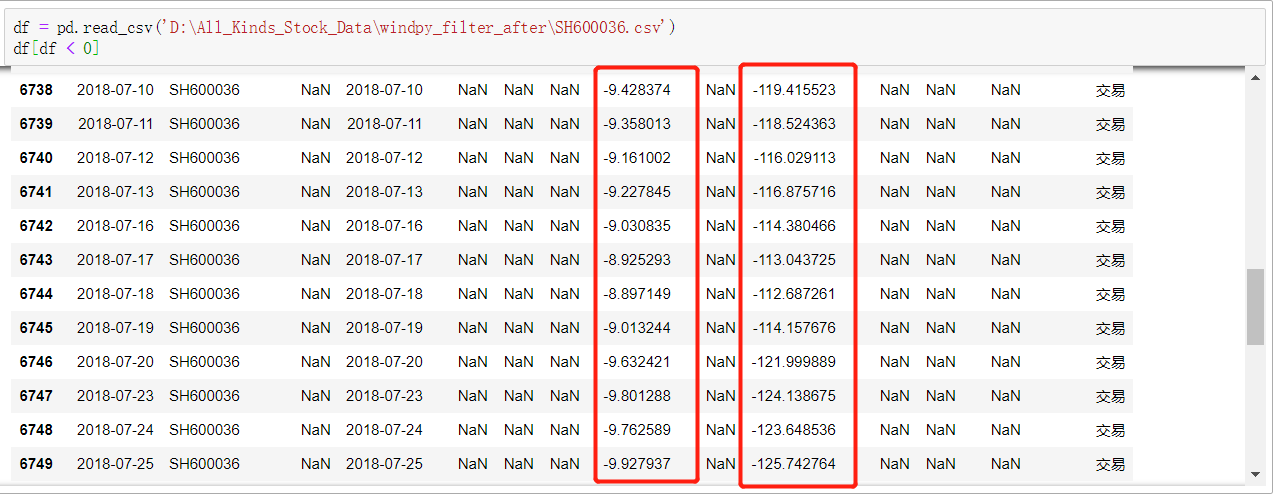
import pandas as pd import numpy as np df = pd.read_csv('D:\All_Kinds_Stock_Data\windpy_filter_after\SH600036.csv') df[ df < 0 ] # 过滤出所有小于 0 的对象 # 开发环境: ipython notebook 下
此时拿到的是csv文件中所有小于 0 的元素(也即小于 0 的DateFrame对象)
替换“负值”
将过滤出来小于 0 的DateFrame对象替换成指定值。
这里我需要将它们替换为 NaN
代码:
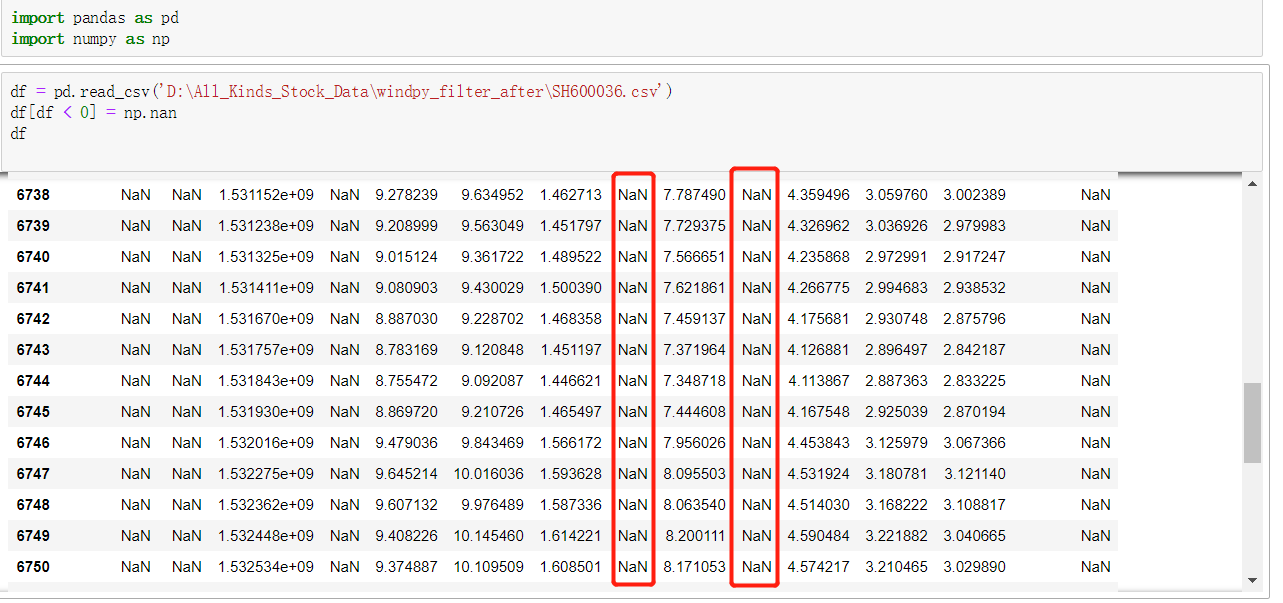
import pandas as pd import numpy as np df = pd.read_csv('D:\All_Kinds_Stock_Data\windpy_filter_after\SH600036.csv') df[df < 0] = np.nan # 对过滤出来的对象进行赋值替换 df
此时,所有“负值”已被替换为 NaN
如果你想把替换后的DateFrame保存为新的csv文件的话,只需要如下操作:
df = pd.read_csv('D:\All_Kinds_Stock_Data\windpy_filter_after\SH600036.csv') df[df < 0] = np.nan df.to_csv('你的保存路径', index=True) # index = True/False 表示是否把索引index一起写入csv文本。

相关文章
- 用Python的pandas框架操作Excel文件中的数据教程
- numpy+pandas+matplotlib+tushare股票分析
- Python之pandas:特征工程中数据类型(object/category/bool/int32/int64/float64)的简介、数据类型转换四大方法、案例应用之详细攻略
- Python之pandas:将dict字典格式数据保存为dataframe格式数据的几种方法
- ML之FE:数据预处理中基于pandas实现类别型字段数据编码(包括自定义编码映射字典)、目标变量布尔类型化且同时输出raw_df和df数据之代码实现攻略
- Py之pandas:利用where、replace等函数对dataframe格式数据按照条件进行数据替换
- Python语言学习:利用pandas对两列字段元素求差集(对比两列字段所有元素的异同)
- 已解决Python pandas读取Excel表格某些数值字段结果为NaN问题
- 这可能是最全的总结了,详解 20 个 pandas 读与写函数
- 【阶段二】Python数据分析Pandas工具使用01篇:Pandas工具介绍、Pandas工具安装、数据结构:Series数据结构与DataFrame数据结构
- pandas DataFrame对行进行选择
- Pandas 如何去除、取消已经设置好的索引
- pandas入门10分钟——serries其实就是data frame的一列数据