
AdaBoost算法学习笔记
AdaBoost算法
前面我介绍了提升方法,但是没有具体的介绍其中的某一种算法,下面,就介绍提升方法中一种典型的算法AdaBoost.
之前讲过提升方法需要完成两个目标,一是在每一轮训练中如何改变训练数据的权值或概率分布。二是如何将弱分类器线性组合成一个强分类器。
AdaBoost对于第一个问题,对于前一轮错误分类的样本改变它的权值在下一轮训练中被更加关注,对于第二个问题,使分类错误率更小的分类器有更大的权值。
下面就详细介绍一下它的算法实现
首先,有一个大小为N的训练数据集,即这个训练数据集有N个样本,按照之前所说的,我们先给这个数据集的每一个样本设置一个权值,这个权值决定这个样本在下一轮分类器的训练中的关注度。因为第一轮是首轮,所以每一样本应该被平等对待,即每个样本对应的权值为1/N.
上面应该有一个疑惑,这个权值决定这个样本训练中的重要性,那么怎么体现的呢?又依据什么去改变权值呢?
其实这些都是依据分类误差率来决定的,这个分类误差率是我们自定义的,如下式
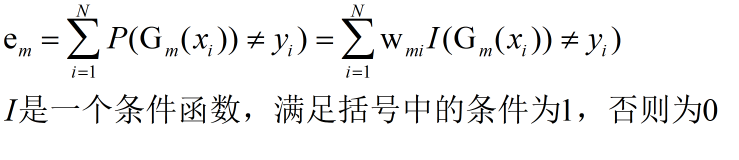
对于上面这个式子,解释一下,我们针对每一轮的分类器的训练准则就是误差率尽量小,现在,我们定义的误差率是上式显示的误差计算公式,你会发现误差率仍然由每一个样本决定,分类错误的越多误差越大,但是我们加入了一个权重W,在W,这是你会发现,如果,某一个样本对应的权值W很大,那么它如果被错误分类了,误差率增大的幅度会很大,所以通过重新定义误差率公式,我们就能利用每一个样本的权值W去决定那个样本在下一轮训练中的关注度,其对应的W越大越被关注。
那么提升方法第一问题解决了,第二个问题呢?
给出下面的公式
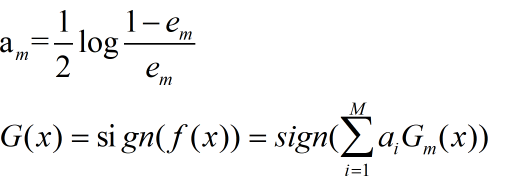
a是什么,a就是我们前面提到若分类器线性组合是与其相乘的权重,它决定了这个弱分类器在组合强分类器时发挥的重要性程度,从上面的式子其实可以看出,分类误差率越小,a就越大。G(x)也就是我们最终学习的强分类器。还有最后一个问题,权值决定每个样本关注度的权值怎么更新?
下面给出公式,至于这个公式怎么来的,有些复杂,这里就不解释了
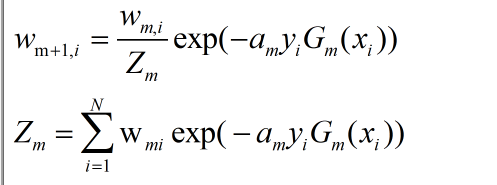
m+1,表示训练的是第m+1轮,即第m+1个弱分类器,i表示这个权值对应的是序号为i的样本。
相关文章
- 基于TMS320F28377D开发板的DSP CLA算法案例开发手册
- Python学习笔记:几种排序算法
- 算法刷题笔记03:Stack、Queue
- 图解排序算法(三)之堆排序
- 《算法竞赛进阶指南》0x00 基本算法 - 学习笔记
- 算法基础课 - 并查集笔记
- OpenSSL密码库算法笔记——第5.1.1章 椭圆曲线点群的定义
- 大数的阶乘算法
- 缩点求强连通分量——Kosaraju算法 学习笔记
- JVM 学习笔记(3):HotSpot 算法实现的细节
- 算法笔记汇总精简版下载_算法与数据结构笔记
- 数据结构与算法笔记
- 【论文阅读笔记】Myers的O(ND)时间复杂度的高效的diff算法
- 《斯坦福算法博弈论二十讲》学习笔记(持续更新)
- 基础知识_算法笔记
- jvm可达性分析算法_对点网络
- KMP算法笔记II ----- 学会计算next数组
- KMP算法笔记I ----- 先学会朴素算法
- 《机器学习算法竞赛实战笔记1》:如何看待机器学习竞赛问题?
- C语言 | 动图演示十大经典排序算法(含代码)
- 发现一位大佬的算法刷题笔记PDF
- 无意中发现一位大佬的算法刷题pdf笔记
- Java数据结构学习笔记之三Java数据结构与算法之队列(Queue)实现详解编程语言
- Java学习笔记之十一Java中常用的8大排序算法详解总结编程语言
- 无重复字符的最长子串及最小覆盖子串(滑动窗口法)算法详解编程语言