
【机器学习项目实战】Python实现GA(遗传算法)对SVM分类模型参数的优化
说明:这是一个机器学习实战项目(附带数据+代码),如需数据+完整代码可以直接到文章最后获取。
1.需求分析
在国家一系列政策密集出台的环境下,在国内市场强劲需求的推动下,我国家用燃气灶具产业整体保持平稳较快增长。随着产业投入加大、技术突破与规模积累,在可以预见的未来,开始迎来发展的加速期。某电器公司的燃气灶产品销售额一直在国内处于领先地位,把产品质量视为重中之重,每年都要对其产品质量数据进行分析研究,以期不断完善,精益求精。本模型也是基于一些历史数据进行维修方式的建模、预测。
2.数据采集
本数据是模拟数据,分为两部分数据:
数据集:data.xlsx
在实际应用中,根据自己的数据进行替换即可。
特征数据:故障模式、故障模式细分、故障名称、单据类型
标签数据:维修方式
3.数据预处理
1)原始数据描述:
2)原始数据文本转换为数值:
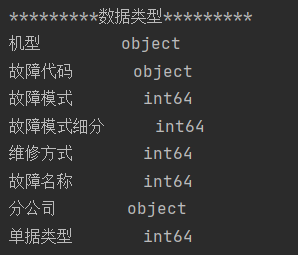
2)数据完整性、数据类型查看:
print(data_.dtypes) # 打印数据类型
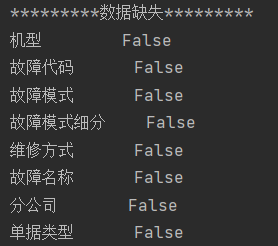
3)数据缺失值个数:
print(data_.isnull().any()) # 查看是否有NULL值
可以看到数据不存在缺失值。
4)哑特征处理
特征变量故障模式、故障模式细分、故障名称中的数值为文本类型,不符合机器学习数据要求,需要进行哑特征处理,变为0 1数值。
关键代码如下:
处理后,数据如下:
4.探索性数据分析
1)特征变量故障分析:
故障分析:在维修记录中不同部件维修数量不同,其中“电极针坏”的数量占比最多,占全部维修记录的64.12%。“热电偶坏”和“电磁阀坏”的占比次之,分别为14.87%和11.29%。
explodes = [0.1 if i == "sales" else 0 for i in lbs] matplotlib.rcParams['font.sans-serif'] = ['SimHei'] plt.figure(figsize=(5, 5)) # 创建子图,大小为5*5 patches, l_text, p_text = plt.pie(data["故障模式"].value_counts(normalize=True), explode=explodes, labels=lbs, autopct='%.2f%%', radius=0.8) for t in p_text: t.set_size(12) for t in l_text: t.set_size(12) plt.show()
2)特征变量故障模式分析:
故障模式又分别细分为5项:“开裂”、“变形”、“老化”、“调整电极针位置”、“热电偶与电磁阀接触不良”。
def pie_pic(data, color=None, radius=None): lbs = data.value_counts().index if color: matplotlib.rcParams['font.sans-serif'] = ['SimHei'] plt.pie(data.value_counts(normalize=True), labels=lbs, colors=sns.color_palette(color, 4), autopct='%.2f%%', radius=radius, startangle=120)
3)相关性分析
df_tmp1 = df_data[ ['故障模式_1', '故障模式_2', '故障模式_3', '故障模式_4', '故障模式_5', '故障模式细分_1', '故障模式细分_2', '故障模式细分_3', '故障模式细分_4', '故障模式细分_5', '故障名称_1', '故障名称_2', '维修方式']] plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False sns.heatmap(df_tmp1.corr(), cmap="YlGnBu", annot=True) plt.show()
说明:正值是正相关、负值时负相关,值越大变量之间的相关性越强。
5.特征工程
1)特征数据和标签数据拆分,y为标签数据,除y之外的为特征数据;
2)数据集拆分,分为训练集和尝试集,80%训练集和20%验证集;
3)数据归一化
6.机器建模
1)遗传算法简单介绍:
遗传算法,也叫Genetic Algorithm,简称 GA 算法他既然叫遗传算法,那么遗传之中必然有基因,那么基因染色体(Chromosome)就是它的需要调节的参数。我们在生物中了解到,大自然的法则是“物竞天择,适者生存”,我觉得遗传算法更适用于“优胜劣汰”。
- 优:最优解,
- 劣:非最优解。
遗传算法的实现流程:
涉及到还是适应度函数、选择、交叉、变异这几个模块。下面就这几个模块展开说明。具体的流程图解释如下:
(1)需要先对初始种群进行一次适应度函数进行计算,这样方便我们对个体进行选择,适应度值越大的越容易被保留;
(2)对群体进行选择,选择出适应度值较大的一部分优势群体;
(3)对优势种群进行 “交配”,更容易产生优秀的个体;
(4)模拟大自然变异操作,对染色体个体进行变异操作;
2)本次机器学习工作流程:
(1)种群数量NIND = 50代表第一代种群先进行50次的模型训练作为50个初始个体,每次训练的[C,G](当然每次训练的C和G还是随机初始化的)就是这个个体的的染色体;
(2)目标函数就是训练集上的分类准确度(当然下面代码用的交叉验证分数,含义其实是一样的);
(3)选择、交叉、变异、进化
(4)最后末代种群中的最优个体得到我们想要的C和Gamma,把这两个参数代入到测试集上计算测试集结果
3)应用遗传算法GA得到最优的调参结果
编号
名称
1
评价次数:750
2
时间已过 2950.9299054145813 秒
3
最优的目标函数值为:0.9611955168119551
4
最优的控制变量值为:
5
C的值:149.7418557703495
6
G的值:0.00390625
最优的空值变量C、G的值,大家在实际数据集过程种可以慢慢尝试。
4)建立支持向量机分类模型,模型参数如下:
编号
参数
1
C=C
2
kernel='rbf'
3
gamma=G
其它参数根据具体数据,具体设置。
7.模型评估
1)评估指标主要采用准确率分值、查准率、查全率、F1
编号
评估指标名称
评估指标值
1
准确率分值
0.96
2
查准率
95.02%
3
查全率
99.73%
4
F1
97.32%
通过上述表格可以看出,此模型效果良好。
class MyProblem(ea.Problem): # 继承Problem父类 def __init__(self, PoolType): # PoolType是取值为'Process'或'Thread'的字符串 name = 'MyProblem' # 初始化name(函数名称,可以随意设置) M = 1 # 初始化M(目标维数) maxormins = [-1] # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标) Dim = 2 # 初始化Dim(决策变量维数) varTypes = [0, 0] # 初始化varTypes(决策变量的类型,元素为0表示对应的变量是连续的;1表示是离散的) lb = [2 ** (-8)] * Dim # 决策变量下界 ub = [2 ** 8] * Dim # 决策变量上界 lbin = [1] * Dim # 决策变量下边界(0表示不包含该变量的下边界,1表示包含) ubin = [1] * Dim # 决策变量上边界(0表示不包含该变量的上边界,1表示包含) # 调用父类构造方法完成实例化 ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin) # 目标函数计算中用到的一些数据 ori_data = pd.read_excel("data.xlsx", header=1) print(ori_data.head()) # 读取预处理后的数据 self.data = preprocessing.scale(np.array(X_train)) # 训练集的特征数据(归一化) self.dataTarget = np.array(Y_train) # 设置用多线程还是多进程 self.PoolType = PoolType if self.PoolType == 'Thread': self.pool = ThreadPool(2) # 设置池的大小 elif self.PoolType == 'Process': num_cores = int(mp.cpu_count()) # 获得计算机的核心数 self.pool = ProcessPool(num_cores) # 设置池的大小 def aimFunc(self, pop): # 目标函数,采用多线程加速计算 Vars = pop.Phen # 得到决策变量矩阵 args = list( zip(list(range(pop.sizes)), [Vars] * pop.sizes, [self.data] * pop.sizes, [self.dataTarget] * pop.sizes)) if self.PoolType == 'Thread': pop.ObjV = np.array(list(self.pool.map(subAimFunc, args))) elif self.PoolType == 'Process': result = self.pool.map_async(subAimFunc, args) result.wait() pop.ObjV = np.array(result.get()) def test(self, C, G): # 代入优化后的C、Gamma对测试集进行检验 data_test = pd.read_excel("data_test.xlsx") X_test = data_test.drop(columns=['维修方式']) Y_test = data_test['维修方式'] data_test = preprocessing.scale(np.array(X_test)) # 测试集的特征数据(归一化) dataTarget_test = np.array(Y_test) # 测试集的标签数据 svc = svm.SVC(C=C, kernel='rbf', gamma=G).fit(self.data, self.dataTarget) # 创建分类器对象并用训练集的数据拟合分类器模型 dataTarget_predict = svc.predict(X_test) # 采用训练好的分类器对象对测试集数据进行预测 print("测试集数据分类正确率 = %s%%" % ( len(np.where(dataTarget_predict == dataTarget_test)[0]) / len(dataTarget_test) * 100)) print("验证集查准率: {:.2f}%".format(precision_score(Y_test, dataTarget_predict) * 100)) # 打印验证集查准率 print("验证集查全率: {:.2f}%".format(recall_score(Y_test, dataTarget_predict) * 100)) # 打印验证集查全率 print("验证集F1值: {:.2f}%".format(f1_score(Y_test, dataTarget_predict) * 100)) # 打印验证集F1值 def subAimFunc(args): i = args[0] Vars = args[1] data = args[2] dataTarget = args[3] C = Vars[i, 0] G = Vars[i, 1] svc = svm.SVC(C=C, kernel='rbf', gamma=G).fit(data, dataTarget) # 创建分类器对象并用训练集的数据拟合分类器模型 scores = cross_val_score(svc, data, dataTarget, cv=30) # 计算交叉验证的得分 ObjV_i = [scores.mean()] # 把交叉验证的平均得分作为目标函数值 return ObjV_i import geatpy as ea # import geatpy if __name__ == '__main__': """===============================实例化问题对象===========================""" PoolType = 'Thread' # 设置采用多线程,若修改为: PoolType = 'Process',则表示用多进程 problem = MyProblem(PoolType) # 生成问题对象 """=================================种群设置==============================""" Encoding = 'RI' # 编码方式 NIND = 50 # 种群规模 Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges, problem.borders) # 创建区域描述器 population = ea.Population(Encoding, Field, NIND) # 实例化种群对象(此时种群还没被初始化,仅仅是完成种群对象的实例化) """===============================算法参数设置=============================""" myAlgorithm = ea.soea_SGA_templet(problem, population) myAlgorithm.MAXGEN = 30 # 最大代数 myAlgorithm.trappedValue = 1e-6 # “进化停滞”判断阈值 myAlgorithm.maxTrappedCount = 10 # 进化停滞计数器最大上限值,如果连续maxTrappedCount代被判定进化陷入停滞,则终止进化 myAlgorithm.logTras = 1 # 设置每隔多少代记录日志,若设置成0则表示不记录日志 myAlgorithm.verbose = True # 设置是否打印输出日志信息 myAlgorithm.drawing = 1 # 设置绘图方式(0:不绘图;1:绘制结果图;2:绘制目标空间过程动画;3:绘制决策空间过程动画) """==========================调用算法模板进行种群进化========================""" [BestIndi, population] = myAlgorithm.run() # 执行算法模板,得到最优个体以及最后一代种群 BestIndi.save() # 把最优个体的信息保存到文件中 """=================================输出结果==============================""" print('评价次数:%s' % myAlgorithm.evalsNum) print('时间已过 %s 秒' % myAlgorithm.passTime) if BestIndi.sizes != 0: print('最优的目标函数值为:%s' % (BestIndi.ObjV[0][0])) print('最优的控制变量值为:') for i in range(BestIndi.Phen.shape[1]): print(BestIndi.Phen[0, i]) """=================================检验结果===============================""" problem.test(C=BestIndi.Phen[0, 0], G=BestIndi.Phen[0, 1]) else: print('没找到可行解。')8.实际应用
根据测试集的特征数据,来预测这些产品的维修方式。可以根据预测的维修方式类型,进行产品的优化和人员工作的安排。具体预测结果此处不粘贴图片了。












本次机器学习项目实战所需的资料,项目资源如下:https://download.csdn.net/download/weixin_42163563/21110938
相关文章
- 鲲鹏云实验-Python+Jupyter机器学习基础环境
- Python小数据保存,有多少中分类?不妨看看他们的类比与推荐方案...
- python判断字符串是否是json格式方法分享
- python使用cPickle模块序列化实例
- Python每日一练(机器学习)——第43天:鸢尾花分类
- 超全整理:机器学习和 Python 技术路线来了
- 机器学习入门:7000字详解 Python 环境安装
- 机器学习模型可解释性的6种Python工具包,总有一款适合你!
- 【阶段三】Python机器学习32篇:机器学习项目实战:关联分析的基本概念和Apriori算法的数学演示
- 【阶段三】Python机器学习30篇:机器学习项目实战:智能推荐系统的基本原理与计算相似度的常用方法
- 【阶段三】Python机器学习23篇:机器学习项目实战:XGBoost分类模型
- 【阶段三】Python机器学习20篇:机器学习项目实战:AdaBoost回归模型
- 【阶段三】Python机器学习12篇:机器学习项目实战:朴素贝叶斯模型的算法原理与朴素贝叶斯分类模型
- 【阶段三】Python机器学习08篇:机器学习项目实战:决策树分类模型
- 【阶段三】Python机器学习05篇:机器学习项目实战:逻辑回归模型
- 【阶段三】Python机器学习02篇:机器学习项目流程
- 【机器学习实战】python机器学习之贝叶斯分类
- 【机器学习】Fuzzy C-Means(模糊C均值聚类)原理概述和python代码实现完整版
- Python: translate()审查清理文本字符串
- python 与机器学习实战(何宇健)代码下载
- python 机器学习中各种距离
- 【机器学习算法-python实现】矩阵去噪以及归一化