
只需三五行代码即可产出完美数据分析报告,这四大 AutoEDA 工具包真的太棒了
在三年前,我们做数据竞赛或者数据建模类的项目时,前期我们会耗费较多的时间去分析数据,但现在非常多擅长数据分析的大师们已经将我们平时常看的数据方式进行了集成,开发了很多AutoEDA的工具包。可以帮助我们节省大量时间,对于刚刚学习数据分析的小伙伴可以带来非常大的帮助。
本篇文章我们介绍目前最流行的四大AutoEDA工具包。
-
D-tale
-
Pandas-Profiling
-
Sweetviz
-
AutoViz
这几个工具包可以以短短三五行代码帮新手节省将近一天时间去写代码分析,非常建议大家收藏学习,喜欢点赞支持,文末提供技术交流群,尽情畅聊。
介绍
01 D-Tale

D-Tale是Flask后端和React前端组合的产物,也是一个开源的Python自动可视化库,可以为我们提供查看和分析Pandas DataFrame的方法,帮助我们获得非常数据的详细EDA。
目前D-Tale支持DataFrame、Series、MultiIndex、DatetimeIndex 和 RangeIndex 等 Pandas 对象。
Github 链接
https://github.com/man-group/dtale
# pip install dtale
import dtale
import pandas as pd
df = pd.read_csv('./data/titanic.csv')
d = dtale.show(df)
d.open_browser()
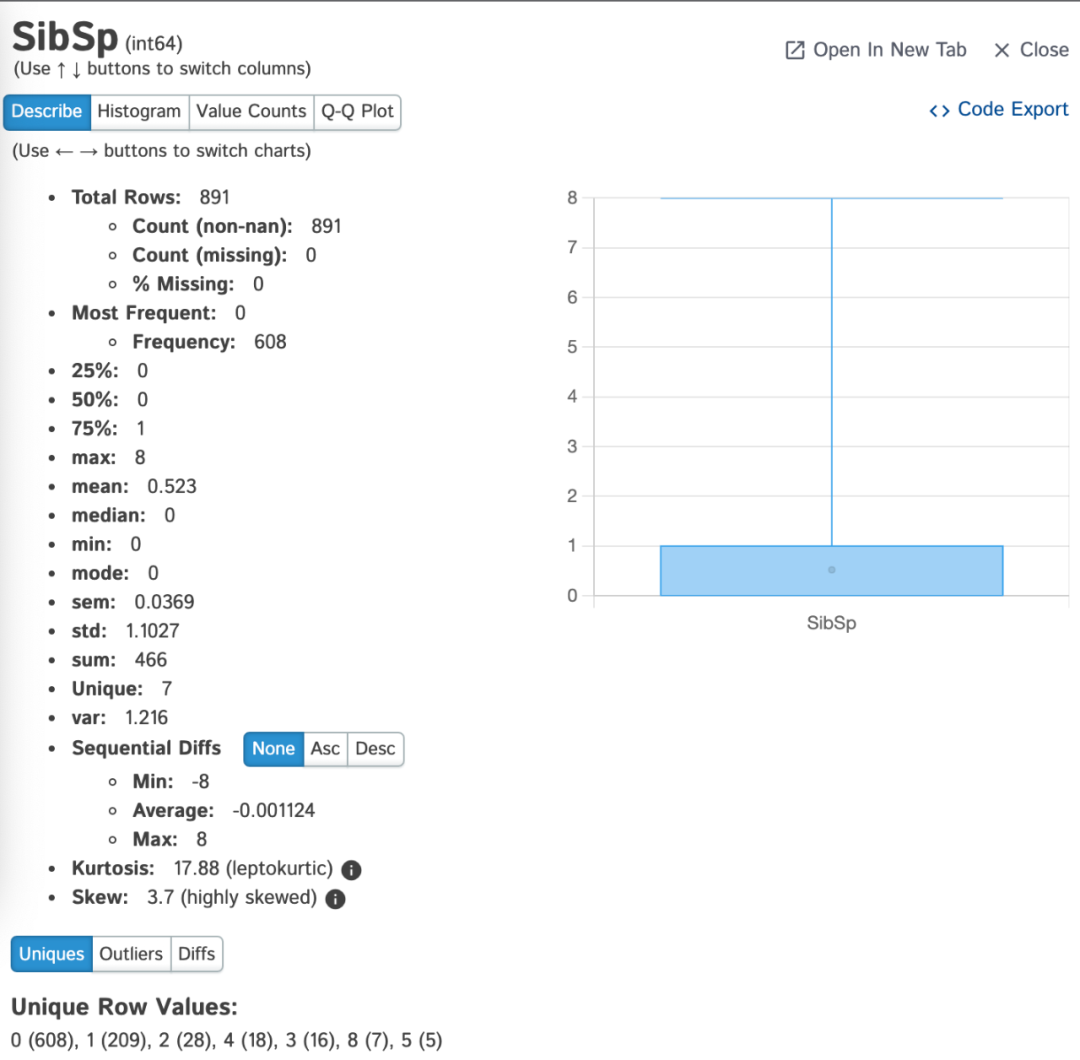
02 Pandas-Profiling

Pandas-Profiling可以对Pandas DataFrame生成report报告。其中:
- pandas_profiling的df.profile_report()扩展了pandas DataFrame以方便进行快速数据分析。
Pandas-Profiling对于每一列特征,特征的统计信息(如果与列类型相关)会显示在交互式 HTML的report中:
-
Type:检测数据列类型;
-
Essentials:类型、unique值、缺失值
-
分位数统计,如最小值、Q1、中位数、Q3、最大值、范围、四分位距
-
描述性统计数据,如均值、众数、标准差、总和、中值绝对偏差、变异系数、峰态、偏度
-
出现最多的值
-
直方图
-
高度相关变量、Spearman、Pearson 和 Kendall 矩阵的相关性突出显示
-
缺失值矩阵、计数、热图和缺失值树状图
-
…
Github 链接
https://github.com/pandas-profiling/pandas-profiling/
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report")
profile
2021-10-30 22:50:43,584 - INFO - Pandas backend loaded 1.2.5
2021-10-30 22:50:43,597 - INFO - Numpy backend loaded 1.19.2
2021-10-30 22:50:43,599 - INFO - Pyspark backend NOT loaded
2021-10-30 22:50:43,600 - INFO - Python backend loaded
一个特征的案例
03 Sweetviz

Sweetviz也是一个开源Python库,Sweetviz可以用简短几行代码生成美观、高密度的可视化文件,只需两行代码即可开启探索性数据分析并输出一个完全独立的 HTML 应用程序。Sweetviz主要包含下面的分析:
-
数据集概述
-
变量属性
-
类别的关联性
-
数值关联性
-
数值特征最频繁值、最小、最大值
Github 链接
https://github.com/fbdesignpro/sweetviz
# pip install sweetviz
import sweetviz as sv
sweetviz_report = sv.analyze(df)
sweetviz_report.show_html()
04 AutoViz

AutoViz可以使用一行自动显示任何数据集。给出任何输入文件(CSV、txt或json),AutoViz都可以对其进行可视化。AutoViz的结果会以非常多的图片都形式存在文件夹下方。
Github 链接
https://github.com/AutoViML/AutoViz
# pip install autoviz
from autoviz.AutoViz_Class import AutoViz_Class
AV = AutoViz_Class()
sep = ';'
dft = AV.AutoViz(filename="",sep=sep, depVar='Pclass', dfte=df, header=0, verbose=2,
lowess=False, chart_format='png', max_rows_analyzed=150000, max_cols_analyzed=30)
-
诸多文件全都在当前文件夹下方

-
我们打开其中一个效果如下:

适用问题
适用于所有的数据分析问题。
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

相关文章
- 数据透视表上线!如何在纯前端实现这个强大的数据分析功能?
- 【文末送书】对于入门Python数据分析和数据可视化,我想推荐一下这本书!
- 147万行数据分析、挖掘代码的分析2021.8.25
- 标准绩效数据分析表的设计
- 【视频】CNN(卷积神经网络)模型以及R语言实现回归数据分析|附代码数据
- PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化|附代码数据
- 从零开始的异世界生信学习 GEO数据库数据挖掘--GEO代码-芯片数据分析-1
- 二手图书价格数据分析2022.9.2
- 淘宝app的用户消费行为数据分析
- PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化|附代码数据
- R语言用贝叶斯层次模型进行空间数据分析|附代码数据
- 跟着Nature Communications学数据分析:R语言做随机森林模型并对变量重要性排序
- 大数据分析工具Power BI(二):Power BI下载安装和模块介绍
- 【2023年第十一届泰迪杯数据挖掘挑战赛】B题:产品订单的数据分析与需求预测 建模及python代码详解 问题一
- 大数据分析工具Power BI(十):制作可视化图表的报表类型
- Linux下使用SPSS实现数据分析(linuxspss)
- 函数Oracle窗口函数—为数据分析注入新的动力(oracle窗口)
- 2017 年哪个公司对开源贡献最多?让我们用 GitHub 的数据分析下
- MySQL分析函数详解:让聚合查询更强大,数据分析更高效!(mysql分析函数大全)
- 游刃有余:Oracle数据分析结合R语言的运用(oracler语言)
- 利用Oracle中的关联子查询进行数据分析(oracle中关联子查询)
- 使用Oracle BI建模,数据分析更深入(oracle bi 建模)
- Oracle 27140智能云服务提升数据分析能力 (oracle 27140)