
注意力(Attention)
概述
在RNN 课程中,我们被限制在最后使用表示,但是如果我们可以为每个编码输入赋予上下文权重(H一世) 在做出我们的预测时?这也是优选的,因为它可以帮助缓解因处理非常长的序列而导致的梯度消失问题。下面是应用于 RNN 输出的注意力。理论上,输出可以来自我们想学习如何在它们之间加权的任何地方,但是由于我们正在使用上一课中的 RNN 的上下文,我们将继续这样做。

| 多变的 | 描述 |
|---|---|
| ñ | 批量大小 |
| 米 | 批处理中的最大序列长度 |
| H | 隐藏的暗淡,模型暗淡等。 |
| H | RNN 输出(或您想要关注的任何输出组)∈RñX米XH |
| 一个吨,一世 | 对齐函数上下文向量C吨(在我们的例子中注意)$ |
| 在一个吨吨n | 学习的注意力权重∈RHX1 |
| C吨 | 考虑不同输入的上下文向量 |
- 目标:
- 在其核心,注意力是关于学习如何权衡一组编码表示以产生用于下游任务的上下文感知表示。这是通过学习一组注意力权重,然后使用 softmax 创建总和为 1 的注意力值来完成的。
- 优点:
- 了解如何在不考虑位置的情况下考虑适当的编码表示。
- 缺点:
- 另一个涉及学习权重的计算步骤。
- 杂项:
- 几种最先进的方法扩展了基本注意力,以提供高度上下文感知的表示(例如自我注意力)。
设置
让我们为我们的主要任务设置种子和设备。
import numpy as np
import pandas as pd
import random
import torch
import torch.nn as nn
import torch.nn.functional as FSEED = 1234def set_seeds(seed=1234):
"""Set seeds for reproducibility."""
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # multi-GPU# Set seeds for reproducibility
set_seeds(seed=SEED)# Set device
cuda = True
device = torch.device("cuda" if (
torch.cuda.is_available() and cuda) else "cpu")
torch.set_default_tensor_type("torch.FloatTensor")
if device.type == "cuda":
torch.set_default_tensor_type("torch.cuda.FloatTensor")
print (device)加载数据
我们将下载AG News 数据集Business,该数据集包含来自 4 个独特类别( 、Sci/Tech、Sports、World) 的 120K 文本样本
# Load data
url = "https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/news.csv"
df = pd.read_csv(url, header=0) # load
df = df.sample(frac=1).reset_index(drop=True) # shuffle
df.head()| 标题 | 类别 | |
|---|---|---|
| 0 | 沙龙接受减少加沙军队行动的计划...... | 世界 |
| 1 | 野生动物犯罪斗争中的互联网关键战场 | 科技 |
| 2 | 7 月耐用品订单增长 1.7% | 商业 |
| 3 | 华尔街放缓的迹象越来越多 | 商业 |
| 4 | 真人秀的新面孔 | 世界 |
预处理
我们将首先通过执行诸如下部文本、删除停止(填充)词、使用正则表达式的过滤器等操作来清理我们的输入数据。
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
import re
nltk.download("stopwords")
STOPWORDS = stopwords.words("english")
print (STOPWORDS[:5])
porter = PorterStemmer()[nltk_data] 正在将包停用词下载到 /root/nltk_data...
[nltk_data] 包停用词已经是最新的!
['我','我','我的','我自己','我们']
def preprocess(text, stopwords=STOPWORDS):
"""Conditional preprocessing on our text unique to our task."""
# Lower
text = text.lower()
# Remove stopwords
pattern = re.compile(r"\b(" + r"|".join(stopwords) + r")\b\s*")
text = pattern.sub("", text)
# Remove words in parenthesis
text = re.sub(r"\([^)]*\)", "", text)
# Spacing and filters
text = re.sub(r"([-;;.,!?<=>])", r" \1 ", text)
text = re.sub("[^A-Za-z0-9]+", " ", text) # remove non alphanumeric chars
text = re.sub(" +", " ", text) # remove multiple spaces
text = text.strip()
return text# Sample
text = "Great week for the NYSE!"
preprocess(text=text)纽约证券交易所伟大的一周
# Apply to dataframe
preprocessed_df = df.copy()
preprocessed_df.title = preprocessed_df.title.apply(preprocess)
print (f"{df.title.values[0]}\n\n{preprocessed_df.title.values[0]}")《国土报》称,沙龙接受减少加沙军队行动的计划
沙龙接受计划减少加沙军队 国土报说
拆分数据
import collections
from sklearn.model_selection import train_test_splitTRAIN_SIZE = 0.7
VAL_SIZE = 0.15
TEST_SIZE = 0.15def train_val_test_split(X, y, train_size):
"""Split dataset into data splits."""
X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)
X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)
return X_train, X_val, X_test, y_train, y_val, y_test# Data
X = preprocessed_df["title"].values
y = preprocessed_df["category"].values# Create data splits
X_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(
X=X, y=y, train_size=TRAIN_SIZE)
print (f"X_train: {X_train.shape}, y_train: {y_train.shape}")
print (f"X_val: {X_val.shape}, y_val: {y_val.shape}")
print (f"X_test: {X_test.shape}, y_test: {y_test.shape}")
print (f"Sample point: {X_train[0]} → {y_train[0]}")X_train: (84000,), y_train: (84000,)
X_val: (18000,), y_val: (18000,)
X_test: (18000,), y_test: (18000,)
样本点:中国与朝鲜核谈判作斗争 → 世界
标签编码
接下来,我们将定义 aLabelEncoder将我们的文本标签编码为唯一索引
class LabelEncoder(object):
"""Label encoder for tag labels."""
def __init__(self, class_to_index={}):
self.class_to_index = class_to_index or {} # mutable defaults ;)
self.index_to_class = {v: k for k, v in self.class_to_index.items()}
self.classes = list(self.class_to_index.keys())
def __len__(self):
return len(self.class_to_index)
def __str__(self):
return f"<LabelEncoder(num_classes={len(self)})>"
def fit(self, y):
classes = np.unique(y)
for i, class_ in enumerate(classes):
self.class_to_index[class_] = i
self.index_to_class = {v: k for k, v in self.class_to_index.items()}
self.classes = list(self.class_to_index.keys())
return self
def encode(self, y):
encoded = np.zeros((len(y)), dtype=int)
for i, item in enumerate(y):
encoded[i] = self.class_to_index[item]
return encoded
def decode(self, y):
classes = []
for i, item in enumerate(y):
classes.append(self.index_to_class[item])
return classes
def save(self, fp):
with open(fp, "w") as fp:
contents = {'class_to_index': self.class_to_index}
json.dump(contents, fp, indent=4, sort_keys=False)
@classmethod
def load(cls, fp):
with open(fp, "r") as fp:
kwargs = json.load(fp=fp)
return cls(**kwargs)
# Encode
label_encoder = LabelEncoder()
label_encoder.fit(y_train)
NUM_CLASSES = len(label_encoder)
label_encoder.class_to_index{“商业”:0,“科技”:1,“体育”:2,“世界”:3}
# Convert labels to tokens
print (f"y_train[0]: {y_train[0]}")
y_train = label_encoder.encode(y_train)
y_val = label_encoder.encode(y_val)
y_test = label_encoder.encode(y_test)
print (f"y_train[0]: {y_train[0]}")y_train[0]:世界
y_train[0]:3
# Class weights
counts = np.bincount(y_train)
class_weights = {i: 1.0/count for i, count in enumerate(counts)}
print (f"counts: {counts}\nweights: {class_weights}")计数:[21000 21000 21000 21000]
权重:{0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}
分词器
我们将定义一个Tokenizer将我们的文本输入数据转换为标记索引。
import json
from collections import Counter
from more_itertools import takeclass Tokenizer(object):
def __init__(self, char_level, num_tokens=None,
pad_token="<PAD>", oov_token="<UNK>",
token_to_index=None):
self.char_level = char_level
self.separator = "" if self.char_level else " "
if num_tokens: num_tokens -= 2 # pad + unk tokens
self.num_tokens = num_tokens
self.pad_token = pad_token
self.oov_token = oov_token
if not token_to_index:
token_to_index = {pad_token: 0, oov_token: 1}
self.token_to_index = token_to_index
self.index_to_token = {v: k for k, v in self.token_to_index.items()}
def __len__(self):
return len(self.token_to_index)
def __str__(self):
return f"<Tokenizer(num_tokens={len(self)})>"
def fit_on_texts(self, texts):
if not self.char_level:
texts = [text.split(" ") for text in texts]
all_tokens = [token for text in texts for token in text]
counts = Counter(all_tokens).most_common(self.num_tokens)
self.min_token_freq = counts[-1][1]
for token, count in counts:
index = len(self)
self.token_to_index[token] = index
self.index_to_token[index] = token
return self
def texts_to_sequences(self, texts):
sequences = []
for text in texts:
if not self.char_level:
text = text.split(" ")
sequence = []
for token in text:
sequence.append(self.token_to_index.get(
token, self.token_to_index[self.oov_token]))
sequences.append(np.asarray(sequence))
return sequences
def sequences_to_texts(self, sequences):
texts = []
for sequence in sequences:
text = []
for index in sequence:
text.append(self.index_to_token.get(index, self.oov_token))
texts.append(self.separator.join([token for token in text]))
return texts
def save(self, fp):
with open(fp, "w") as fp:
contents = {
"char_level": self.char_level,
"oov_token": self.oov_token,
"token_to_index": self.token_to_index
}
json.dump(contents, fp, indent=4, sort_keys=False)
@classmethod
def load(cls, fp):
with open(fp, "r") as fp:
kwargs = json.load(fp=fp)
return cls(**kwargs)# Tokenize
tokenizer = Tokenizer(char_level=False, num_tokens=5000)
tokenizer.fit_on_texts(texts=X_train)
VOCAB_SIZE = len(tokenizer)
print (tokenizer)<Tokenizer(num_tokens=5000)>
# Sample of tokens
print (take(5, tokenizer.token_to_index.items()))
print (f"least freq token's freq: {tokenizer.min_token_freq}") # use this to adjust num_tokens[('<pad>',0),('',1),('39',2),('b',3),('gt',4),]
最低频率令牌的频率:14
# Convert texts to sequences of indices
X_train = tokenizer.texts_to_sequences(X_train)
X_val = tokenizer.texts_to_sequences(X_val)
X_test = tokenizer.texts_to_sequences(X_test)
preprocessed_text = tokenizer.sequences_to_texts([X_train[0]])[0]
print ("Text to indices:\n"
f" (preprocessed) → {preprocessed_text}\n"
f" (tokenized) → {X_train[0]}")文本到索引:
(预处理)→ 中国与朝鲜核谈判作斗争
(代币化)→ [ 16 1491 285 142 114 24]
填充
我们需要对我们的标记化文本进行 2D 填充。
def pad_sequences(sequences, max_seq_len=0):
"""Pad sequences to max length in sequence."""
max_seq_len = max(max_seq_len, max(len(sequence) for sequence in sequences))
padded_sequences = np.zeros((len(sequences), max_seq_len))
for i, sequence in enumerate(sequences):
padded_sequences[i][:len(sequence)] = sequence
return padded_sequences# 2D sequences
padded = pad_sequences(X_train[0:3])
print (padded.shape)
print (padded)(3, 6)
[[1.600e+01 1.491e+03 2.850e+02 1.420e+02 1.140e+02 2.400e+01]
[1.445e+03 2.300e+01 6.560e+02 2.197e+03 1.000e+00 0.000e+00]
[1.200e+02 1.400e+01 1.955e+03 1.005e+03 1.529e+03 4.014e+03]]
数据集
我们将创建数据集和数据加载器,以便能够使用我们的数据拆分有效地创建批次。
class Dataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.y)
def __str__(self):
return f"<Dataset(N={len(self)})>"
def __getitem__(self, index):
X = self.X[index]
y = self.y[index]
return [X, len(X), y]
def collate_fn(self, batch):
"""Processing on a batch."""
# Get inputs
batch = np.array(batch)
X = batch[:, 0]
seq_lens = batch[:, 1]
y = batch[:, 2]
# Pad inputs
X = pad_sequences(sequences=X)
# Cast
X = torch.LongTensor(X.astype(np.int32))
seq_lens = torch.LongTensor(seq_lens.astype(np.int32))
y = torch.LongTensor(y.astype(np.int32))
return X, seq_lens, y
def create_dataloader(self, batch_size, shuffle=False, drop_last=False):
return torch.utils.data.DataLoader(
dataset=self, batch_size=batch_size, collate_fn=self.collate_fn,
shuffle=shuffle, drop_last=drop_last, pin_memory=True)
# Create datasets
train_dataset = Dataset(X=X_train, y=y_train)
val_dataset = Dataset(X=X_val, y=y_val)
test_dataset = Dataset(X=X_test, y=y_test)
print ("Datasets:\n"
f" Train dataset:{train_dataset.__str__()}\n"
f" Val dataset: {val_dataset.__str__()}\n"
f" Test dataset: {test_dataset.__str__()}\n"
"Sample point:\n"
f" X: {train_dataset[0][0]}\n"
f" seq_len: {train_dataset[0][1]}\n"
f" y: {train_dataset[0][2]}")
数据集:
训练数据集:<Dataset(N=84000)>
验证数据集:<数据集(N=18000)>
测试数据集:<Dataset(N=18000)>
采样点:
X:[16 1491 285 142 114 24]
seq_len:
和: 3# Create dataloaders
batch_size = 64
train_dataloader = train_dataset.create_dataloader(
batch_size=batch_size)
val_dataloader = val_dataset.create_dataloader(
batch_size=batch_size)
test_dataloader = test_dataset.create_dataloader(
batch_size=batch_size)
batch_X, batch_seq_lens, batch_y = next(iter(train_dataloader))
print ("Sample batch:\n"
f" X: {list(batch_X.size())}\n"
f" seq_lens: {list(batch_seq_lens.size())}\n"
f" y: {list(batch_y.size())}\n"
"Sample point:\n"
f" X: {batch_X[0]}\n"
f" seq_len: {batch_seq_lens[0]}\n"
f" y: {batch_y[0]}")
样品批次:
X: [64, 14]
seq_lens:[64]
和: [64]
采样点:
X:张量([ 16, 1491, 285, 142, 114, 24, 0, 0, 0, 0, 0, 0,
0, 0])
seq_len:
和: 3培训师
让我们创建一个Trainer类,我们将使用它来促进我们的实验训练。
class Trainer(object):
def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):
# Set params
self.model = model
self.device = device
self.loss_fn = loss_fn
self.optimizer = optimizer
self.scheduler = scheduler
def train_step(self, dataloader):
"""Train step."""
# Set model to train mode
self.model.train()
loss = 0.0
# Iterate over train batches
for i, batch in enumerate(dataloader):
# Step
batch = [item.to(self.device) for item in batch] # Set device
inputs, targets = batch[:-1], batch[-1]
self.optimizer.zero_grad() # Reset gradients
z = self.model(inputs) # Forward pass
J = self.loss_fn(z, targets) # Define loss
J.backward() # Backward pass
self.optimizer.step() # Update weights
# Cumulative Metrics
loss += (J.detach().item() - loss) / (i + 1)
return loss
def eval_step(self, dataloader):
"""Validation or test step."""
# Set model to eval mode
self.model.eval()
loss = 0.0
y_trues, y_probs = [], []
# Iterate over val batches
with torch.inference_mode():
for i, batch in enumerate(dataloader):
# Step
batch = [item.to(self.device) for item in batch] # Set device
inputs, y_true = batch[:-1], batch[-1]
z = self.model(inputs) # Forward pass
J = self.loss_fn(z, y_true).item()
# Cumulative Metrics
loss += (J - loss) / (i + 1)
# Store outputs
y_prob = torch.sigmoid(z).cpu().numpy()
y_probs.extend(y_prob)
y_trues.extend(y_true.cpu().numpy())
return loss, np.vstack(y_trues), np.vstack(y_probs)
def predict_step(self, dataloader):
"""Prediction step."""
# Set model to eval mode
self.model.eval()
y_probs = []
# Iterate over val batches
with torch.inference_mode():
for i, batch in enumerate(dataloader):
# Forward pass w/ inputs
inputs, targets = batch[:-1], batch[-1]
y_prob = F.softmax(model(inputs), dim=1)
# Store outputs
y_probs.extend(y_prob)
return np.vstack(y_probs)
def train(self, num_epochs, patience, train_dataloader, val_dataloader):
best_val_loss = np.inf
for epoch in range(num_epochs):
# Steps
train_loss = self.train_step(dataloader=train_dataloader)
val_loss, _, _ = self.eval_step(dataloader=val_dataloader)
self.scheduler.step(val_loss)
# Early stopping
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = self.model
_patience = patience # reset _patience
else:
_patience -= 1
if not _patience: # 0
print("Stopping early!")
break
# Logging
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.5f}, "
f"val_loss: {val_loss:.5f}, "
f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "
f"_patience: {_patience}"
)
return best_model
注意力
注意应用于 RNN 的输出。理论上,输出可以来自我们想学习如何在它们之间加权的任何地方,但是由于我们正在使用上一课中的 RNN 的上下文,我们将继续这样做。
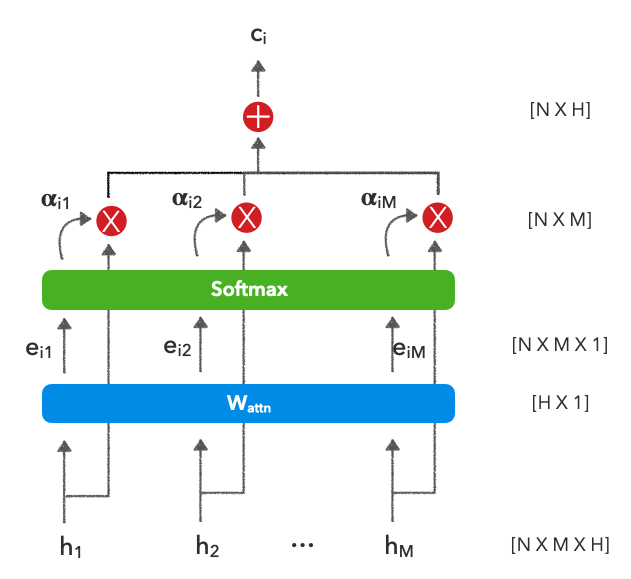
| 多变的 | 描述 |
|---|---|
| ñ | 批量大小 |
| 米 | 批处理中的最大序列长度 |
| H | 隐藏的暗淡,模型暗淡等。 |
| H | RNN 输出(或您想要关注的任何输出组)∈RñX米XH |
| 一个吨,一世 | 对齐函数上下文向量C吨(在我们的例子中注意)$ |
| 在一个吨吨n | 学习的注意力权重∈RHX1 |
| C吨 | 考虑不同输入的上下文向量 |
import torch.nn.functional as FRNN 将为我们输入中的每个单词创建一个编码表示,从而产生一个具有维度的堆叠向量ñX米XH,其中 N 是批次中的样本数,M 是批次中的最大序列长度,H 是 RNN 中隐藏单元的数量。
BATCH_SIZE = 64
SEQ_LEN = 8
EMBEDDING_DIM = 100
RNN_HIDDEN_DIM = 128# Embed
x = torch.rand((BATCH_SIZE, SEQ_LEN, EMBEDDING_DIM))# Encode
rnn = nn.RNN(EMBEDDING_DIM, RNN_HIDDEN_DIM, batch_first=True)
out, h_n = rnn(x) # h_n is the last hidden state
print ("out: ", out.shape)
print ("h_n: ", h_n.shape)输出:torch.Size([64, 8, 128])
h_n: torch.Size([1, 64, 128])
# Attend
attn = nn.Linear(RNN_HIDDEN_DIM, 1)
e = attn(out)
attn_vals = F.softmax(e.squeeze(2), dim=1)
c = torch.bmm(attn_vals.unsqueeze(1), out).squeeze(1)
print ("e: ", e.shape)
print ("attn_vals: ", attn_vals.shape)
print ("attn_vals[0]: ", attn_vals[0])
print ("sum(attn_vals[0]): ", sum(attn_vals[0]))
print ("c: ", c.shape)# Predict
fc1 = nn.Linear(RNN_HIDDEN_DIM, NUM_CLASSES)
output = F.softmax(fc1(c), dim=1)
print ("output: ", output.shape)输出:torch.Size([64, 4])
模型
现在让我们创建基于 RNN 的模型,但在 RNN 的输出之上添加了注意力层。
RNN_HIDDEN_DIM = 128
DROPOUT_P = 0.1
HIDDEN_DIM = 100class RNN(nn.Module):
def __init__(self, embedding_dim, vocab_size, rnn_hidden_dim,
hidden_dim, dropout_p, num_classes, padding_idx=0):
super(RNN, self).__init__()
# Initialize embeddings
self.embeddings = nn.Embedding(
embedding_dim=embedding_dim, num_embeddings=vocab_size,
padding_idx=padding_idx)
# RNN
self.rnn = nn.RNN(embedding_dim, rnn_hidden_dim, batch_first=True)
# Attention
self.attn = nn.Linear(rnn_hidden_dim, 1)
# FC weights
self.dropout = nn.Dropout(dropout_p)
self.fc1 = nn.Linear(rnn_hidden_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, inputs):
# Embed
x_in, seq_lens = inputs
x_in = self.embeddings(x_in)
# Encode
out, h_n = self.rnn(x_in)
# Attend
e = self.attn(out)
attn_vals = F.softmax(e.squeeze(2), dim=1)
c = torch.bmm(attn_vals.unsqueeze(1), out).squeeze(1)
# Predict
z = self.fc1(c)
z = self.dropout(z)
z = self.fc2(z)
return z# Simple RNN cell
model = RNN(
embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,
rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,
dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)
model = model.to(device) # set device
print (model.named_parameters)训练
from torch.optim import AdamNUM_LAYERS = 1
LEARNING_RATE = 1e-4
PATIENCE = 10
NUM_EPOCHS = 50# Define Loss
class_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)
loss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)# Define optimizer & scheduler
optimizer = Adam(model.parameters(), lr=LEARNING_RATE)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode="min", factor=0.1, patience=3)# Trainer module
trainer = Trainer(
model=model, device=device, loss_fn=loss_fn,
optimizer=optimizer, scheduler=scheduler)# Train
best_model = trainer.train(
NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)评估
import json
from sklearn.metrics import precision_recall_fscore_support
def get_metrics(y_true, y_pred, classes):
"""Per-class performance metrics."""
# Performance
performance = {"overall": {}, "class": {}}
# Overall performance
metrics = precision_recall_fscore_support(y_true, y_pred, average="weighted")
performance["overall"]["precision"] = metrics[0]
performance["overall"]["recall"] = metrics[1]
performance["overall"]["f1"] = metrics[2]
performance["overall"]["num_samples"] = np.float64(len(y_true))
# Per-class performance
metrics = precision_recall_fscore_support(y_true, y_pred, average=None)
for i in range(len(classes)):
performance["class"][classes[i]] = {
"precision": metrics[0][i],
"recall": metrics[1][i],
"f1": metrics[2][i],
"num_samples": np.float64(metrics[3][i]),
}
return performance
# Get predictions
test_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)
y_pred = np.argmax(y_prob, axis=1)
# Determine performance
performance = get_metrics(
y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)
print (json.dumps(performance["overall"], indent=2))
推理
def get_probability_distribution(y_prob, classes):
"""Create a dict of class probabilities from an array."""
results = {}
for i, class_ in enumerate(classes):
results[class_] = np.float64(y_prob[i])
sorted_results = {k: v for k, v in sorted(
results.items(), key=lambda item: item[1], reverse=True)}
return sorted_results
# Load artifacts
device = torch.device("cpu")
label_encoder = LabelEncoder.load(fp=Path(dir, "label_encoder.json"))
tokenizer = Tokenizer.load(fp=Path(dir, 'tokenizer.json'))
model = GRU(
embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,
rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,
dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)
model.load_state_dict(torch.load(Path(dir, "model.pt"), map_location=device))
model.to(device)
# Initialize trainer
trainer = Trainer(model=model, device=device)
# Dataloader
text = "The final tennis tournament starts next week."
X = tokenizer.texts_to_sequences([preprocess(text)])
print (tokenizer.sequences_to_texts(X))
y_filler = label_encoder.encode([label_encoder.classes[0]]*len(X))
dataset = Dataset(X=X, y=y_filler)
dataloader = dataset.create_dataloader(batch_size=batch_size)
['决赛网球锦标赛下周开始']# Inference
y_prob = trainer.predict_step(dataloader)
y_pred = np.argmax(y_prob, axis=1)
label_encoder.decode(y_pred)['运动的']# Class distributions
prob_dist = get_probability_distribution(y_prob=y_prob[0], classes=label_encoder.classes)
print (json.dumps(prob_dist, indent=2)){
“体育”:0.9651875495910645,
“世界”:0.03468644618988037,
《科技》:8.490968320984393e-05,
《商务》:4.112234091735445e-05
}可解释性
让我们使用注意力值来查看哪些编码标记在预测适当的标签时最有用。
import collections
import seaborn as snsclass InterpretAttn(nn.Module):
def __init__(self, embedding_dim, vocab_size, rnn_hidden_dim,
hidden_dim, dropout_p, num_classes, padding_idx=0):
super(InterpretAttn, self).__init__()
# Initialize embeddings
self.embeddings = nn.Embedding(
embedding_dim=embedding_dim, num_embeddings=vocab_size,
padding_idx=padding_idx)
# RNN
self.rnn = nn.RNN(embedding_dim, rnn_hidden_dim, batch_first=True)
# Attention
self.attn = nn.Linear(rnn_hidden_dim, 1)
# FC weights
self.dropout = nn.Dropout(dropout_p)
self.fc1 = nn.Linear(rnn_hidden_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, inputs):
# Embed
x_in, seq_lens = inputs
x_in = self.embeddings(x_in)
# Encode
out, h_n = self.rnn(x_in)
# Attend
e = self.attn(out) # could add optional activation function (ex. tanh)
attn_vals = F.softmax(e.squeeze(2), dim=1)
return attn_vals
# Initialize model
interpretable_model = InterpretAttn(
embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,
rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,
dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)
interpretable_model.load_state_dict(torch.load(Path(dir, "model.pt"), map_location=device))
interpretable_model.to(device)
# Initialize trainer
interpretable_trainer = Trainer(model=interpretable_model, device=device)
# Get attention values
attn_vals = interpretable_trainer.predict_step(dataloader)
print (attn_vals.shape) # (N, max_seq_len)# Visualize a bi-gram filter's outputs
sns.set(rc={"figure.figsize":(10, 1)})
tokens = tokenizer.sequences_to_texts(X)[0].split(" ")
sns.heatmap(attn_vals, xticklabels=tokens)
这个词tennis得到了最多的关注以产生Sports标签。
关注类型
我们将简要介绍不同类型的注意力以及何时使用它们。
软(全局)关注
Soft attention 到目前为止我们已经实现的注意力类型,我们在创建上下文向量时关注所有编码的输入。
- 优点:我们总是有能力关注所有输入,以防我们更早看到/稍后看到的东西对于确定输出至关重要。
- 缺点:如果我们的输入序列很长,这可能会导致昂贵的计算。
硬注意力
硬注意力集中在每个时间步长的一组特定编码输入上。
- 优点:我们可以通过每次只关注一个本地补丁来节省大量的长序列计算。
- 缺点:不可微分,因此我们需要使用更复杂的技术(方差减少、强化学习等)来训练。

当地关注
局部注意力融合了软注意力和硬注意力的优点。它涉及学习对齐的位置向量并根据经验确定要处理的编码输入的本地窗口。
- 优点:关注输入的局部补丁,但仍可区分。
- 缺点:需要确定每个输出的对齐向量,但为了避免关注所有输入,确定要关注的正确输入窗口是值得权衡的。
自注意力
我们还可以在编码的输入序列中使用注意力来创建基于输入对之间相似性的加权表示。这将使我们能够创建了解彼此之间关系的输入序列的丰富表示。例如,在下图中,您可以看到在组成标记“its”的表示时,这个特定的注意力头将合并来自标记“Law”的信号(据了解,“its”指的是“Law” )。

相关文章
- YOLOv7改进之二十三:引入SimAM无参数注意力
- [YOLOv7/YOLOv5系列算法改进NO.4]添加ECA通道注意力机制
- [YOLOv7/YOLOv5系列算法改进NO.33]引入GAMAttention注意力机制
- YOLOv5、v7改进之三十一:CrissCrossAttention注意力机制
- DL之self-attention:self-attention自注意力机制模块思路的8个步骤及其代码实现
- 注意力机制的本质中文版代码
- 使用训练数据结构代替注意力机制
- 【第58篇】DEiT:通过注意力训练数据高效的图像transformer &蒸馏
- 【第22篇】CoAtNet:将卷积和注意力结合到所有数据大小上
- 【ChatGPT】 AI 手把手一步一步教学 Self-Attention:这些动图和代码让你一次读懂ChatGPT背后的“自注意力”
- 【ChatGPT】《ChatGPT 算法原理与实战》1: 引言:从 CNN、RNN 到 Transformers 架构、自注意力机制(图文+数学公式+代码实例详解)
- 注意力机制和Transformer原理,其他文章看不懂就看这个吧,根据《python深度学习》 和 《动手学深度学习》两本书总结而成
- 目标检测算法——YOLOv5/YOLOv7改进之结合无参注意力SimAM(涨点神器)
- External Attention 据说这个机制可以较少参数超越注意力机制
- 注意力公式步骤每一步的含义,总共三步
- 改进YOLOv5系列:14.添加S2-MLPv2注意力机制
- 改进YOLOv5系列:13.添加CrissCrossAttention注意力机制
- 第三周 序列模型和注意力机制(Sequence models & Attention mechanism)
- 目标检测论文解读复现之十二:基于注意力机制和上下文信息的目标检测算法