
python对英雄皮肤进行图片采集~
Python 进行 图片 采集 英雄 皮肤
2023-09-14 09:05:36 时间
前言
嗨喽~大家好呀,这里是魔王呐
环境使用:
-
Python 3.8
-
Pycharm
模块使用:
-
requests —> 数据请求模块 需要安装 pip install requests
-
re 正则表达式 内置模块 不需要安装
-
os 文件操作模块 内置模块 不需要安装 --> 自动创建文件夹 把每个英雄都自动创建对应文件
基本套路
一. 数据来源分析
-
确定需求, 确定采集目标
-
通过开发者工具抓包分析, 分析我们想要数据内容来自于那个url地址
-
F12 或者 鼠标右键点击检查 选择 network(网络) 刷新网页
-
去分析图片url地址是什么 —> 选择 Img 可以查找图片url地址
505 表示英雄ID
2 皮肤第几个 —> 通过皮肤名字对应他的皮肤链接

想要获取 yao 皮肤数据
- 向网址发送请求
- 获取response响应数据
- 提取皮肤名字
- 构建 皮肤 url地址
- 保存数据
二. 代码实现步骤
- 发送请求, 模拟浏览器对于url地址发送请求
- 获取数据, 获取服务器返回响应数据
- 解析数据, 提取我们想要内容, 皮肤名字
- 保存数据, 数据保存本地

代码
# 导入数据请求模块 ---> 第三方模块 需要 在cmd里面进行安装 pip install requests
import requests
# 导入正则模块 ---> 内置模块 不需要安装
import re
# 导入文件操作模块 ---> 内置模块 不需要安装
import os
# 确定网址
link = 'https://pvp.**.com/web201605/js/herolist.json'
# 模拟伪装浏览器 ---> 请求头
headers = {
# user-agent 用户代理 表示浏览器基本身份标识
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
json_data = requests.get(url=link, headers=headers).json()
# for循环遍历
for index in json_data:
# 字典键值对取值 根据冒号左边的内容[键],提取冒号右边的内容[值]
hero_id = index['ename']
hero_name = index['cname']
# 设定文件夹路径 相对路径
file = f'img\\{hero_name}\\'
if not os.path.exists(file):
os.makedirs(file)
"""
1. 发送请求, 模拟浏览器对于url地址发送请求
- headers 字典数据类型, 构建完整键值对
- 请求头参数 可以直接在开发者工具复制粘贴
- 使用什么请求方法, 根据开发者工具来
"""
# 确定请求url地址
url = f'https://pvp.**.com/web201605/herodetail/{hero_id}.shtml'
# 模拟伪装浏览器 ---> 请求头
headers = {
# user-agent 用户代理 表示浏览器基本身份标识
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求 ---> <Response [200]> 响应对象: <>表示对象 response 响应回复 200 状态码 表示请求成功
response = requests.get(url=url, headers=headers)
# 乱码了 怎么办? ---> 你要根据网页编码来 response.encoding = 'gbk'
# 自动识别编码
response.encoding = response.apparent_encoding
# 获取数据, 获取服务器返回响应数据 文本数据 print(response.text)
"""
解析数据 re正则 会1 不会2
re.findall() 从什么地方 去找什么数据
从 response.text 里面 去找 data-imgname="(.*?)"> 其中 (.*?) 就是我们要的数据
"""
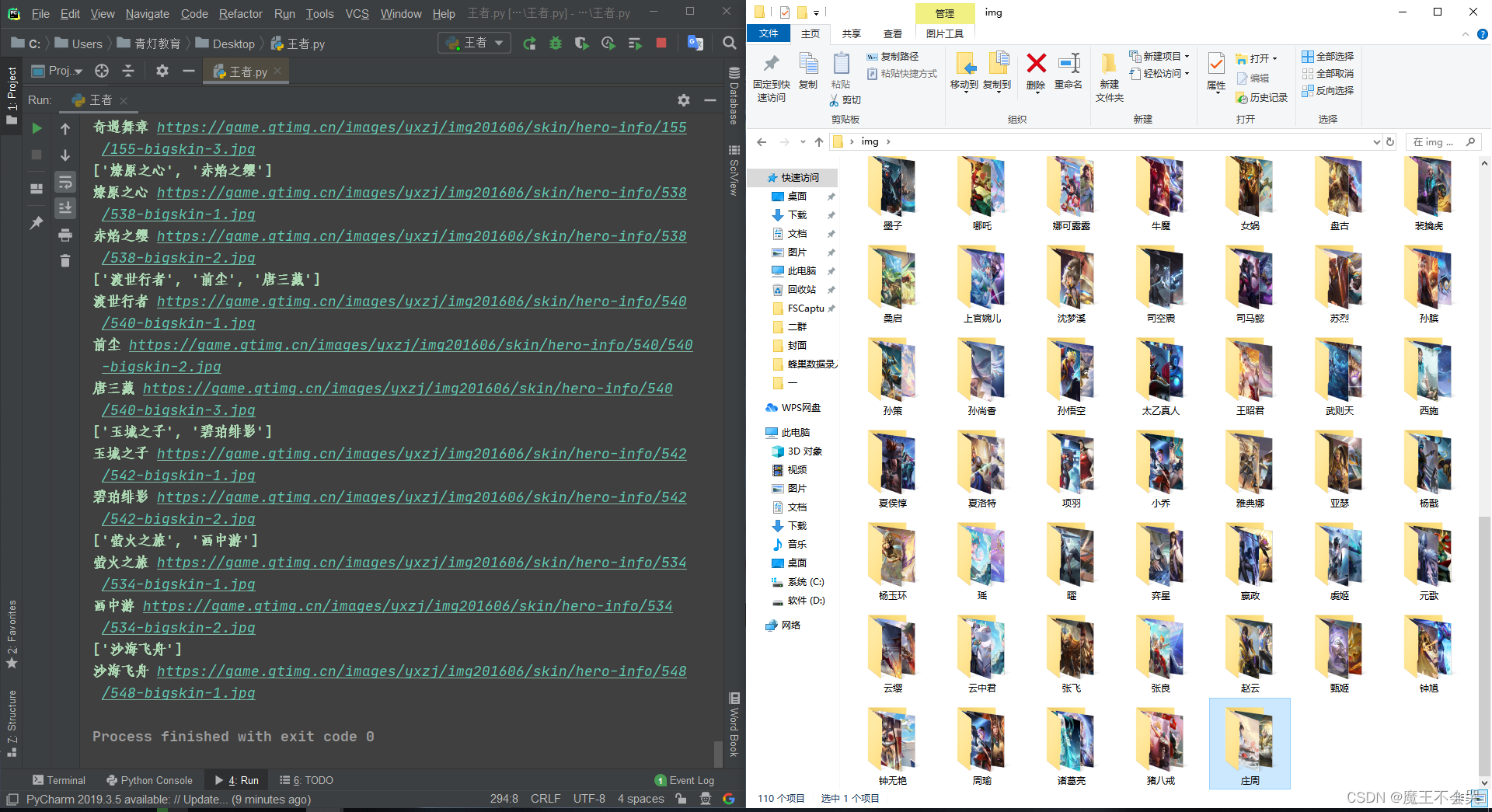
title_list = re.findall('data-imgname="(.*?)">', response.text)[0]
# 鹿灵守心&0|森&0|遇见神鹿&71|时之祈愿&94|时之愿境&42
title_list = re.sub('&\d+', '', title_list).split('|')
print(title_list)
# for循环 for num in range(1, 6): len() 统计列表元素个数
for num in range(1, len(title_list) +1):
# 列表取值, 根据索引位置,索引位置从0开始计数
img_name = title_list[num-1]
# 构建图片url地址
img_url = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{hero_id}/{hero_id}-bigskin-{num}.jpg'
print(img_name, img_url)
# 保存数据 ---> 发送请求 获取数据 二进制数据
img_content = requests.get(url=img_url, headers=headers).content
with open(file + img_name + '.jpg', mode='wb') as f:
f.write(img_content)








尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝

相关文章
- 使用Python进行描述性统计
- 基于Python中numpy数组的合并实例讲解
- Template类的使用指南【python】
- 使用Python的PIL模块来进行图片对比
- Open3D 点云按高程进行渲染赋色 (python详细过程版)
- 使用Python rembg库进行抠图:一行命令就搞定
- Python编程语言学习:基于python各种库(matplotlib、Image)利用多种方法展示图片或进行图片可视化之详细攻略
- IPython:利用python语言将后缀为ipynb文件中的输出的图片在py文件中编程进行可视化—即如何将IPython.core.display.HTML类型的数据进行图表可视化
- 已解决(Pycharm切换Python版本后报错)No Python at”C:Program FiLesPython39pythen.exe‘
- 60行代码出炫酷效果之 python语音控制电脑壁纸切换
- 知道Python中的字符串是什么吗?
- Python:使用pydantic库进行数据校验
- Python编程:使用unittest模块进行单元测试
- Python编程:使用gensim对中文文本进行相似度计算
- Python编程:glob模块进行文件名模式匹配
- Python对音频进行测试及频谱分析
- python基础===利用unittest进行测试用例执行的几种方式
- pytorch 29 onnx多输入多输出模型(动态尺寸)转TensorRT模型并在python与C++下用TensorRT进行部署
- Python爬虫进行BeautifulSoup数据解析实战