
机器使用成本下降 50%,TDengine 在同程旅行基础监控中的实践
小 T 导读:在对多款时序数据库进行了选型测试后,同程旅行自研的“夜鹰监控”搭载 TDengine Database 代替了现有存储设备,减少运维成本。本文分享了他们对建表模型的方案选择思路,接入 TDengine 后所遇到问题的解决经验以及落地效果展示。
同程旅行有一套自研的基础监控系统“夜鹰监控”。目前夜鹰监控使用情况为百万级别 endpoint、亿级 metric、每秒 200 万并发写入以及 2 万并发查询。其存储组件基于 RRD 存储,RRD 存储虽然拥有很好的性能,却也存在着一些问题——基于内存缓存定期写入 RRD,在机器重启后会丢失部分数据。
出现这一问题的原因是 RRD 写入为单点写入,当机器故障后无法实现自动切换,这一存储特性也导致无法展示更长时间的原始数据。 针对此问题,夜鹰监控做了很多高可用设计,但还是很难满足业务的需求,之后又进行了如下改造:
- 引入了 ES 存储,为夜鹰监控提供 7 天内原始数据的查询,目前部署的 2 套存储。
- RRD 提供给 API 调用,调用量在几万级 TPS。
- ES 提供给夜鹰面板使用,保存 7 天原始数据,调用量在几百 QPS。
但随着基础监控系统接入指标的增长,目前 2 套存储系统在资源消耗方面一直在增长,同时业务对监控也提出了更多的聚合计算功能要求。基于此,我们需要寻找一个新的时序数据库来代替现有的存储系统,以减少运维成本。
在进行时序数据库选型时,实际需求主要有以下三点:
- 性能强,可以支持千万级别并发写入、10 万级的并发读取
- 高可用,可以横向扩展,不存在单点故障
- 功能强,提供四则运算、最大、最小、平均、最新等聚合计算功能
通过对比 InfluxDB、TDengine、Prometheus、Druid、ClickHouse 等多款市面流行的时序数据库(Time-Series Database)产品后,最终 TDengine 从中脱颖而出,能满足我们所有的选型要求。
一、基于 TDengine 的建表模型
夜鹰监控系统不仅存在系统指标数据,同时也会存在业务指标数据。前者诸如 CPU、内存、磁盘、网络一类,这类信息是可以预测的指标,其指标名是固定的,总数约为 2000 万个。后者则会通过夜鹰监控的 API 上传业务自身定义的指标,指标名是无法预测的,其特点是并发量不大却存在长尾效应,随着时间累积,一年可以达到一亿级。
而 TDengine 在创建表之前需要先规划表的结构,从上面的数据存储背景来看,如果要将海量的指标数量直接一次性扁平化全部创建,则会造成性能的下降。通过和 TDengine Database 技术支持人员沟通,他们给出了两个建表方案:
其一,将系统类基础指标聚合到一个超级表,一张表存放一个节点,多个指标一次性写入。这个方式的好处是表的数量可以降低到千万级别,但因为夜鹰监控的数据是单条上传的,很难做到一个表里面全部指标集齐再写入。并且不同的指标上传频率不同,如果再根据频率建不同的超级表,运维管理成本会非常高。
其二,将不同的指标建成一个一个的子表,5 千万个左右的指标汇聚成一个集群,分多个集群接入。这种方式的好处是表结构简单,但运维管理多个集群会很麻烦。不过我们也了解到涛思数据明年会发布 TDengine 3.0 版本,能支持超过上亿张表,那么这一方案就可以很好的进行数据迁移了。
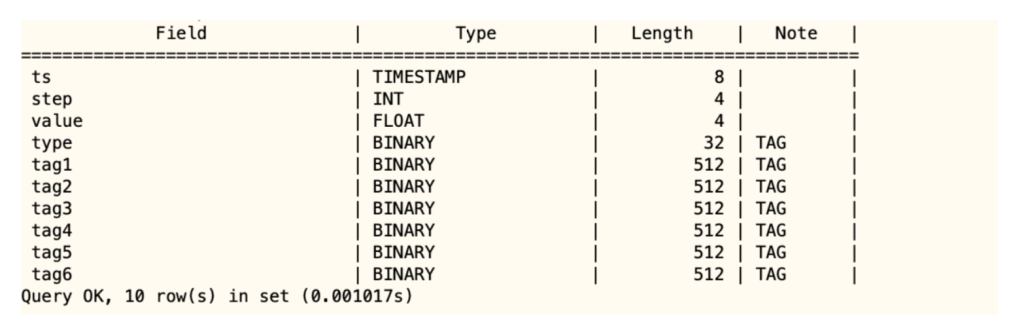
最终,我们选择了第二个方案。同时为了减少搭建集群的数量,准备写个程序定期清理掉过期的子表。目前夜鹰监控的超级表结构如下。
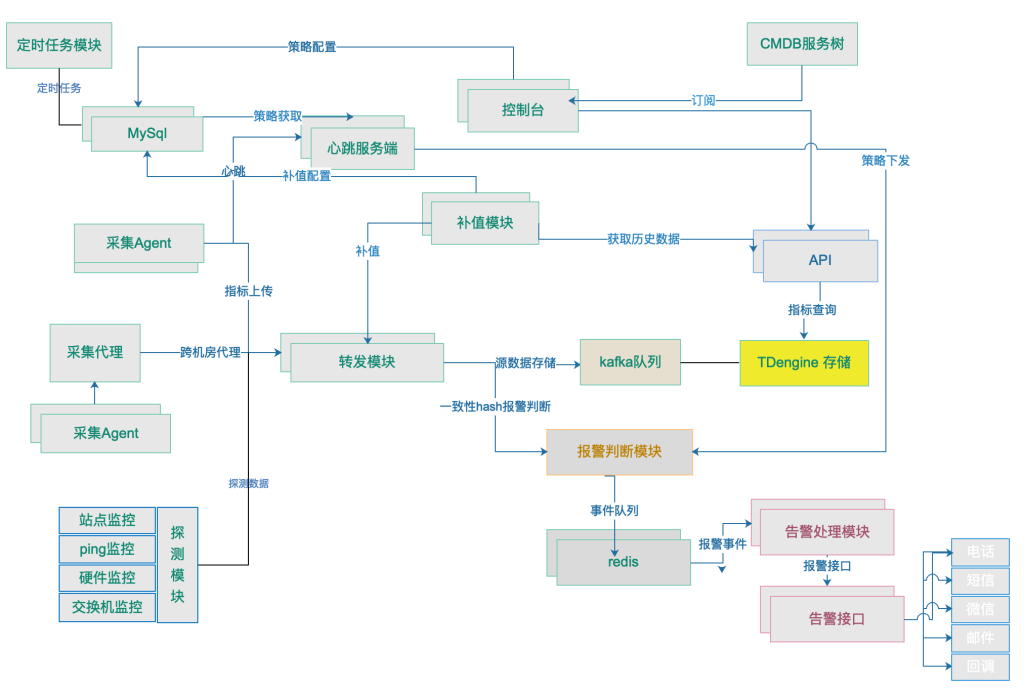
夜鹰监控接入 TDengine 后,架构图如下。
二、接入 TDengine 之后的效果展示
在进行数据迁移时,我们先是将夜鹰监控数据转移到 Kafka 中,之后通过消费转换程序将 Kafka 的数据格式转为了 TDengine SQL 格式。 这个过程还遇到了如下三个小问题,解决思路放在这里给大家参考:
- 连接方式问题。刚开始我们使用的是 go-connector sdk 的方式接入 TDengine,跑起来后发现,go-connector 依赖于 taos client 包以及 taos.cfg 配置文件里面的链接配置,同时因为 FQDN 的设置难以使用 VIP 负载均衡的配置方式。我们考虑到后面消费程序会部署到容器中,不宜产生过多的依赖,因此还是放弃了 go-connector 的连接方式,改为了 HTTP RESTful 的连接方式。
- Kafka 消费数量问题。由于夜鹰监控上传到 Kafka 里面的数据是一条一个指标,再加上 200 万左右的并发,连接数很快就耗光了。通过和 TDengine 技术支持人员沟通,了解到可以改造成批量 SQL 的方式写入,最佳的实践效果是 400-600K 单个 SQL 的长度。经过计算,我们上传的指标条数大概为 5000 条左右,大小为 500K 。
- 读取速度问题。因为每次要等到消费 5000 条数据,才会触发一次写入,这种情况也导致读取速度较慢。TDengine 技术支持人员再次给出了解决方案——使用 Taos 自己实现的 Queue,代码地址为:github.com/taosdata/go-demo-kafka/pkg/queue ,有需要的同学可以自行获取。
聚焦到实际效果上,TDengine 数据写入性能很强。原本我们的单套存储系统需要 10 多台高配机器,IO 平均 30% 最高 100% 的情况下才能写完数据;现在只需要 7 台机器,并且 CPU 消耗在 10% 左右、磁盘 IO 消耗在 1% 左右,这点非常的棒!

同时,其数据读取接入过程也很顺利。使用 RESTful 接口后,结合 TDengine 自带的强大聚合函数功能,很容易就能计算出想要的结果。
三、写在最后
在我们的项目中,TDengine Database 展现出了超强的性能和多元化的功能,不仅具备高效的写入性能、压缩率,其聚合函数功能也非常齐全,支持 Sum/Max/Min/Avg/Top/Last/First/Diff/Percentile 等多种函数,在架构上也设计的很合理,可以实现很好地横向扩展。同时,其自身监控也做的很不错,打造了基于 Grafana 的 TDengine 零依赖监控解决方案 TDinsight,在监控系统自身状态上展现出了很好的效果。
未来,我们也希望与 TDengine 展开更深层次的合作,在此也为其提出一些小小的建议,助力 TDengine 往更好的方向发展:
- 官方文档还不够完善,新版的功能在文档中没有体现,很多用法缺少代码示例,个人理解起来比较晦涩难懂
- 社区用户经验传递不是很多, 遇到一些问题时,Google 比较难以找到社区的解决案例
在接入的过程中,非常感谢 TDengine Database 的技术支持人员的全力支持。虽然目前 TDengine 还处于发展初期,也存在一些问题需要优化,不过其优异的性能还是给了我们一个大大的惊喜!总而言之,TDengine 是个非常不错的存储系统,相信在陶老师的带领下会发展的越来越好!
想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。

相关文章
- 机器学习算法总结(二)
- 使用ARP欺骗, 截取局域网中任意一台机器的网页请求,破解用户名密码等信息
- R语言与机器学习学习笔记
- 利用机器账户进行域权限维持
- 机器学习笔记:k近邻算法介绍及基于scikit-learn的实验
- 机器学习笔记 - 时间序列预测研究:法国香槟的月销量
- 机器学习笔记 - SVD奇异值分解(3) 在图像上应用 SVD
- 机器学习笔记 - 图解对象检测任务(1)
- 机器学习笔记 - 探索性数据分析(EDA) 学习进阶
- 【机器学习】机器学习算法总结
- Atitit 机器学习算法分类 五大分类v5 t56.docx Atitit 机器学习算法分类 目录 1. 传统的机器学习算法 vs 深度学习1 1.1. 传统的机器学习算法包括决策树、聚类、贝
- atitit 文件搜索 映象文件夹结构模式.docxAtitit 百度网盘 文件 与跨机器 文件 搜索 查询 检索 解决方案 最小化索引法 映象文件夹结构模式. 1. 生成文件夹 结构信息1
- ML之ME/LF:机器学习之风控业务中常用模型监控指标CSI(特征稳定性指标)的简介、使用方法、案例应用之详细攻略
- 机器学习(十五):异常检测之隔离森林算法(IsolationForest)
- 机器学习sklearn 计算recall , precison , F1
- 加州理工大学公开课:机器学习与数据挖掘_线性模型(第三个教训)
- SSRF——服务端请求伪造,根因是file_get_contents,fsockopen,curl_exec函数调用,类似远程文件包含,不过是内网机器
- 【数据挖掘】2022年2023届秋招奇虎360机器学习算法工程师 笔试题
- 【Android机器学习实战】3、定制可点击View、目标检测、以图搜图实战
- ML之ME:机器学习之风控业务中常用模型评估指标PSI(人群偏移度指标)的的简介、使用方法、案例应用之详细攻略
- 最新综述:图像分类中的对抗机器学习