
Hudi(21):Hudi集成Flink之核心原理分析
目录
0. 相关文章链接
1. 数据去重原理
Hoodie 的数据去重分两步:
(1)写入前攒 buffer 阶段去重,核心接口HoodieRecordPayload#preCombine
(2)写入过程中去重,核心接口HoodieRecordPayload#combineAndGetUpdateValue。
1.1. 消息版本新旧
相同 record key (主键)的数据通过write.precombine.field 指定的字段来判断哪个更新,即 precombine 字段更大的 record 更新,如果是相等的 precombine 字段,则后来的数据更新。
从 0.10 版本开始,write.precombine.field 字段为可选,如果没有指定,会看 schema 中是否有 ts 字段,如果有,ts 字段被选为 precombine 字段;如果没有指定,schema 中也没有 ts 字段,则为处理顺序:后来的消息默认较新。
1.2. 攒消息阶段的去重
Hoodie 将 buffer 消息发给 write handle 之前可以执行一次去重操作,通过HoodieRecordPayload#preCombine 接口,保留 precombine 字段较大的消息,此操作为纯内存的计算,在同一个 write task 中为单并发执行。注意:write.precombine 选项控制了攒消息的去重。
1.3. 写 parquet 增量消息的去重
在Hoodie 写入流程中,Hoodie 每写一个 parquet 都会有 base + 增量 merge 的过程,增量的消息会先放到一个 spillable map 的数据结构构建内存 index,这里的增量数据如果没有提前去重,那么同 key 的后来消息会直接覆盖先来的消息。Writer 接着扫 base 文件,过程中会不断查看内存 index 是否有同 key 的新消息,如果有,会走 HoodieRecordPayload#combineAndGetUpdateValue 接口判断保留哪个消息。
注意: MOR 表的 compaction 阶段和 COW 表的写入流程都会有 parquet 增量消息去重的逻辑。
1.4. 跨 partition 的消息去重
默认情况下,不同的 partition 的消息是不去重的,即相同的 key 消息,如果新消息换了 partition,那么老的 partiiton 消息仍然保留。开启 index.global.enabled 选项开启跨 partition 去重,原理是先往老的 partiton 发一条删除消息,再写新 partition。
2. 表写入原理
分为三个模块:数据写入、数据压缩与数据清理。
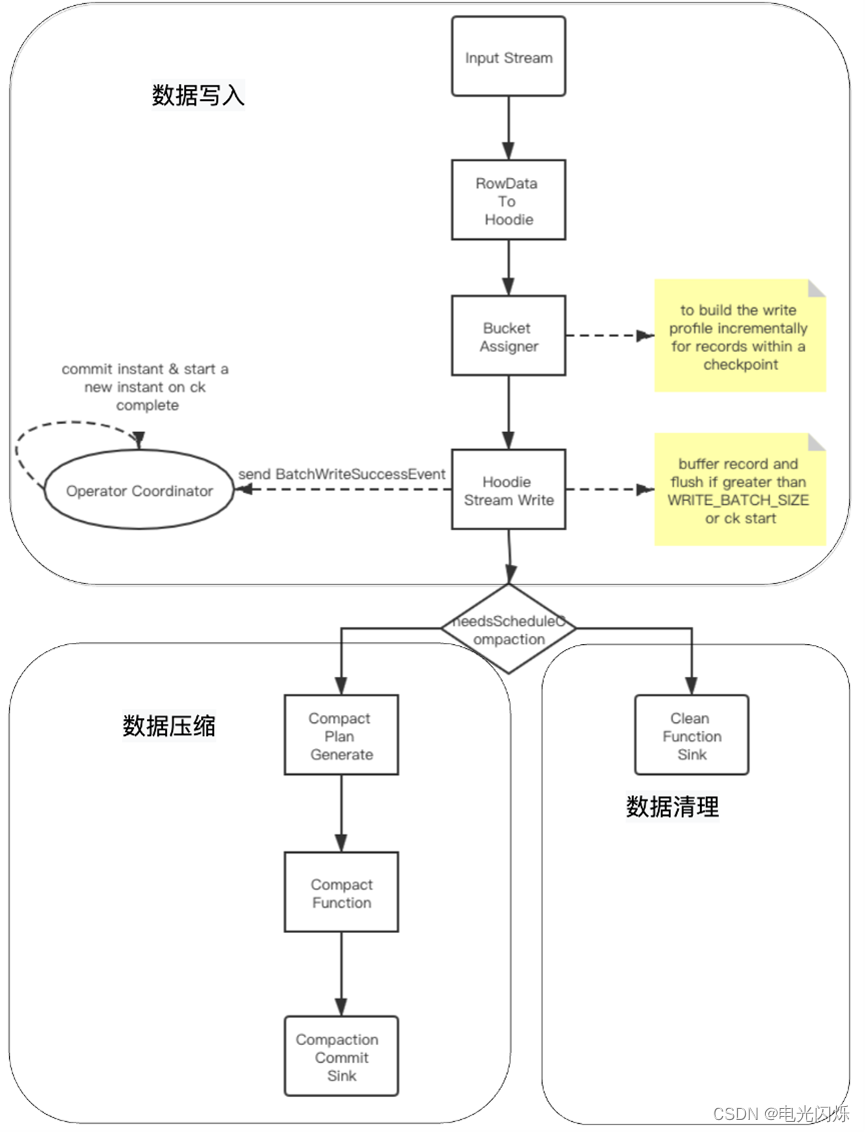
2.1. 数据写入分析
- 基础数据封装:将数据流中flink的RowData封装成Hoodie实体;
- BucketAssigner:桶分配器,主要是给数据分配写入的文件地址:若为插入操作,则取大小最小的FileGroup对应的FileId文件内进行插入;在此文件的后续写入中文件 ID 保持不变,并且提交时间会更新以显示最新版本。这也意味着记录的任何特定版本,给定其分区路径,都可以使用文件 ID 和 instantTime进行唯一定位;若为更新操作,则直接在当前location进行数据更新;
- Hoodie Stream Writer: 数据写入,将数据缓存起来,在超过设置的最大flushSize或是做checkpoint时进行刷新到文件中;
- Oprator Coordinator:主要与Hoodie Stream Writer进行交互,处理checkpoint等事件,在做checkpoint时,提交instant到timeLine上,并生成下一个instant的时间,算法为取当前最新的commi时间,比对当前时间与commit时间,若当前时间大于commit时间,则返回,否则一直循环等待生成。
2.2. 数据压缩
压缩(compaction)用于在 MergeOnRead存储类型时将基于行的log日志文件转化为parquet列式数据文件,用于加快记录的查找。compaction首先会遍历各分区下最新的parquet数据文件和其对应的log日志文件进行合并,并生成新的FileSlice,在TimeLine 上提交新的Instance:
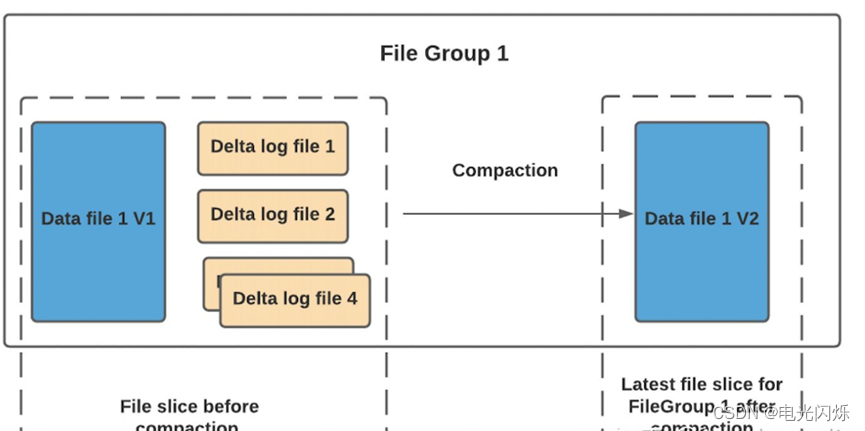
具体策略分为4种,具体见官网说明:
compaction.trigger.strategy:
Strategy to trigger compaction, options are
1.'num_commits': trigger compaction when reach N delta commits;
2.'time_elapsed': trigger compaction when time elapsed > N seconds since last compaction;
3.'num_and_time': trigger compaction when both NUM_COMMITS and TIME_ELAPSED are satisfied;
4.'num_or_time': trigger compaction when NUM_COMMITS or TIME_ELAPSED is satisfied. Default is 'num_commits'
Default Value: num_commits (Optional)
在项目实践中需要注意参数'read.streaming.skip_compaction' 参数的配置,其表示在流式读取该表是否跳过压缩后的数据,若该表用于后续聚合操作表的输入表,则需要配置值为true,表示聚合操作表不再消费读取压缩数据。若不配置或配置为false,则该表中的数据在未被压缩之前被聚合操作表读取了一次,在压缩后数据又被读取一次,会导致聚合表的sum、count等算子结果出现双倍情况。
2.3. 数据清理
随着用户向表中写入更多数据,对于每次更新,Hudi会生成一个新版本的数据文件用于保存更新后的记录(COPY_ON_WRITE)或将这些增量更新写入日志文件以避免重写更新版本的数据文件(MERGE_ON_READ)。在这种情况下,根据更新频率,文件版本数可能会无限增长,但如果不需要保留无限的历史记录,则必须有一个流程(服务)来回收旧版本的数据,这就是 Hudi 的清理服务。具体清理策略可参考官网,一般使用的清理策略为:KEEP_LATEST_FILE_VERSIONS:此策略具有保持 N 个文件版本而不受时间限制的效果。会删除N之外的FileSlice。
2.4. Job图
如下为生产环境中flink Job图,可以看到各task和上述分析过程对应,需要注意的是可以调整并行度来提升写入速度。

3. 表读取原理
如下为Hudi数据流式读取Job图:
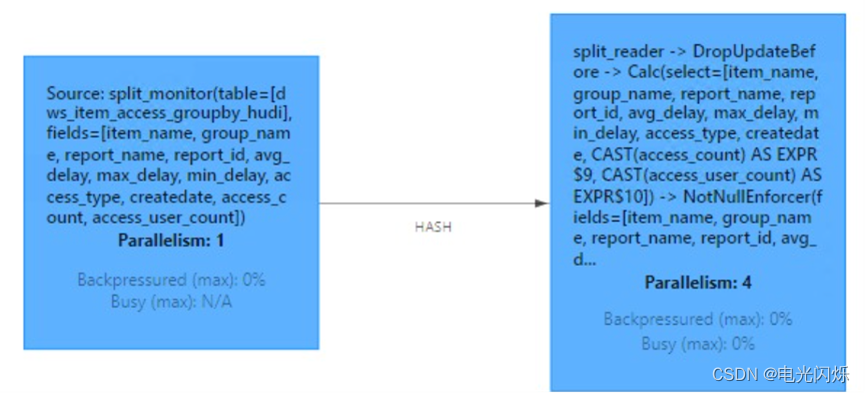
其过程为:
- 开启split_monitor算子,每隔N秒(可配置)监听TimeLine上变化,并将变更的Instance封装为FileSlice。
- 分发log文件时候,按照fileId值进行keyBy,保证同一file group下数据文件都给一个Task进行处理,从而保证数据处理的有序性。
- split_reader根据FileSlice信息进行数据读取。
注:其他Hudi相关文章链接由此进 -> Hudi文章汇总
相关文章
- 开源交流丨批流一体数据集成框架 ChunJun 数据传输模块详解分享
- 用java实现图片切换_电视背景集成墙面
- [保姆级教程]SRS直播服务器搭建兼ffmpeg推流+obs在线直播+集成
- Gitlab+Jenkins+Docker+Harbor+K8s集群搭建CICD平台(持续集成部署Hexo博客Demo)
- SpringBoot集成Swagger
- 开源单点登录MaxKey和JumpServer 堡垒机单点登录集成指南
- 在 Python 中集成一个 Hermite 系列
- 配置中心 | .NET 集成 Nacos 配置中心
- 【springboot2.x】集成knife4j
- Jumpserver与Freeipa集成(以及其他配置)
- Flink之三 flink on yarn详解大数据
- 如何设置Gitlab以在CentOS上进行持续集成和部署
- 多云融合和安全集成推动 SD-WAN 的大规模应用
- 微服务集成测试自动化探索
- 深入了解Oracle JMS:高效解决分布式应用程序集成的问题(oraclejms)
- Oracle数据库内集成Java应用运行实践(oracle内置Java)
- ci集成mysql提高效能提升开发速度(ci 输出mysql)
- Redis与MySQL实现无缝集成(redis集成mysql)
- 简单而高效Redis缓存集成与应用(redis缓存 集成)