
Argo项目实战示例:Argo Workflows(when分支,循环,递归等); Argo CD; Argo Events; Argo Rollouts
1 关于Argo
Argo是一个开源的项目,其项目宗旨为:
Get stuff done with Kubernetes.
我的理解有两个意思:一是通过Argo能够更好地把应用运行在Kubernetes平台,二是扩展Kubernetes的原生功能,实现原生Kubernetes没有完成的事。
目前Argo包含多个子项目:
- Argo Workflows:基于容器的任务编排工具。
- Argo CD:基于GitOps声明的持续交付工具。
- Argo Events:事件驱动工具。
- Argo Rollouts:支持金丝雀以及蓝绿发布的应用渐进式发布工具。
本文接下来将分别介绍如上4个工具。
2 Job编排神器Argo Workflow
2.1 Kubernetes Job的问题
Kubernetes平台主要运行一些持续运行的应用,即daemon服务,其中最擅长的就是无状态服务托管,比如Web服务,滚动升级rollout和水平扩展scale out都非常方便。
而针对基于事件触发的非持续运行的任务,Kubernetes原生能力可以通过Job实现,不过,Job仅解决了单一任务的执行,目前Kubernetes原生还没有提供多任务的编排能力,无法解决多任务的依赖以及数据交互问题。
比如启动一个测试任务,首先需要从仓库拉取最新的代码,然后执行编译,最后跑批单元测试。这些小的子任务是串行的,必须在前一个任务完成后,才能继续下一个任务。
如果使用Job,不太优雅的做法是每个任务都轮询上一个任务的状态直到结束。或者通过initContainers实现,因为initContainer是按顺序执行的,可以把前两个任务放initContainer,最后单元测试放到主Job模板中,这样Job启动时前面的initContainer任务保证是成功执行完毕。
不过initContainer只能解决非常简单的按顺序执行的串行多任务问题,无法解决一些复杂的非线性任务编排,这些任务的依赖往往形成一个复杂的DAG(有向图),比如:
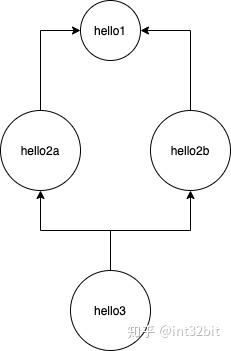
图中hello2a、hello2b任务依赖于hello1,必须等待A完成之后才能继续,hello1完成后hello2a、hello2b两个任务是可以并行的,因为彼此并无依赖,但hello3必须等待hello2a、hello2b都完成后才能继续。
这种问题通过Kubernetes的原生能力目前还不能很好的解决。
以一个实际场景为例,我们需要实现iPaaS中间件在公有云上自动部署,大致为两个过程,首先通过Terraform创建虚拟机,然后通过Ansible实现中间件的自动化部署和配置。如果使用Kubernetes Job,需要解决两个问题:
- Terraform创建虚拟机完成后如何通知Ansible?
- Terraform如何把虚拟机的IP、公钥等信息传递给Ansible,如何动态生成inventory?
显然如果单纯使用Kubernetes Job很难完美实现,除非在容器中封装一个很复杂的逻辑,实现一个复杂的编排engine,这就不是Job的问题了。
2.2 Argo workflow介绍
Argo workflow专门设计解决Kubernetes工作流任务编排问题,这个和OpenStack平台的Mistral项目作用类似。
上面的任务可以很轻易地通过Workflow编排:
# ...省略
templates:
- name: hello
# Instead of just running a container
# This template has a sequence of steps
steps:
- - name: hello1 # hello1 is run before the following steps
template: whalesay
arguments:
parameters:
- name: message
value: "hello1"
- - name: hello2a # double dash => run after previous step
template: whalesay
arguments:
parameters:
- name: message
value: "hello2a"
- name: hello2b # single dash => run in parallel with previous step
template: whalesay
arguments:
parameters:
- name: message
value: "hello2b"
- - name: hello3 # double dash => run after previous step
template: whalesay
arguments:
parameters:
- name: message
value: "hello3"
# This is the same template as from the previous example
- name: whalesay
inputs:
parameters:
- name: message
container:
image: docker/whalesay
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
steps定义任务的执行步骤,其中- -表示与前面的任务串行,即必须等待前面的任务完成才能继续。而-表示任务不依赖于前一个任务,即可以与前一个任务并行。
因为Workflow实现了Kubernetes的CRD,因此提交workflow任务可以直接通过kubectl apply,当然也可以通过argo submit提交。
argo submit step-demo.yaml
查看任务状态:

从状态图中也可以看出hello2a和hello2b是并行执行的。
2.3 DAG图
通过steps可以很方便的定义按顺序执行的线性任务,不过如果任务依赖不是线性的而是多层树依赖,则可以通过dag进行定义,dag即前面介绍的DAG有向无环图,每个任务需要明确定义所依赖的其他任务名称。
dag:
tasks:
- name: hello1
template: whalesay
arguments:
parameters:
- name: message
value: "hello1"
- name: hello2
dependencies: [hello1]
template: whalesay
arguments:
parameters:
- name: message
value: "hello2"
- name: hello3
dependencies: [hello1]
template: whalesay
arguments:
parameters:
- name: message
value: "hello3"
- name: hello4
dependencies: [hello2, hello3]
template: whalesay
arguments:
parameters:
- name: message
value: "hello4"
- name: hello5
dependencies: [hello4]
template: whalesay
arguments:
parameters:
- name: message
value: "hello5"
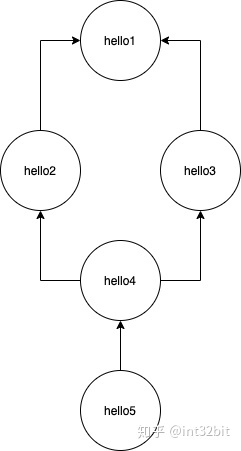
dag中的tasks通过dependencies明确定义依赖的任务,如上DAG如图:
2.4 分支、循环与递归
除了正向依赖关系,Workflow还支持分支、循环、递归等,以官方的一个硬币分支为例:
templates:
- name: coinflip
steps:
- - name: flip-coin
template: flip-coin
- - name: heads
template: heads
when: "{{steps.flip-coin.outputs.result}} == 1"
- name: tails
template: tails
when: "{{steps.flip-coin.outputs.result}} == 0"
- name: flip-coin
script:
image: python:alpine3.6
command: [python]
source: |
import random
print(random.randint(0,1))
- name: heads
container:
image: alpine:3.6
command: [sh, -c]
args: ["echo \"it was heads\""]
- name: tails
container:
image: alpine:3.6
command: [sh, -c]
args: ["echo \"it was tails\""]
如上flip-coin通过Python随机生成0或者1,当为1时heads任务执行,反之tails任务执行:
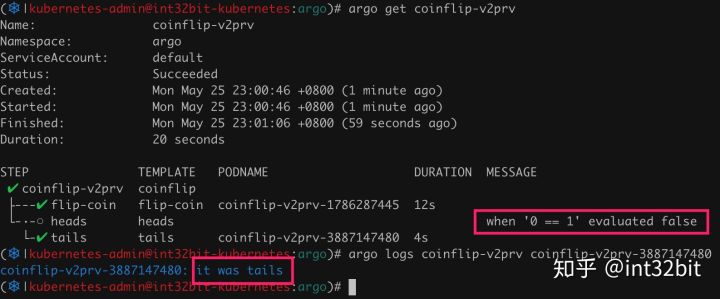
如上由于结果为0,因此heads没有执行,而tails执行了,并且输出了it was tails。
2.5 input与output
任务之间除了定义依赖关系,还可以通过input、output实现数据交互,即一个task的output可以作为另一个task的input。
templates:
- name: output-parameter
steps:
- - name: generate-parameter
template: whalesay
- - name: consume-parameter
template: print-message
arguments:
parameters:
- name: message
value: "{{steps.generate-parameter.outputs.parameters.hello-param}}"
- name: whalesay
container:
image: docker/whalesay:latest
command: [sh, -c]
args: ["echo -n hello world > /tmp/hello_world.txt"]
outputs:
parameters:
- name: hello-param
valueFrom:
path: /tmp/hello_world.txt
- name: print-message
inputs:
parameters:
- name: message
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
如上generate-parameter通过whalesay输出hello world到/tmp/hello_world.txt上并作为outputs输出。而print-message直接读取了generate-parameter outputs作为参数当作inputs。

2.6 Artifacts
除了通过input和output实现数据交互,对于数据比较大的,比如二进制文件,则可以通过Artifacts制品进行共享,这些制品可以是提前准备好的,比如已经存储在git仓库或者s3中,也可以通过任务生成制品供其他任务读取。
如下为官方的一个例子:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: artifact-example-
spec:
entrypoint: main
templates:
- name: main
steps:
- - name: generate-artifact
template: whalesay
- - name: consume-artifact
template: print-message
arguments:
artifacts:
- name: message
from: "{{steps.generate-artifact.outputs.artifacts.hello-art}}"
- name: whalesay
container:
image: docker/whalesay:latest
command: [sh, -c]
args: ["sleep 1; cowsay hello world | tee /tmp/hello_world.txt"]
outputs:
artifacts:
- name: hello-art
path: /tmp/hello_world.txt
- name: print-message
inputs:
artifacts:
- name: message
path: /tmp/message
container:
image: alpine:latest
command: [sh, -c]
args: ["cat /tmp/message"]
如上generate-artifact任务完成后output输出一个名为hello-art的制品,这个制品会把/tmp/hello_world.txt这个文件打包后上传到制品库中,默认制品库可以通过configmap配置,通常是放在S3上。
print-message会从制品库中读取hello-art这个制品内容并输出。
2.7 其他功能
前面涉及的任务都是非持续运行任务,Workflow也支持后台Daemon任务,但是一旦所有的任务结束,即整个workflow完成,这些Daemon任务也会自动删除,这种场景主要用于自动化测试,比如产品API测试,但是API可能依赖于数据库,此时可以通过Workflow的task先启动一个数据库,然后执行自动化测试,测试完成后会自动清理环境,非常方便。
另外,Workflow的template中container和Pod的Container参数基本类似,即Pod能使用的参数Workflow也能用,比如PVC、env、resource request/limit等。
2.8 总结
Job解决了在Kubernetes单次执行任务的问题,但不支持任务的编排,难以解决多任务之间的依赖和数据共享。Argo Workflow弥补了这个缺陷,支持通过yaml编排Job任务,并通过input/output以及artifacts实现Job之间数据传递。
3 Deployment扩展之Argo Rollout
3.1 Kubernetes应用发布
早期Kubernetes在还没有Deployment时,可以认为应用是不支持原地滚动升级的,虽然针对ReplicationController,kubectl看似有一个rolling-update的自动升级操作,但这个操作的步骤其实都是客户端实现的,比如创建新版本ReplicationContrller,增加新版本副本数减少老版本副本数都是客户端通过调用api-server实现,如果本地网络故障或者kubectl进程异常退出,则会导致升级失败,使RC处于半升级异常状态。
而后Deployment出现,ReplicationContrller废弃被Replicasets替代,Kubernetes应用渐进式滚动升级完美解决,整个步骤都是由Deployment Controller负责的,无需客户端干预,并且还支持了应用的版本管理,可以很方便的回滚到任意版本上。
Deployment还支持配置maxSurge、maxUnavailable控制渐进式版本升级过程,但目前原生还不支持版本发布策略,比如常见的金丝雀发布、蓝绿发布等。
当然你可以通过手动创建一个新的Deployment共享一个Service来模拟金丝雀和蓝绿发布,不过这种方式只能手动去维护应用版本和Deployment资源,而集成外部工具比如Spinnaker则会比较复杂。
3.2 Argo Rollout
Argo Rollout可以看做是Kubernetes Deployment的功能扩展,弥补了Deployment发布策略的功能缺失部分,支持通过.spec.strategy配置金丝雀或者蓝绿升级发布策略。
把一个Deployment转化成Rollout也非常简单,只需要:
apiVersion由apps/v1改成argoproj.io/v1alpha1。kind由Deployment改成Rollout。- 在原来的
.spec.strategy中增加canary或者bluegreen配置。
3.3 金丝雀发布
以Kubernetes经典教程的Kubernetes-bootcamp为例:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
labels:
app: canary-demo
name: canary-demo
spec:
replicas: 5
selector:
matchLabels:
app: canary-demo
strategy:
canary:
steps:
- setWeight: 20
- pause: {}
- setWeight: 40
- pause: {duration: 10m}
- setWeight: 60
- pause: {duration: 10m}
- setWeight: 80
- pause: {duration: 10m}
template:
metadata:
labels:
app: canary-demo
spec:
containers:
- image: jocatalin/kubernetes-bootcamp:v1
name: kubernetes-bootcamp
字段配置和Deployment基本完全一样,主要关注.spec.strategy,这里定义了金丝雀canary策略,发布共分为8个步骤,其中pause为停止,如果没有指定时间则会一直处于停止状态,直到有外部事件触发,比如通过自动化工具触发或者用户手动promote。
第一步设置weight为20%,由于一共5个副本,因此升级20%意味着只升级一个副本,后续的40%、60%、80%依次类推。
创建完后我们直接通过kubectl edit修改镜像为jocatalin/kubernetes-bootcamp:v2,此时触发升级。
我们查看rollout实例如下:
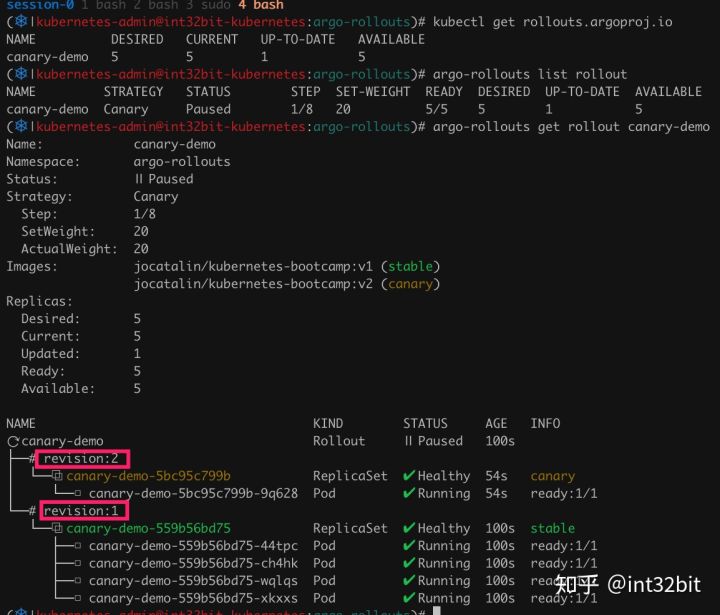
我们发现新版本有一个副本,占比20%。
由于我们没有通过canaryService以及stableService,因此Service没有做流量分割,大概会有20%的流量会转发给到新版本。当然这种流量切割粒度有点粗略,如果想要更细粒度的控制流量,可以通过ingress或者istio实现基于权值的流量转发策略。
如果在.spec.strategy中指定了canaryService以及stableService,则升级后会做流量分割,canaryService只会转发到新版本流量,而stableService则只转发到老版本服务,这是通过修改Service的Selector实现的,升级后会自动给这两个Service加上一个Hash。
手动执行promote后进入下一步,此时新版本为40%:

由此可见,我们可以通过定义canary策略,使用rollout渐进式的发布我们的服务。
3.4 蓝绿发布
与金丝雀发布不一样,蓝绿发布通常同时部署两套完全一样的不同版本的服务,然后通过负载均衡进行流量切换。
rollout支持blueGreen策略,配置也非常简单,如下:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
labels:
app: bluegreen-demo
name: bluegreen-demo
spec:
replicas: 5
selector:
matchLabels:
app: bluegreen-demo
strategy:
blueGreen:
activeService: bluegreen-active
previewService: bluegreen-preview
autoPromotionEnabled: false
template:
metadata:
labels:
app: bluegreen-demo
spec:
containers:
- image: jocatalin/kubernetes-bootcamp:v1
name: kubernetes-bootcamp
如上配置了blueGreen策略,相比canary配置会更简单,其中配置了两个Service,分别为activeService和previewService,分别负责老版本和新版本的流量转发。
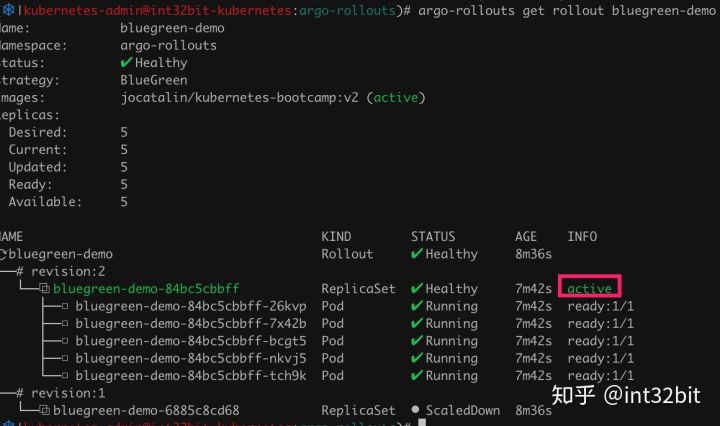
我们修改image为v2后,查看rollout信息如下:

我们发现同时部署了一个新版本和老版本,通过不同的Service访问不同的版本,基本可以等同于部署了两个Deployment。
执行promote后老版本默认会在30秒后自动销毁,并自动把active指向新版本。
3.5 Analysis
无论是采用何种发布策略,在新版本正式上线前,通常都需要进行大量的测试,只有测试没有问题之后才能安全地切换流量,正式发布到新版本。
测试既可以手动测试,也可以自动测试。前面我们的canary和bluegreen Demo都是手动promote发布的,这显然不是效率最高的方法,事实上rollout提供了类似Kayenta的自动化测试分析的工具,能够在金丝雀或者蓝绿发布过程中自动进行分析测试,如果新版本测试不通过,则升级过程会自动终止并回滚到老版本。
测试的指标来源包括:
- prometheus: 通过prometheus的监控指标分析测试结果,比如服务如果返回5xx则测试不通过。
- kayenta: 通过kayenta工具分析。
- web: web测试,如果结果返回OK则测试通过,可以使用服务的healthcheck接口进行测试。
- Job: 自己定义一个Job进行测试,如果Job返回成功则测试通过。
这里以Job为例,配置Analysis模板为例:
apiVersion: argoproj.io/v1alpha1
kind: AnalysisTemplate
metadata:
name: analysis-demo
spec:
metrics:
- name: analysis-demo
interval: 10s
failureLimit: 3
provider:
job:
spec:
backoffLimit: 0
template:
spec:
containers:
- name: test
image: busybox
imagePullPolicy: IfNotPresent
command:
- sh
- -c
- '[[ $(expr $RANDOM % 2) -eq 1 ]]'
restartPolicy: Never
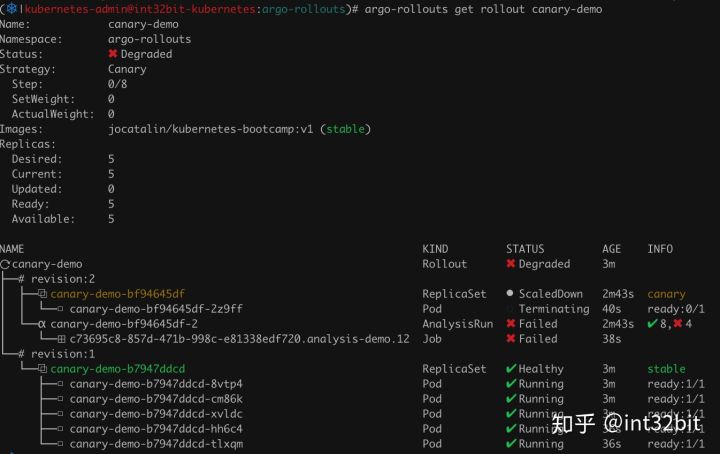
这个Job没有意义,只是随机返回成功和失败,如果失败次数超过3则认为整个分析过程失败。
我们仍然以前面的金丝雀发布为例,加上Analysis如下:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
labels:
app: canary-demo
name: canary-demo
spec:
replicas: 5
selector:
matchLabels:
app: canary-demo
strategy:
canary:
analysis:
templates:
- templateName: analysis-demo # 引用analysis模板
steps:
- setWeight: 20
- pause: {duration: 2m}
- setWeight: 40
- pause: {duration: 2m}
- setWeight: 60
- pause: {duration: 2m}
- setWeight: 80
- pause: {duration: 2m}
template:
metadata:
labels:
app: canary-demo
spec:
containers:
- image: jocatalin/kubernetes-bootcamp:v1
imagePullPolicy: IfNotPresent
name: kubernetes-bootcamp
部署如上应用并通过kubectl edit修改image为kubernetes-bootcamp:v2,查看rollout信息如下:
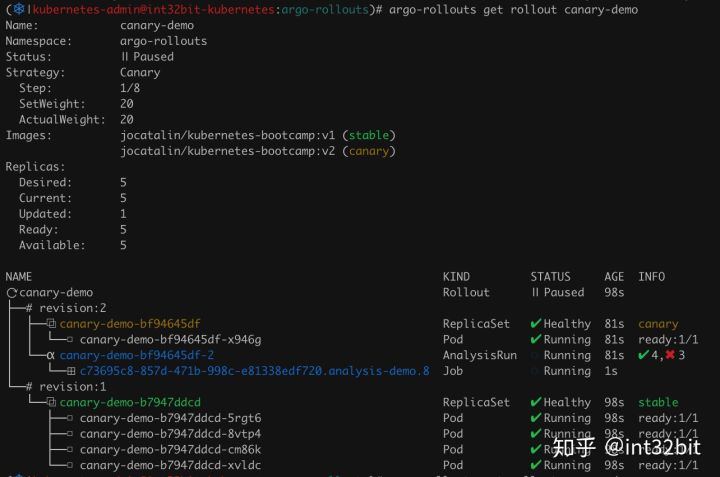
当失败次数超过3时,发布失败,自动降级回滚:
3.6 总结
Argo Rollout可以认为是Deployment的扩展,增加了蓝绿发布和金丝雀发布策略配置,并且支持通过自动测试实现服务发布或者回滚。
4 Argo Event
4.1 Argo Event简介
Event事件大家都很熟悉,可以说Kubernetes就是完全由事件驱动的,不同的controller manager本质就是实现了不同的事件处理函数,比如所有ReplicaSet对象是由ReplicaSetController控制器管理,该控制器通过Informer监听ReplicaSet以及其关联的Pod的事件变化,从而维持运行状态和我们声明spec保持一致。
当然Kubernetes无论是什么Controller,其监听和处理的都是内部事件,而在应用层上我们也有很多外部事件,比如CICD事件、Webhook事件、日志事件等等,如何处理这些事件呢,目前Kubernetes原生是无法实现的。
当然你可以自己实现一个event handler运行在Kubernetes平台,不过实现难度也不小。而Argo Event组件完美解决了这个问题。
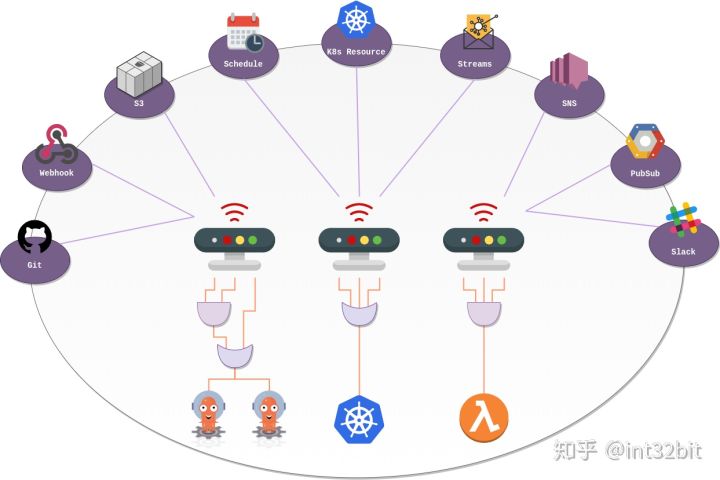
如图是Argo Event官方提供的的流程图:
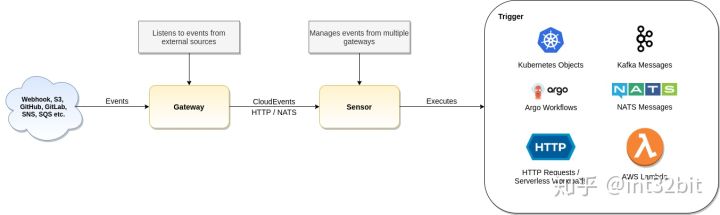
首先事件源EventSource可以是Webhook、S3、Github、SQS等等,中间会经过一个叫Gateway(新版本叫EventBus)的组件,更准确地说老版本原来gateway的配置功能已经合并到EventSource了,EventBus是新引入的组件,后端默认基于高性能分布式消息中间件NATS[1]实现,当然其他中间件比如Kafka也是可以的。
这个EventBus可以看做是事件的一个消息队列,消息生产者连接EvenSource,EventSource又连接到Sensor。更详细地说EvenSource把事件发送给EvenBus,Sensor会订阅EvenBus的消息队列,EvenBus负责把事件转发到已订阅该事件的Sensor组件,EventSorce在上图中没有体现,具体设计文档可以参考Argo-events Enhancement Proposals[2]。
有些人可能会说为什么EventBus不直接到Trigger,中间引入一个Sensor,这主要是两个原因,一是为了使事件转发和处理松耦合,二是为了实现Trigger事件的参数化,通过Sensor不仅可以实现事件的过滤,还可以实现事件的参数化,比如后面的Trigger是创建一个Kubernetes Pod,那这个Pod的metadata、env等,都可以根据事件内容进行填充。
Sensor组件注册关联了一个或者多个触发器,这些触发器可以触发AWS Lambda事件、Argo Workflow事件、Kubernetes Objects等,通俗简单地说,可以执行Lambda函数,可以动态地创建Kubernetes的对象或者创建前面的介绍的Workflow。
还记得前面介绍的Argo Rollout吗,我们演示了手动promote实现应用发布或者回滚,通过Argo Event就可以很完美地和测试平台或者CI/CD事件结合起来,实现自动应用自动发布或者回滚。
4.2 一个简单的Webhook例子
关于Argo Event的部署非常简单,直接通过kubecl apply或者helm均可,可以参考文档Installation[3],这里不再赘述。
Argo Event部署完成后注意还需要部署EventBus,官方推荐使用NATS中间件,文档中有部署NATS stateful的文档。
接下来我们以一个最简单的Webhook事件为例,从而了解Argo Event的几个组件功能以及用法。
首先按照前面的介绍,我们需要先定义EventSource:
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: webhook
spec:
service:
ports:
- port: 12000
targetPort: 12000
webhook:
webhook_example:
port: "12000"
endpoint: /webhook
method: POST
这个EventSource定义了一个webhook webhook_example,端口为12000,路径为/webhook,一般Webhook为POST方法,因此该Webhhok处理器我们配置只接收POST方法。
为了把这个Webhook EventSource暴露,我们还创建了一个Service,端口也是12000。
此时我们可以手动curl该Service:
# kubectl get svc -l eventsource-name=webhook
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webhook-eventsource-svc ClusterIP 10.96.93.24 <none> 12000/TCP 5m49s
# curl -X POST -d '{}' 10.96.93.24:12000/webhook
success
当然此时由于没有注册任何的Sensor,因此什么都不会发生。
接下来我们定义Sensor:
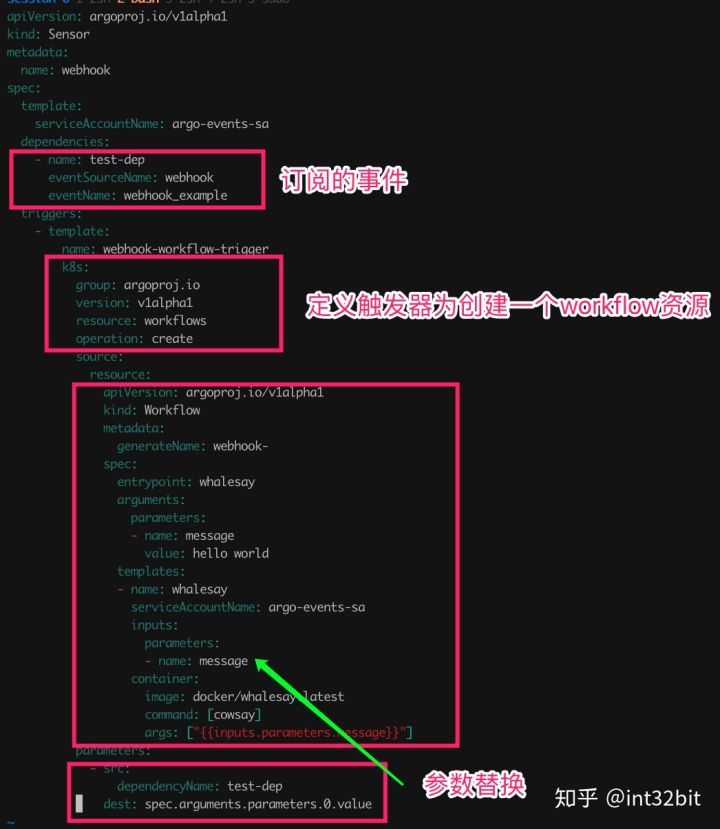
首先在dependencies中定义了订阅的EventSource以及具体的Webhook,由于一个EventSource可以定义多个Webhook,因此必须同时指定EventSource和Webhook两个参数。
在Trigger中我们定义了对应Action为create一个workflow,这个workflow的spec定义在resource中配置。
最后的parameters部分定义了workflow的参数,这些参数值从event中获取,这里我们会把整个event都当作workflow的input。当然你可以通过dataKey只汲取body部分:dataKey: body.message。
此时我们再次curl这个webhook事件:
curl -X POST -d '{"message": "HelloWorld!"}' 10.96.93.24:12000/webhook
此时我们获取argo workflow列表发现新创建了一个实例:
# argo list
NAME STATUS AGE DURATION PRIORITY
webhook-8xt4s Succeeded 1m 18s 0
查看workflow输出如下:
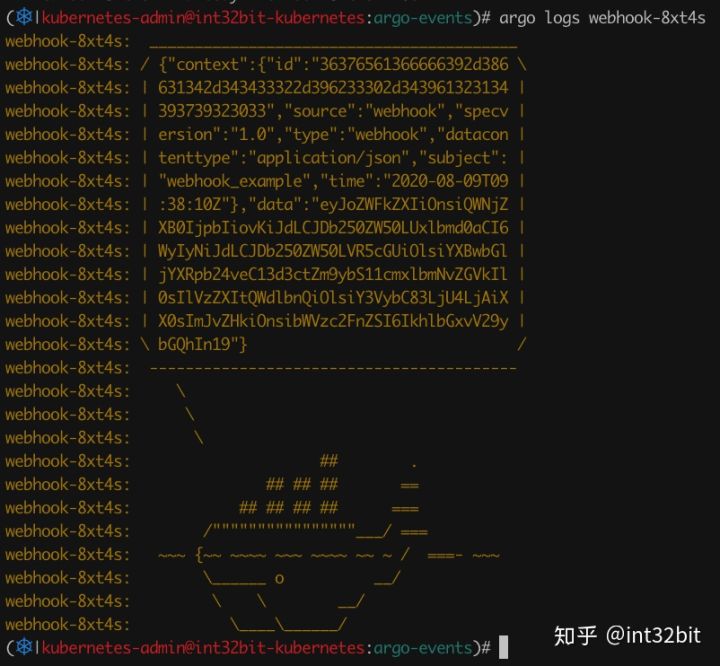
由于我们是把整个event作为workflow input发过去的,因此data内容部分是base64编码,我们可以查看解码后的内容如下:
{
"header": {
"Accept": [
"*/*"
],
"Content-Length": [
"26"
],
"Content-Type": [
"application/x-www-form-urlencoded"
],
"User-Agent": [
"curl/7.58.0"
]
},
"body": {
"message": "HelloWorld!"
}
}
从这里我们也可以看出Event包含两个部分,一个是context,一个是data,data中又包含header部分以及body部分,在parameters中可以通过Key获取任意部分内容。
如上的webhook触发是通过手动curl的,你可以很容易地在github或者bitbucket上配置到webhook中,这样一旦代码有更新就能触发这个事件了。
4.3 Kubernetes触发AWS Lambda函数
前面的例子中的EventSource使用了Webhook,除了Webhook,Argo Event还支持很多的EventSource,比如:
- amqp
- aws-sns
- aws-sqs
- github/gitlab
- hdfs
- kafka
- redis
- Kubernetes resource
- ...
Trigger也同样支持很多,比如:
- aws lambda
- amqp
- kafka
- ...
如上官方都提供了非常丰富的例子,可以参考argo events examples[4]。
这里以Kubernetes resource事件源为例,这个事件监听Kubernetes的资源状态,比如Pod创建、删除等,这里以创建Pod为例:
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: k8s-resource-demo
spec:
template:
serviceAccountName: argo-events-sa
resource:
pod_demo:
namespace: argo-events
version: v1
resource: pods
eventTypes:
- ADD
filter:
afterStart: true
labels:
- key: app
operation: "=="
value: my-pod
如上例子监听Pods的ADD事件,即创建Pod,filter中过滤只有包含app=my-pod标签的Pod,特别需要注意的是使用的serviceaccount argo-events-sa必须具有Pod的list、watch权限。
接下来我们使用AWS Lambda触发器,Lambda函数已经在AWS提前创建好:

这个Lambda函数很简单,直接返回event本身。
创建Sensor如下:
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: aws-lambda-trigger-demo
spec:
template:
serviceAccountName: argo-events-sa
dependencies:
- name: test-dep
eventSourceName: k8s-resource-demo
eventName: pod_demo
triggers:
- template:
name: lambda-trigger
awsLambda:
functionName: hello
accessKey:
name: aws-secret
key: accesskey
secretKey:
name: aws-secret
key: secretkey
namespace: argo-events
region: cn-northwest-1
payload:
- src:
dependencyName: test-dep
dataKey: body.name
dest: name
如上AWS access key和access secret需要提前放到aws-secret中。
此时我们创建一个新的Pod my-pod:
apiVersion: v1
kind: Pod
metadata:
labels:
app: my-pod
name: my-pod
spec:
containers:
- image: nginx
name: my-pod
dnsPolicy: ClusterFirst
restartPolicy: Always
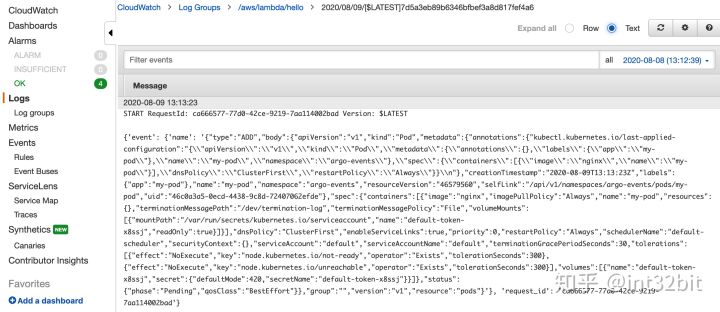
当Pod启动后,我们发现AWS Lambda函数被触发执行:
4.4 event filter
前面的例子中webhook中所有的事件都会被sensor触发,我们有时不需要处理所有的事件,Argo Event支持基于data以及context过滤,比如我们只处理message为hello或者为hey的事件,其他消息忽略,只需要在原来的dependencies中test-dep增加filter即可:
dependencies:
- name: test-dep
eventSourceName: webhook
eventName: webhook_example
filters:
- name: data-filter
data:
- path: body.message
type: string
value:
- "hello"
- "hey"
filter指定了基于data过滤,过滤的字段为body.message,匹配的内容为hello、hey。
4.5 trigger policy
trigger policy主要用来判断最后触发器执行的结果是成功还是失败,如果是创建Kubernetes资源比如Workflow,可以根据Workflow最终状态决定这个Trigger的执行结果,而如果是触发一个HTTP或者AWS Lambda,则需要自定义policy status。
awsLambda:
functionName: hello
accessKey:
name: aws-secret
key: accesskey
secretKey:
name: aws-secret
key: secretkey
namespace: argo-events
region: us-east-1
payload:
- src:
dependencyName: test-dep
dataKey: body.message
dest: message
policy:
status:
allow:
- 200
- 201
如上表示当AWS Lambda返回200或者201时表示Trigger成功。
4.6 总结
前面介绍的例子都是单事件源单触发器,Argo Event可以支持多种事件源以及触发器,支持各种组合,从而实现把内部以及外部事件结合起来,通过事件驱动把应用以及外围系统连接起来,目前我们已经通过监听代码仓库Push或者PR Merge更新自动触发Workflow收集C7N policy到自动化平台系统中。
5 Argo CD
5.1 关于GitOps
最近各种Ops盛行,比如DevOps、DevSecOps、AIOps、GOps、ChatOps、GitOps等等,这些都可以认为是持续交付的一种方式,而本章主要关注其中的GitOps。
GitOps的概念最初来源于Weaveworks的联合创始Alexis在2017年8月发表的一篇博客GitOps - Operations by Pull Request[5],由命名就可以看出GitOps将Git作为交付流水线的核心。
通俗地讲,就是通过代码(code)定义基础设施(infrastructure)以及应用(application),这些代码可以是Terraform的声明文件或者Kubernetes或者Ansible的yaml声明文件,总之都是代码。
这些代码均可以通过git代码仓库(如github、gitlab、bitbuket)进行版本管理。这样就相当于把基础设施和应用通过git仓库管理起来了,如果需要做应用变更,只需要提交一个Pull Request,merge后持续交付工具自动根据变更的声明文件进行变更,收敛到最终期望的状态。应用回滚则只需要通过git revert即可。
通过git log可以方便地查看应用的版本信息,通过git的多分支可以指定交付的不同环境,比如开发测试环境、预发环境、生产环境等。
GitOps特别适合云原生应用,yaml定义一切,因此GitOps在Weaveworks的推广下流行起来,目前Jenkins X、Argo CD、Weave Flux、Spinnaker等均是基于GitOps模型的持续交付工具。
本章主要介绍其中的Argo CD工具。
5.2 Argo CD
Argo CD也是Argoproj项目中开源的一个持续集成工具,功能类似Spinnaker。
其部署也非常简单,可以参考官方文档Getting Started[6]。
ArgoCD内置了WebUI以及CLI工具,CLI工具功能比较全,比如只能通过CLI添加cluster,在WebUI上无法完成。
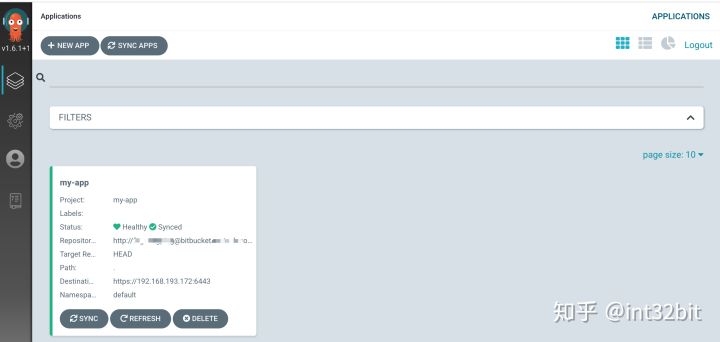
ArgoCD主要包含如下实体:
- Repository: 代码仓库,支持HTTPS或者SSH协议纳管代码仓库,代码仓库中包含Kubernetes yaml文件或者Helm Chart等。
- Cluster:Kubernetes集群,通常需要托管多个Kubernetes,比如生产环境、测试环境、预发环境、版本环境等。
- Project:其实就是Repository和Cluster建立关系,即把Repository中的声明的应用部署到指定的Cluster中。
- APP:Project的运行态。
5.3 Argo CD简单演示
Argo CD由于已经提供了WebUI,只需要按照UI界面提示一步步操作即可,没有什么难度。这里快速演示下如何使用Argo CD。
首先在github上创建了一个my-app的仓库,仓库的app目录下创建了一个my-app.yaml文件:

my-app.yaml文件内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-app
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- image: jocatalin/kubernetes-bootcamp:v1
name: my-app
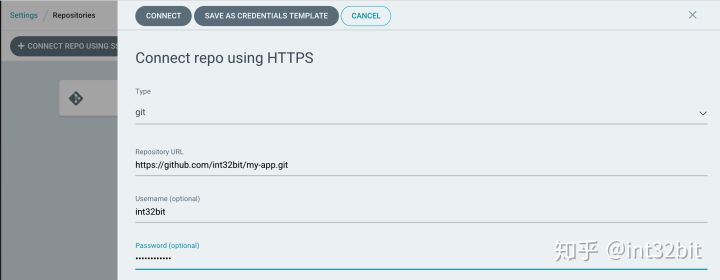
在Argo CD中创建一个Repository:
接着在Argo CD中创建一个Project,指定Repository以及Cluster:

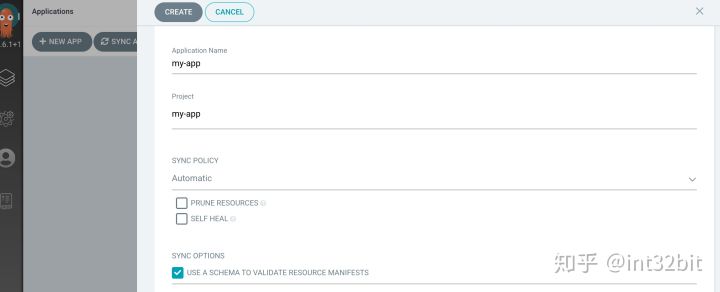
最后创建App即可:
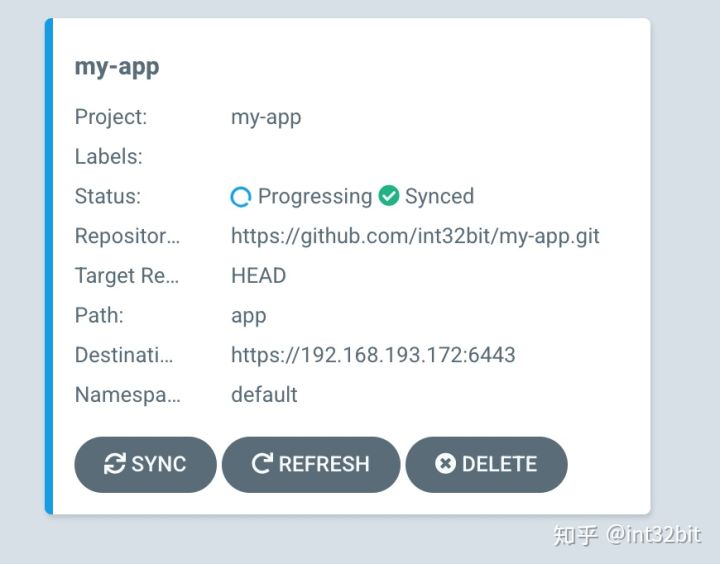
此时应用自动进行同步和部署:
同步完成后,所有创建的资源都是可视化的:
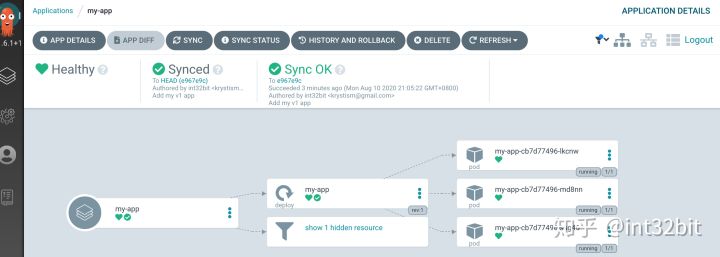
现在我们把版本升级到v2:
git checkout -b v2
sed -i 's#jocatalin/kubernetes-bootcamp:v1#jocatalin/kubernetes-bootcamp:v2#g' app/my-app.yaml
git add .
git commit -m "Upgrade my app to v2"
git push --set-upstream origin v2
如上我们也可以直接push代码到master分支,不过为了按照GitOps的标准流程,我们创建了一个新的分支v2,通过Pull Request合并到master分支中。
在github上创建Pull Request并Merge后,应用自动进行了更新:
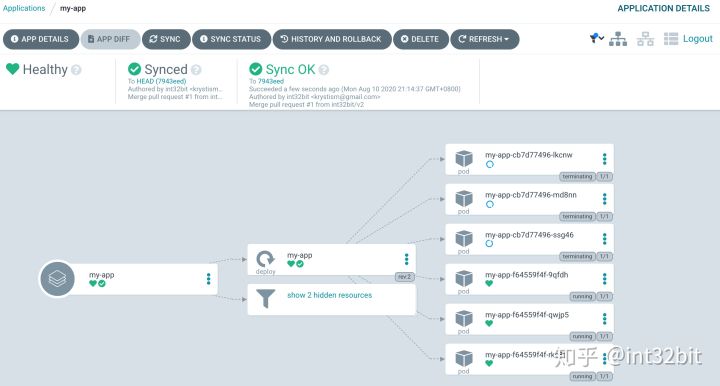
5.4 总结
Argo CD是基于GitOps模型的持续集成工具,搭配CI工具完成应用的自动构建并推送镜像到仓库中,配合CD完成应用的持续交付。
参考资料
[1]
NATS: https://nats.io/
[2]
Argo-events Enhancement Proposals: https://docs.google.com/document/d/1uPt2DyvzObEzZVbREqjW-o1gKCZ_hB8QS5Syw7_MLT8/edit#
[3]
Installation: https://argoproj.github.io/argo-events/installation/
[4]
argo events examples: https://github.com/argoproj/argo-events/tree/master/examples
[5]
GitOps - Operations by Pull Request: https://www.weave.works/blog/gitops-operations-by-pull-request
[6]
Getting Started: https://argoproj.github.io/argo-cd/getting_started/