
MySQL · TokuDB · 事务子系统和 MVCC 实现
之前有篇月报是关于innodb事务子系统的《MySQL · 引擎特性 · InnoDB 事务子系统介绍》 里面较详细的讲述了 MySQL 如何开启一个事务,感兴趣的同学可以先阅读那篇温习一下。
TokuDB 引擎也支持事务,保证一个事务内的所有操作都执行成功或者都未被执行。TokuDB中的事务由数据结构 tokutxn 表示。当开启一个 txn 时,TokuDB会创建一个 tokutxn 实例,下面只显示比较重要的字段。
struct tokutxn {
TXNID_PAIR txnid; // 事务ID
uint64_t snapshot_txnid64; // 快照ID
const TXN_SNAPSHOT_TYPE snapshot_type; // 快照类型
const bool for_recovery; // 是否处于recovery过程
struct tokulogger* const logger; // logger子系统handle
struct tokutxn* const parent; // parent事务
struct tokutxn* child; // child事务
txn_child_manager* child_manager; // child事务的txn manager
xid_omt_t* live_root_txn_list; // 活跃读写事务列表,记录这个txn开始时刻系统所有活跃读写事务。按txnID(事务开启时间)从小到大排列
struct XIDS_S* xids; // 对于nested txn,记录这个txn和他所有祖先txn。xids[0]是最老的祖先事务
struct tokutxn* snapshot_next; // 链到txn_manager的snapshot list双向链表的连接件
struct tokutxn* snapshot_prev; // 链到txn_manager的snapshot list双向链表的连接件
toku_mutex_t txn_lock; // txn的互斥锁
struct txn_roll_info roll_info; // rollback段的管理结构
开启txn
TokuDB开启txn会调用toku_txn_begin_with_xid 函数创建tokutxn实例并进行初始化。每个TokuDB txn都有一个唯一的txnid,如果是snapshot读还有一个唯一的snapshot_txnid64。toku_txn_begin_with_xid 根据 parent 是否为NULL和for_recovery是否为TRUE调用相应的函数来设置:
设置txnid; 如果是snapshot操作,设置snapshot_txnid64; 如果是snapshot操作,创建live_root_txn_list:表示这个txn能看到的view,在下面的isolation level一节会展开讨论; 如果是snapshot操作,需要把这个txn加到txn_manager的snapshot list双向链表尾部; 创建xids数组:nested txn数组,xids[0]表示最老的祖先txn; 如果是读写事务,这个txn也在它的live_root_txn_list上。代码片段:
int
toku_txn_begin_with_xid (TOKUTXN parent, TOKUTXN *txnp, TOKULOGGER logger, TXNID_PAIR xid, TXN_SNAPSHOT_TYPE snapshot_type, DB_TXN *container_db_txn, bool for_recovery, bool read_only)
int r = 0;
TOKUTXN txn;
//创建并初始化tokutxn
toku_txn_create_txn( txn, parent, logger, snapshot_type, container_db_txn, for_recovery, read_only);
if (for_recovery) {
if (parent == NULL) {
assert(xid.child_id64 == TXNID_NONE);
toku_txn_manager_start_txn_for_recovery(txn, logger- txn_manager, xid.parent_id64);
else {
parent- child_manager- start_child_txn_for_recovery(txn, parent, xid);
else {
assert(xid.parent_id64 == TXNID_NONE);
assert(xid.child_id64 == TXNID_NONE);
if (parent == NULL) {
toku_txn_manager_start_txn(txn, logger- txn_manager, snapshot_type, read_only);
else {
parent- child_manager- start_child_txn(txn, parent);
toku_txn_manager_handle_snapshot_create_for_child_txn(txn, logger- txn_manager, snapshot_type);
if (!read_only) {
txn_create_xids(txn, parent);
*txnp = txn;
exit:
return r;
这里不考略recovery(即for_recovery为TRUE)的情况。对于一般的事务,caller传过来的xid参数为{TXNID_NONE,TXNID_NONE},txn- txnid 在这个函数里生成。parent==NULL,表示是root txn 的情况;否则是nested child txn的情况。细心的朋友可能会发现传入参数xid和struct tokutxn的txnid域的类型是TXNID_PAIR,定义如下:
typedef struct txnid_pair_s { TXNID parent_id64; TXNID child_id64; } TXNID_PAIR;
parent_id64 表示root txn的txnid,child_id64只对nested child txn有意义,表示child的txnid。
提交txnTokuDB 提交 txn 最终会调到toku_rollback_commit。如果是root txn调用apply_txn对rollback log的每一个item进行commit操作。如果是nested child txn把child txn的rollback log挂到parent的rollback log尾部,等到root txn 提交的时候对所有rollback log的item进行commit。apply_txn的最后一个参数是一个回调函数,txn- commit时,传给apply_txn的回调函数是toku_rollback_commit。需要注意的是,对于大部分DML操作rollback log item- commit都是noop。
回滚txn如果txn中发生错误或者上层显示调用rollback命令,TokuDB最终调用toku_rollback_abort回滚这个txn的所有操作。toku_rollback_abort也是调用apply_txn来对rollback log的每一个item进行abort操作。txn- txn_abort时,传给apply_txn的回调函数是toku_rollback_abort。它对每个rollback log item记录的key发FT_ABORT_ANY消息进行回滚。
Rollback log这里我们一起来看看rollback log吧。TokuDB txn的rollback log的信息记录在tokutxn- roll_info域里面。
struct txn_roll_info {
uint64_t num_rollback_nodes; // rollback node个数
uint64_t num_rollentries; // rollback entry总个数
uint64_t num_rollentries_processed; //已经处理过得rollback entry个数
uint64_t rollentry_raw_count; // rollback entry的总字节数
BLOCKNUM spilled_rollback_head; // spilled rollback双向链表头
BLOCKNUM spilled_rollback_tail; // spilled rollback双向链表尾
BLOCKNUM current_rollback; // 当前rollback node
txn修改数据的动作会记录在tokutxn- roll_info。current_rollback指向的数据节点里面,这些节点被称为rollback node也是缓存在catchetable里面,请参阅之前月报 《MySQL · TokuDB · Cachetable 的工作线程和线程池》 对cachetable的描述。如果一个txn修改了大量数据,一个rollback node存不下怎么办呢?TokuDB的处理方式是在每次往current_rollback里面添加新的undo信息时调用函数toku_maybe_spill_rollbacks判断current_rollback是否已满,若是则把current_rollback挂到spilled_rollback_head所指向的双向链表的末尾,此后有新的undo要写的时候,需要再申请一个新的rollback node作为current_rollback。提交nested child txn时,如果child txn有spilled rollback log,需要先调用toku_logger_save_rollback_rollinclude在parent的current rollback里新加一个rollback log entry把child txn的spilled rollback信息记录在里面。
Isolation level前面描述了TokuDB中一个txn是如何开始和如何结束的,描述的都是单独一个txn是怎么工作的。当有多个txn并发执行对同一个数据的修改时,用户看到的行为又将如何呢?
数据库有四种isolation level,定义可以参考 wiki。
一般的应用场景使用read committed或者repeatable read隔离级别。简单的说,Read committed读到的是stmt开始时刻committed的数据;repeatable read读到的是txn开始时刻committed的数据。
下面我们一起来看看TokuDB是如何实现这两种isolation level的。
TokuDB在txn- txn_begin把sql的isolation level (repeatable read在MySQL里映射成snapshot) 映射成TokuDB的isolation level,映射如下表所示:
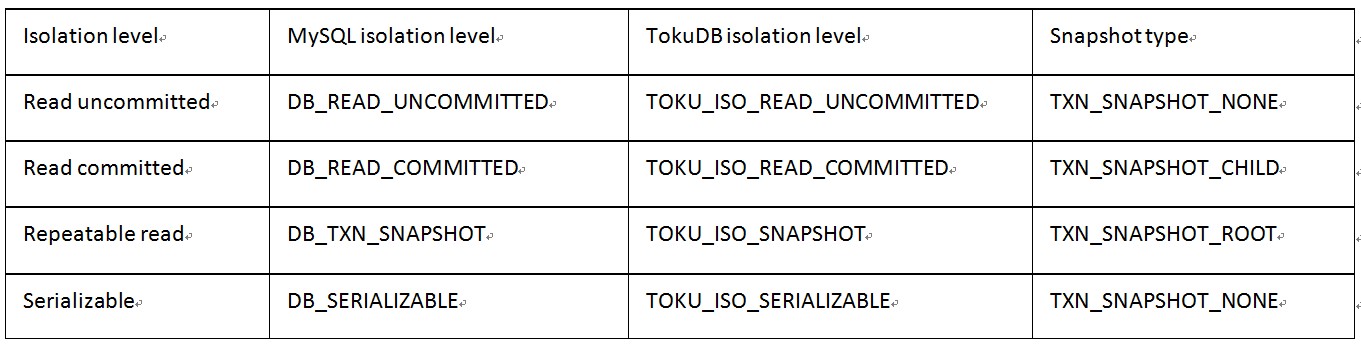
TokuDB隔离级别
最后一列是snapshot type,在txn- begin的时候会根据snapshot type 建立live_root_txn_list。对于TXN_SNAPSHOT_CHILD(也就是read committed),每个txn (即使是nested child txn)都会新创建一个snapshot, 生成全局唯一的snapshot_txnid64,txn- live_root_txn_list是当前这个tokutxn开始时刻的活跃读写事务列表。对于TXN_SNAPSHOT_ROOT(也就是Repeatable read),root txn在txn- txn_begin的时候会创建一个新的snapshot,生成全局唯一的snapshot_txnid64,root txn的 live_root_txn_list 是这个root tokutxn开始时刻的活跃读写事务列表;对于nested child txn在txn- txn_begin的时候不会创建新的snapshot,而是继承root tokutxn的live_root_txn_list。
判断是否要创建新的snapshot的函数如下:
inline bool txn_needs_snapshot(TXN_SNAPSHOT_TYPE snapshot_type, struct tokutxn *parent) {
// we need a snapshot if the snapshot type is a child or if the snapshot type is root and we have no parent.
// Cases that we dont need a snapshot: when snapshot type is NONE or when it is ROOT and we have a parent
return (snapshot_type != TXN_SNAPSHOT_NONE (parent==NULL || snapshot_type == TXN_SNAPSHOT_CHILD));
顺便说一下,Serializable 隔离级别是在row lock层实现的,请参阅之前月报《MySQL · TokuDB · TokuDB 中的行锁》。在c_set_bounds函数,如果是Serializable隔离级别需要获取row lock的读锁,其他的隔离级别在读的时候不需要拿row lock。需要提一点的是,TokuDB在实现row lock的模块里,隐式地将读锁升级为写锁。所以,Serializable隔离级别下,并发访问同一行的多个txn是串行执行的。代码片段如下:
static int
c_set_bounds(DBC *dbc, const DBT *left_key, const DBT *right_key, bool pre_acquire, int out_of_range_error) {
//READ_UNCOMMITTED and READ_COMMITTED transactions do not need read locks.
if (!dbc_struct_i(dbc)- rmw dbc_struct_i(dbc)- iso != TOKU_ISO_SERIALIZABLE)
return 0;
toku::lock_request::type lock_type = dbc_struct_i(dbc)- rmw ? toku::lock_request::type::WRITE : toku::lock_request::type::READ;
int r = toku_db_get_range_lock(db, txn, left_key, right_key, lock_type);
return r;
前面谈了这么多主要是为这一节做铺垫,MVCC的全称是Multi-Version Concurrency Control。此技术最初是 Oracle 实现的用以控制并发事务读取数据的技术。除了MVCC以外,还有基于lock并发访问技术,InnoDB、DB2、SQL Server都有基于锁的并发访问技术。MVCC在OLTP领域的性能方面有一定的优势,现在主流数据库版本都实现了MVCC技术。
TokuDB实现MVCC的方法和Oracle、InnoDB都不一样,不是通过undo segment来构造snapshot读的数据,而是把多个版本的数据都存放在leaf node的entry里面。所以,TokuDB实现的MVCC,读和写之间是可能产生等待(等的锁是pair- lock, 其实是cachetable的hashtable的bucket锁,这块比较隐晦,读者仔细看看代码便知)。
下面我们一起来看一下MVCC的数据在内存中展开的样子:
typedef struct uxr {
uint8_t type; // delete/insert/placeholder
uint32_t vallen; // 长度
void * valp; // 指向数据的buffer
TXNID xid; // txnid
} UXR_S, *UXR;
typedef struct ule {
uint32_t num_puxrs; // provisional txn的个数
uint32_t num_cuxrs; // committed txn的个数
UXR_S uxrs_static[MAX_TRANSACTION_RECORDS*2]; // 静态分配的空间
UXR uxrs; // txns
} ULE_S, *ULE;
多个版本的数据是存放在uxrs域里面,它的每一项对应一个txn的版本。从uxrs[0]开始到uxrs[num_cuxrs - 1]存放的是committed数据,uxrs[num_cuxrs]到uxrs[num_cuxrs + num_puxr-1]存放的是provisional的数据。
假设一个leaf entry,有2份committed数据,3份provisional数据,uxrs如下所示(红色表示committed txn,绿色表示provisional txn):

ULE_S只是MVCC数据的逻辑表示,真正存在leaf node的entry是以序列化形式存放的,相应的数据结构叫做leafentry:
struct leafentry {
struct leafentry_clean {
uint32_t vallen;
uint8_t val[0];
struct __attribute__ ((__packed__)) leafentry_mvcc {
uint32_t num_cxrs; // number of committed transaction records
uint8_t num_pxrs; // number of provisional transaction records
uint8_t xrs[0];
uint8_t type; // type is LE_CLEAN or LE_MVCC
union __attribute__ ((__packed__)) {
struct leafentry_clean clean;
struct leafentry_mvcc mvcc;
} u;
Leaf node的每一个entry可以处在两种形式其中的一种:
Clean:只有一个版本,和一般数据库leaf node里的数据类似; MVCC:每个数据有多个版本,每个版本对应一个txn的数据。多个txn的数据保存在xrs里面,是一段连续的内存。num_cxrs表示committed txn的个数,num_pxrs表示in-progress txn的个数。Leafentry- u.mvcc.xrs表示的连续内存空间的layout如下:从offset 0 开始,每项占1个 (txnid, 长度 类型)字节或多个(数据)字节
最外的provisional txn的txnid; 除最外的committed txn以外,所有的committed txn的 txnid形成的txnid列表,顺序从最里的committed txn直到次最外的committed txn;最外的committed txn的txn id是TXNID_NONE; 最里的provisional txn的长度和类型; Commited txn的(长度,类型)二元组的列表,顺序从最里的committed txn到最外的committed txn; 最里的provisional txn数据; 所有commited txn数据列表,顺序从最里的committed txn到最外的committed txn; 最外的provisional txn长度和类型; 最外的provisional txn数据; provisional txn的(txnid,长度 类型,数据)三元组列表,顺序从次最外的provisional txn到次最里的provisional txn; 最里的provisionl txn的txnid;当修改leaf node数据的时候,需要先把 leafentry 表示的 MVCC 数据转成 ULE 表示的数据,然后进行修改,insert/delete 就是新加一个provisional txn,最后在把ULE表示的MVCC数据转成leafentry表示保存在leaf node里面。
读leaf node的数据过程比较复杂,涉及到MVCC的核心部分。首先用binary search定位在FT的哪个leaf node的哪个basement node的data_buffer的哪个leaf entry。调用le_extract_val来读leaf entry上的数据,一般来说ftcursor- is_snapshot_read都为TRUE,它会调用 le_iterate_val 根据type判断读clean的数据还是MVCC的数据。如果是clean的就直接读出返回;如果是 MVCC 就要解析Leafentry- u.mvcc.xrs的序列化的结构。在这个layout里,最前面的num_cuxrs+1(如果有provisional txn)个字节保存的是一些txnid:
Provisional txn的txnid(如有provisional txn); 最里的committed txn的txnid到次最外的committed txn的txnid列表;也就是从ULE.uxrs[num_cuxrs]开始往ULE.uxrs[0]的方向找到当前txn可以读的txnid最大的(也即最新的事务)committed txnid。函数toku_txn_reads_txnid判读一个txn是否可以读某个特定的txnid的数据。代码如下所示:
int toku_txn_reads_txnid(TXNID txnid, TOKUTXN txn) {
int r = 0;
TXNID oldest_live_in_snapshot = toku_get_oldest_in_live_root_txn_list(txn);
if (oldest_live_in_snapshot == TXNID_NONE txnid txn- snapshot_txnid64) {
r = TOKUDB_ACCEPT;
} else if (txnid oldest_live_in_snapshot || txnid == txn- txnid.parent_id64) {
r = TOKUDB_ACCEPT;
} else if (txnid txn- snapshot_txnid64 || toku_is_txn_in_live_root_txn_list(*txn- live_root_txn_list, txnid)) {
r = 0;
} else {
r = TOKUDB_ACCEPT;
return r;
txn可以读txnid数据的条件:
如果txn的live_root_txn_list为空(创建snapshot的时候没有活跃的读写事务),并且txnid对应事务比txn还要早,并且txn是snapshot读; 如果txnid对应事务比txn的live_root_txn_list里的所有活跃的读写事务都要早,或者txnid对应事务就是txn(非snapshot读),或者txnid对应的事务是txn的root txn(snapshot读); txnid对应事务比txn早,并且txnid不在txn- live_root_txn_list。le_iterate_val代码片段如下:
int
le_iterate_val(LEAFENTRY le, LE_ITERATE_CALLBACK f, void** valpp, uint32_t *vallenp, TOKUTXN context) {
uint8_t type = le- type;
switch (type) {
case LE_CLEAN: {
vallen = toku_dtoh32(le- u.clean.vallen);
valp = le- u.clean.val;
r = 0;
break;
case LE_MVCC:;
uint32_t num_cuxrs = toku_dtoh32(le- u.mvcc.num_cxrs);
uint32_t num_puxrs = le- u.mvcc.num_pxrs;
uint8_t *p = le- u.mvcc.xrs;
uint32_t index, num_interesting;
num_interesting = num_cuxrs + (num_puxrs != 0);
TXNID *xids = (TXNID*)p;
r = le_iterate_get_accepted_index(xids, index, num_interesting, f, context);
Garbage Collection
从前面的分析可以看出,TokuDB引擎运行一定时间后leaf entry里面的历史txn信息越来越大,自然而然地要考虑内存空间回收的问题,即MVCC的GC问题。
Txn managerTokuDB维护一个全局唯一的txn_manager数据结构管理系统中所有读写事务(live_root_ids有序数据结构),snapshot(snapshot head/snapshot tail双向链表)和可能正在被引用的committed读写事务(referenced_xids有序数据结构)。
struct txn_manager {
toku_mutex_t txn_manager_lock; // 互斥锁
txn_omt_t live_root_txns; // 系统中活跃的读写事务
xid_omt_t live_root_ids; // 系统中活跃的读写事务ID
TOKUTXN snapshot_head,snapshot_tail; // 系统中所有snapshot构成的双向链表
uint32_t num_snapshots; // 系统中snapshot的个数
rx_omt_t referenced_xids; // 三元组(committed txnid,系统中最大的可能的txnid,可能访问committed txnid的snapshot个数)的有序数据结构,按committed txnid字段排序。
TXNID last_xid; // 系统中最大的可能的txnid
TXNID last_xid_seen_for_recover; // recovery过程中最大的txnid
TXNID last_calculated_oldest_referenced_xid; // 所有live list(包括live root list,snapshot list,referencelist)中最小的(最老的)txnid
一个txn的生命周期是由txn_manager的live_root_ids,snapshot双向链表,referenced_xids这三个数据结构来跟踪的,TokuDB MVCC 的 GC 也是根据这三个数据结构来判断一个committed txn是否可以被清理掉了。下面我们一起去看看txn是在什么时候加入和离开这三个数据结构的。
live_root_ids:如果是读写事务,在txn- txn_begin加入live_root_ids (live_root_txns);txn- txn_commit或者txn- txn_abort的时候离开live_root_ids (live_root_txns)。如果是只读事务,它不会加入到live_root_ids (live_root_txns)。在TokuDB中,autocommit=1情况下query是只读事务,insert/update/delete是读写事务;autocommit=0的情况下,query也是读写事务;
snapshot_head和snapshot_tail构成的双向链表:在txn- txn_begin,如果是创建新的snapshot,这个txn会被加到snapshot链表尾部(snapshot list尾部表示最新的snapshot,头部表示最老的snapshot);在txn- txn_commit/txn- txn_abort时,如果是snapshot操作,并且这个txn有对应的snapshot,它会被从snapshot list里删除;
referenced_xids:在txn- txn_commit/txn- txn_abort时,如果是读写事务,会扫描snapshot list找到可能引用这个txn的所有snapshot(也就是在这个txn之后创建的所有snapshot),这些snapshot被记做这个txn的reference snapshot set。在TokuDB的代码里reference_xids记录的是(这个committed 读写事务txnid,系统当前最大的txnid,可能引用这个读写事务的snapshot的个数)构成的三元组。如果是只读事务,不会加入到referenced_xids。当snapshot对应的txn执行txn- txn_commit/txn- txn_abort时,会查找referenced_xids把这个snapshot引用的所有读写事务的ref_count减1,若ref_count减为0则把引用的读写事务对应的三元组从referenced_xids删除。回顾前面讲的,snapshot对应的txn创建的时候,被引用的读写事务一定处在已创建 未提交 未回滚的状态,所以被引用的读写事务一定是在snapshot对应的txn的live_root_txn_list,那么只需要扫描snapshot对应txn的live_root_txn_list上的每一个读写事务txn1,看看是否有(txn1, txn2, count)构成的三元组存在即可。程序里有个优化,当txn的live_root_txn_list的大小远远大于 txn_manger 的 referenced_xids,可以扫描referenced_xids,对每一个三元组(txn1, end_txnid, ref_count)判断txn1是否在txn的live_root_txn_list上面,若是则对ref_count减1。当ref_count减为0则把这个三元组从referenced_xids删除。
隐式提交provisional txn:如果leaf entry里最老的(最外的)provisional txn,比系统可能存在的最老的txn还要老,把那个provisional txn promote成最新的(最内的)committed txn,所有的provisional txn都将被丢弃。Promote最老的provisional txn时,txnid选择最老的provisional txn的txnid,value选择最新的provisional txn的value,这样做是考虑到nested txn的情况; 简单GC:如果leaf entry里面存在某些committted txn,它们比所有活跃的读写事务、所有的snapshot、所有被引用的已committed的读写事务都要早,简而言之是那些已经不被任何后继事务访问的已提交事务。找到leaf entry里面满足如上条件最新的(txnid最大的)committed txn,它之前的所有committed txn都可以被清理掉; 深度GC:如果leaf entry里面存在某些committed txn,它们不在任何txn的活跃读写事务列表里面,并且它的数据对所有的snapshot都没有意义(没有snapshot可能读它的数据)。那么这些committed txn可以被丢弃。 调用GC的时机 Leaf node在被从cachetable写回到磁盘之前会尝试对整个leaf node做GC; 往leaf node上的某个entry上apply msg的时候,如果leaf entry size大于某个阈值会对这个leaf entry做GC。 为了支持 nested txn 的额外工作
为了支持nested txn,MVCC的实现变得较为复杂,在这里顺便提一下,大家有时间仔细看看代码。在对leaf node entry做commit操作时(ule_apply_commit)会考虑provisional txn的个数,等于1表示非nested txn,直接调用ule_promote_provisional_innermost_to_committed把最新的(最里的)provisional txn提交;如果大于1,表示有nested txn存在,会调用ule_promote_provisional_innermost_to_index把最新的(最里的)provisional txn提交到它的parent(上一个provisional txn)。在nested txn中,可能存在一些没有直接修改这个ULE的事务,这些事务是在第一个直接修改这个ULE的txn执行msg_modify_ule的时候调用ule_do_implicit_promotions把它们补上去的。
MySQL 事务详解 事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系 统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
MySQL事务 因为 只有以上的三个语句是数据库表中数据进行增、删、改的。 只要你的操作一旦涉及到数据的增、删、改,那么就一定要考虑安全问题。
【MySQL】事务日志 undo log 详解 Redo log是事务持久性的保证,Undo log是事务原子性的保证。在事务中更新数据的前置操作其实就是要写入Undo log。事务需要保证原子性,也就是事务中的操作要么全部完成,要么什么也不做。但有时候事务执行到一半会出现一些情况,比如: 情况一:事务执行过程中可能遇到各种错误,比如服务器本身的错误,操作系统错误,甚至是突然断电导致的错误。 情况二:程序员可以在事务执行过程中手动输入ROLLBACK语句结束当前事务的执行以上情况出现,我们需要把数据改回原先的样子,这个过程称之为回滚,这样就可以造成一个假象:这个事务看起来什么都没做,所以符合原子性要求每当我们要对一条记录做改动。
【MySQL】事务日志 redo log 详解 redo 日志降低了刷盘的频率,并且redo日志占用的空间非常小。(redo日志主要存储表空间ID、页号、偏移量以及需要更新的值,所需存储的空间很小,刷盘快)。Redo Log 可以简单的非为两部分组成:重做日志的缓存(redo log buffer),保存在内存中,容易丢失。重做日志文件(rodo log file),保存在硬盘中,保证持久性。Redo Log写入并不是直接写入磁盘的,Innodb引擎会在写Redo Log的时候先写redo log buffer,之后再以一定的频率刷入到真正的redo log file中。这里的一定的频率就是所谓的刷盘策略。
学习MySQL的第六天:事务(基础篇) 事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
db匠 rds内核团队秘密研发的全自动卖萌机. 追加特效: 发数据库内核月报. 月报传送: http://mysql.taobao.org/monthly/
相关文章
- mysql 事务的实现原理
- mysql事务
- CentOS安装MySQL(rpm方式)
- Mac 卸载MySql的方法
- ERROR 1044 (42000): Access denied for user ''@'localhost' to database 'mysql'
- MySQL内核月报 2015.01-MySQL · 性能优化· 启用GTID场景的性能问题及优化
- 数据库内核月报 - 2015 / 08-MySQL · 社区动态 · MySQL5.6.26 Release Note解读
- 重新整理 mysql 基础篇————— 事务隔离级别[四]
- MySQLl的可串行化_mysql事务串行化的锁机制是怎样的?
- MySQL事务隔离级别和实现原理
- Python3需要安装的MySQL库是mysqlclient
- MySQL事务隔离级别及演示
- MySQL服务启动及密码设置/配置远程访问
- Mysql 的InnoDB事务方面的 多版本并发控制如何实现 MVCC
- piap.excel 微软 时间戳转换mssql sql server文件时间戳转换unix 导入mysql
- MySQL事物(一)事务隔离级别和事物并发冲突
- mysql常用基础操作语法(九)~~外连接查询【命令行模式】
- MySQL数据库事务隔离级别(Transaction Isolation Level)
- mysql存储引擎
- mysql数据库之常用SQL语句及事务学习笔记(一)
- Centos7安装Mysql-5.6.34