
使用Apache Flume抓取数据(1)
使用Apache Flume抓取数据,怎么来抓取呢?不过,在了解这个问题之前,我们必须明确ApacheFlume是什么?
一、什么是Apache Flume
Apache Flume是用于数据采集的高性能系统 ,名字来源于原始的近乎实时的日志数据采集工具,现在广泛用于任何流事件数据的采集,支持从很多数据源聚合数据到HDFS。
最初由Cloudera开发 ,在2011年贡献给了Apache基金会 ,在2012年变成了Apache的***项目,Flume OG升级换代成了Flume NG。
Flume具有横向扩展、延展性、可靠性的优势
二、Flume 体系结构
Source:接受外部系统生成event
Sink:发送event到指定的目的地
Channel:从Source缓存event,直到Sink把event取走
Agent:一个独立的Flume进程,包含了source,channel和sink组件
三、Flume设计目标:可靠性
Channels提供了Flume可靠性保障 ,那么它通过什么样的方式来保障呢?默认的模式就是Memory Channel,Memory Channel就是内存,所有的数据存放在内存当中。那么,这里就会存在一个问题?如果Channel的节点出现断电,数据就会丢失。为解决这一问题,这里有另外一种模式,就是基于磁盘的Channel,基于磁盘的队列确保出现断电时数据不丢失 。
另外,Agent和Channel之间的数据传输是事务性的 ,传输给下游agent失败的数据会回滚和重试 。相同的任务可以配置多个Agent,
比如,两个agent完成一个数据采集作业,如果一个agent失败,则上游的agent会失败切换到另一个。
四、Flume设计目标:扩展性
当我们采集的数据特别多的时候,可以通过添加更多的系统资源从而线性地增加系统性能。而且Flume可横向的扩展规模 ,随着复杂增加,可以添加更多的机器到配置当中 。
五、Flume设计目标:延展性
延展性就是能够添加新的功能到系统中。Flume通过添加Sources和Sinks到现有的存储层或数据平台,常见的Sources包括files、syslog和任何linux进程的标准输出的数据;常用Sinks包括本地文件系统或HDFS,开发员可以写自己的Sources或Sinks。
六、常见的Flume数据源
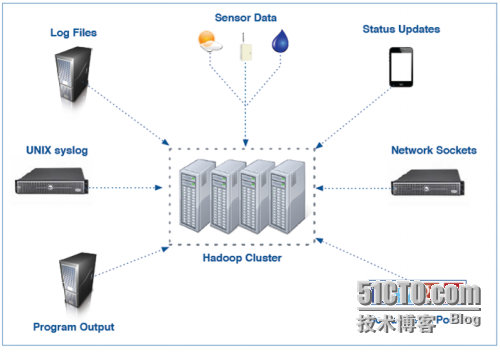
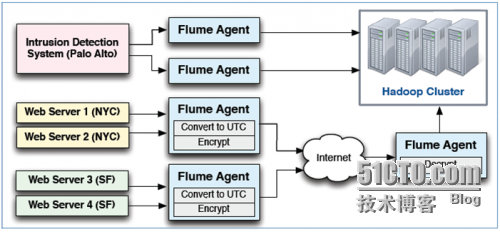
七、大规模部署实例
Flume使用agents收集数据 ,Agents可以从很多源接收数据,包括其他agents。大规模的部署使用多层来实现扩展性和可靠,Flume支持传输中数据的检查和修改。
以上就是关于Apache Flume的部分详情介绍,后续将会继续分享。大数据将会是未来的风口,要想很好的站在风口上,就要持续不断地学习和努力,这里推荐大家关注一个微信公众号“大数据cn ”,里面有很多关于大数据知识的介绍,对于想要了解和学习大数据的人是一个很好的平台。
相关文章
- 【FFH】小熊派驱动调用流程(以调用LED灯驱动为例)
- 服务器性能优化之网络性能优化
- Preset-Env 按需 Polyfill 是怎么实现的?
- Windows不安装虚拟机如何使用Linux系统作为开发工具?
- 一款运行于Windows上的Linux命令神器-Cmder(已经爱不释手)
- Spring认证_什么是Spring GraphQL?
- 跟我学Linux:apt命令快速参考指南
- oeasy教您玩转vim – 11 – # 向前向后
- 谷歌推出 Chrome OS Flex 系统,可将旧电脑变成 Chromebook
- Wine 7.2 发布,Linux下安装使用最新版QQ与微信
- xtrabackup 增量,全备份,恢复备份
- windows 远程桌面连接提示:出现了内部错误,windows远程桌面登录linux闪退
- 基于java springboot垃圾分类小程序源码(毕设)
- oeasy教您玩转vim – 10 – # 插入新行
- golang 系列: mutex 讲解
- 云服务器系统哪个好用吗
- 哈雷推出电动摩托车,超400万元收购品牌域名LiveWire.com
- 直观对比了解Windows 10和Windows 11,才知道最好用的系统是这个
- 至暗时刻,风“云”突变(四):2015到2019,从5到70,从0到100万,技术推动业务的云实践,我创业的这4年
- oeasy教您玩转vim – 9 – # 换行插入