
[日常] MySQL的哈希索引和原理研究测试
2023-02-18 15:47:04 时间
1.哈希索引 :(hash index)基于哈希表实现,只有精确匹配到索引列的查询,才会起到效果。
对于每一行数据,存储引擎都会对所有的索引列计算出一个哈希码(hash code),哈希码是一个
较小的整数值,并且不同键值的行计算出来的哈希码也不一样。
2.只有Memory存储引擎显式支持哈希索引,但是原理可以用在伪哈希索引上
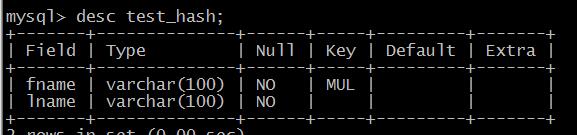
表结构如下:
create table test_hash(
fname varchar(100) not null default '',
lname varchar(100) not null default '',
index using hash(fname)
) engine=memory
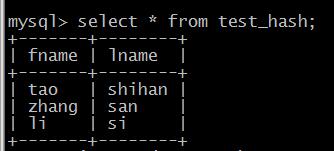
insert into test_hash values ('zhang','san'),('tao','shihan'),('li','si');
3.假设会有这样一个哈希函数f(),该返回下面的哈希码整数值
f('tao')=2323
f('zhang')=7437
f('li')=8784
4.一张哈希表,存储着对应关系,槽编号是循序的,值数据行不是
槽(Slot) 值(Value)
2323 指向第2行数据
7437 指向第1行数据
8784 指向第3行数据
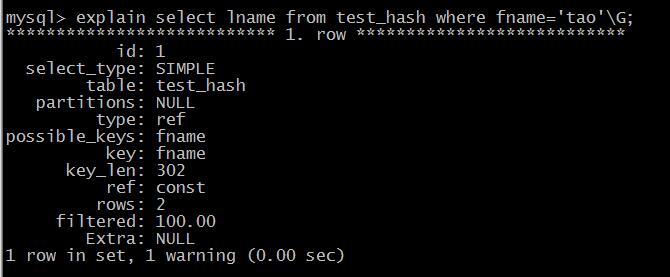
5.select lname from test_hash where fname='tao'\G;
mysql先计算'tao'的哈希值,f('tao')=2323,然后根据该值在哈希索引表中查找对应的行,找到它指向的是
第2行数据,直接查询第2行数据,判断fname是tao,确保正确
6.哈希冲突:不同的值得到了相同的哈希码,例如f('tao')=2323 f('wang')=2323,此时就是出现了哈希冲突
当出现哈希冲突时,相同的数据会存储在链表中,遍历链表找到符合的。
7.特点:
1)哈希索引只包含哈希码和指针,不存储数据字段值
2)哈希索引数据并不是按循序存储的,因此无法用于排序
3)因为要通过查询值计算确定的哈希码,所以哈希索引不支持部分匹配,不支持范围查找,只支持等值比较查询
4)当哈希冲突很多的时候,效率会降低
在InnoDB存储引擎上,可以基于上面的原理,实现伪哈希索引,配合默认的B-Tree索引
相关文章
- HTML5项目笔记10:使用HTML5 IndexDB设计离线数据库
- HTML5项目笔记9:HTML5 Canvas 的图表报表开发
- HTML5项目笔记8:使用HTML5 的跨域通信机制进行数据同步
- HTML5项目笔记7:使用HTML5 WebStorage API构建与.NET对应的会话机制
- HTML5项目笔记6:使用HTML5 FileSystem API设计离线文件存储
- HTML5项目笔记5:使用HTML5 WebDataBase设计离线数据库
- HTML5项目笔记4:使用Audio API设计绚丽的HTML5音乐播放器
- HTML5项目笔记2:离线系统表单设计
- HTML5项目笔记1:项目准备和工具使用
- Web前端设计模式--购物车拖拽的实现...
- LinQ构建分层架构
- Web前端设计模式--构建Ajax智能搜索...
- Web前端设计模式--制作漂亮的弹出层...
- Web 前端设计模式--Dom重构...
- Web前端设计模式--jQuery验证插件...
- PBN主区代表95%时间概率的范围,这个理解对么?
- 第九节 RNP APCH保护区的绘制
- 第八节 起始进近基线转弯保护区的绘制
- 第七节 VOR/DME进近程序保护区的绘制
- 第六节 FAF与GP不工作保护区的绘制