
这几个Python数据可视化探索实例,拿走不谢!

大家好,我是J哥。(文末送书)
利用可视化探索图表
一、数据可视化与探索图
数据可视化是指用图形或表格的方式来呈现数据。图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义。用户通过探索图(Exploratory Graph)可以了解数据的特性、寻找数据的趋势、降低数据的理解门槛。
二、常见的图表实例
本章主要采用 Pandas 的方式来画图,而不是使用 Matplotlib 模块。其实 Pandas 已经把 Matplotlib 的画图方法整合到 DataFrame 中,因此在实际应用中,用户不需要直接引用 Matplotlib 也可以完成画图的工作。
1.折线图
折线图(line chart)是最基本的图表,可以用来呈现不同栏位连续数据之间的关系。绘制折线图使用的是 plot.line() 的方法,可以设置颜色、形状等参数。在使用上,拆线图绘制方法完全继承了 Matplotlib 的用法,所以程序最后也必须调用 plt.show() 产生图,如图8.4 所示。
df_iris[['sepal length (cm)']].plot.line()
plt.show()
ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--')
ax.set(xlabel="index", ylabel="length")
plt.show()
2.散布图
散布图(Scatter Chart)用于检视不同栏位离散数据之间的关系。绘制散布图使用的是 df.plot.scatter(),如图8.5所示。
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')
3.直方图、长条图
直方图(Histogram Chart)通常用于同一栏位,呈现连续数据的分布状况,与直方图类似的另一种图是长条图(Bar Chart),用于检视同一栏位,如图 8.6 所示。
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist()
2 df.target.value_counts().plot.bar()
4. 圆饼图、箱形图
圆饼图(Pie Chart)可以用于检视同一栏位各类别所占的比例,而箱形图(Box Chart)则用于检视同一栏位或比较不同栏位数据的分布差异,如图 8.7 所示。
df.target.value_counts().plot.pie(legend=True)
df.boxplot(column=['target'],figsize=(10,5))
数据探索实战分享
本节利用两个真实的数据集实际展示数据探索的几种手法。
一、2013年美国社区调查
在美国社区调查(American Community Survey)中,每年约有 350 万个家庭被问到关于他们是谁及他们如何生活的详细问题。调查的内容涵盖了许多主题,包括祖先、教育、工作、交通、互联网使用和居住。
数据来源:https://www.kaggle.com/census/2013-american-community-survey。
数据名称:2013 American Community Survey。
先观察数据的样子与特性,以及每个栏位代表的意义、种类和范围。
# 读取数据
df = pd.read_csv("./ss13husa.csv")
# 栏位种类数量
df.shape
# (756065,231)
# 栏位数值范围
df.describe()
先将两个 ss13pusa.csv 串连起来,这份数据总共包含 30 万笔数据,3 个栏位:SCHL ( 学历,School Level)、 PINCP ( 收入,Income) 和 ESR ( 工作状态,Work Status)。
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接两份数据
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)
依据学历对数据进行分群,观察不同学历的数量比例,接着计算他们的平均收入。
group = df['ac_survey'].groupby(by=['SCHL']) print('学历分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())
二、波士顿房屋数据集
波士顿房屋数据集(Boston House Price Dataset)包含有关波士顿地区的房屋信息, 包 506 个数据样本和 13 个特征维度。
数据来源:https://archive.ics.uci.edu/ml/machine-learning-databases/housing/。
数据名称:Boston House Price Dataset。
先观察数据的样子与特性,以及每个栏位代表的意义、种类和范围。
可以用直方图的方式画出房价(MEDV)的分布,如图 8.8 所示。
df = pd.read_csv("./housing.data")
# 栏位种类数量
df.shape
# (506, 14)
#栏位数值范围df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()
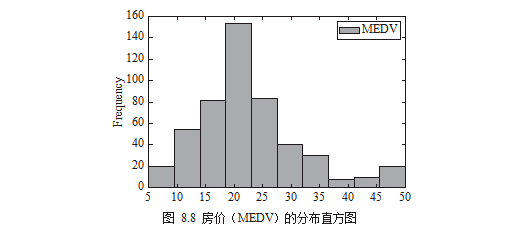
注:图中英文对应笔者在代码中或数据中指定的名字,实践中读者可将它们替换成自己需要的文字。
接下来需要知道的是哪些维度与“房价”关系明显。先用散布图的方式来观察,如图8.9所示。
# draw scatter chart
df.plot.scatter(x='MEDV', y='RM') .
plt.show()
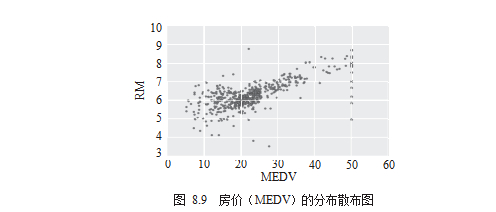
最后,计算相关系数并用聚类热图(Heatmap)来进行视觉呈现,如图 8.10 所示。
# compute pearson correlation
corr = df.corr()
# draw heatmap
import seaborn as sns
corr = df.corr()
sns.heatmap(corr)
plt.show()
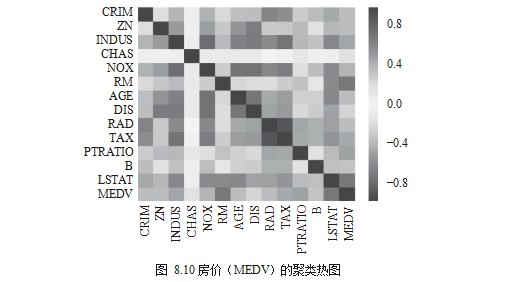
颜色为红色,表示正向关系;颜色为蓝色,表示负向关系;颜色为白色,表示没有关系。RM 与房价关联度偏向红色,为正向关系;LSTAT、PTRATIO 与房价关联度偏向深蓝, 为负向关系;CRIM、RAD、AGE 与房价关联度偏向白色,为没有关系。
声明:本文选自清华大学出版社的《深入浅出python数据分析》一书,略有修改,经出版社授权刊登于此。
相关文章
- 基于Python的人脸识别考勤监控
- Python答题游戏
- Python调用百度API实现图像识别
- Python全栈疫情分析项目
- Python-基础-if语句快速入门
- Python-基础-循环语句快速入门
- Python-GUI签名
- 【2】VScode 搭建python和tensorflow环境
- python 简易时钟
- 【1】windows系统如何安装后缀是whl的python库
- 【2】超级详细Python-matplotlib画图,手把手教你画图!(线条颜色、大小、线形、标签)
- 【4】python读写文件操作---详细讲解!
- 【2】Anaconda下:ipython文件的打开方式,Jupyter Notebook中运行.py文件,快速打开ipython文件的方法!
- 【编写环境一】遇到常见python函数处理方式
- 【编写环境二】python库scipy.stats各种分布函数生成、以及随机数生成【泊松分布、正态分布等】
- Python xlwt数据保存到 Excel中以及xlrd读取excel文件画图
- 强化学习技巧三:Python多进程
- 强化学习技巧五:numba提速python程序
- 【7】python_matplotlib 输出(保存)矢量图方法;画图时图例说明(legend)放到图像外侧;Python_matplotlib图例放在外侧保存时显示不完整问题解决
- 【8】python_matplotlib改变横坐标和纵坐标上的刻度(ticks)、sagemath-list_plot()调整图例(legend)中点的数量、Matplotlib画各种论文图