
使用Mask R-CNN模型实现人体关键节点标注
摘要:在本案例中,我们将展示如何对基础的Mask R-CNN进行扩展,完成人体关键节点标注的任务。
本文分享自华为云社区《使用Mask R-CNN模型实现人体关键节点标注》,作者: 运气男孩。
前言
ModelArts 是面向开发者的一站式 AI 开发平台,为机器学习与深度学习提供海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期 AI 工作流。

背景
Mask R-CNN是一个灵活开放的框架,可以在这个基础框架的基础上进行扩展,以完成更多的人工智能任务。在本案例中,我们将展示如何对基础的Mask R-CNN进行扩展,完成人体关键节点标注的任务。
Mask R-CNN整体架构,它的3个主要网络:
- backbone网络,用于生成特征图
- RPN网络,用于生成实例的位置、分类、分割(mask)信息
- head网络,对位置、分类和分割(mask)信息进行训练
在head网络中,有分类、位置框和分割(mask)信息的3个分支,我们可以对head网络进行扩展,加入一个人体关键节点keypoint分支。并对其进行训练,使得我们的模型具备关键节点分析的能力。那么我们的模型结构将如下图所示:
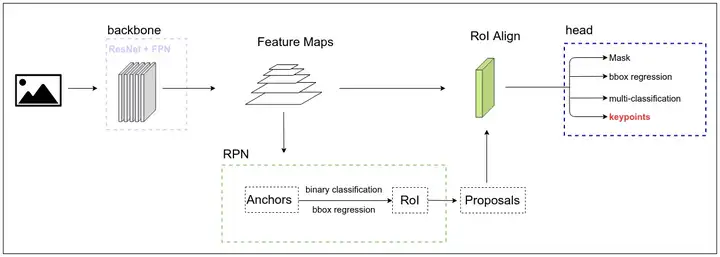
head网络中,红色的keypionts分支为新加入的人体关键节点分支
MaskRCNN模型的解析可以参考此文章 。
本案例的运行环境是 TensorFlow 1.8.0 。
keypoints分支
在RPN中,我们生成Proposal后,当检测到Proposal的分类为"Person"时,对每个部位的关键点生成一个one-hot掩码,训练的目标最终是得到一个56*56的二值掩码,当中只有一个像素被标记为关键点,其余像素均为背景。对于每一个关键点的位置,进行最小化平均交叉熵损失检测,K个关键点是被独立处理的。
人体姿态检测中,人本身可以作为一个目标实例进行分类检测。但是,采取了one-hot编码以后,就可以扩展到coco数据集中被标注的17个人体关键点(例如:左眼、右耳),同时也能够处理非连续型数值特征。
COCO数据集中,对人体中17个关键点进行了标注,包括:鼻子,左眼,右眼,左耳,右耳,左肩,右肩,左肘,右肘,左手腕,右手腕,左膝盖,右膝盖,左脚踝,右脚踝,左小腿,右小腿,如下图所示:

基础环境准备
在使用 ModelArts 进行 AI 开发前,需先完成以下基础操作哦(如有已完成部分,请忽略),主要分为4步(注册–>实名认证–>服务授权–>领代金券):
1、使用手机号注册华为云账号:点击注册
2、点此去完成实名认证,账号类型选"个人",个人认证类型推荐使用"扫码认证"。
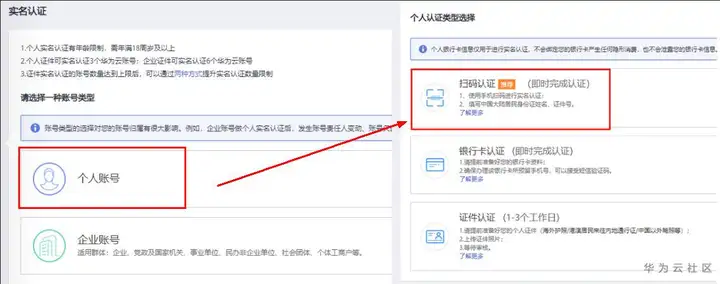
3、点击进入 ModelArts 控制台数据管理页面,上方会提示访问授权,点击【服务授权】按钮,按下图顺序操作:

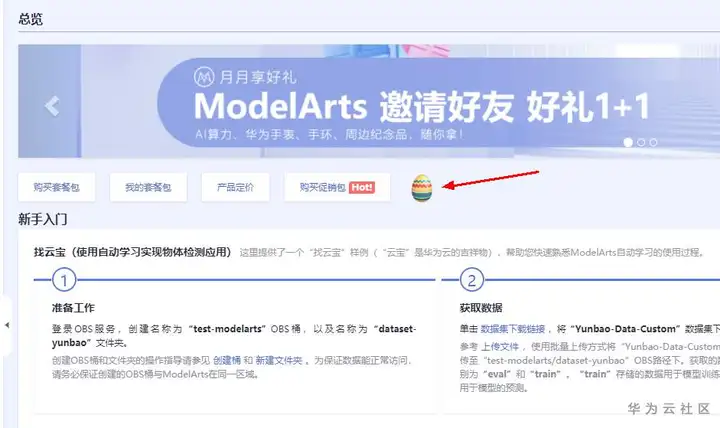
4、进入 ModelArts 控制台首页,如下图,点击页面上的"彩蛋",领取新手福利代金券!后续步骤可能会产生资源消耗费用,请务必领取。
以上操作,也提供了详细的视频教程,点此查看:ModelArts环境配置
在ModelArts中训练Mask R-CNN keypoints模型
准备数据和源代码
第一步:准备数据集和预训练模型
下载完成后,显示如下压缩包

解压后,得到data目录,其结构如下:
data/ ├── mask_rcnn_coco.h5 ├── annotations │ ├── person_keypoints_train2014.json │ ├── ***.json ├── train2014 │ ├── COCO_train2014_***.jpg └── val2014 ├── COCO_val2014_***.jpg复制
其中data/mask_rcnn_coco_humanpose.h5为预训练模型,annotations、train2014和val2014为我们提前准备好的最小数据集,包含了500张图片的标注信息。
第二步:准备源代码


第三步:安装依赖pycocotools
我们使用COCO数据集,需要安装工具库pycocotools


程序初始化
第一步:导入相关的库,定义全局变量

第二步:生成配置项
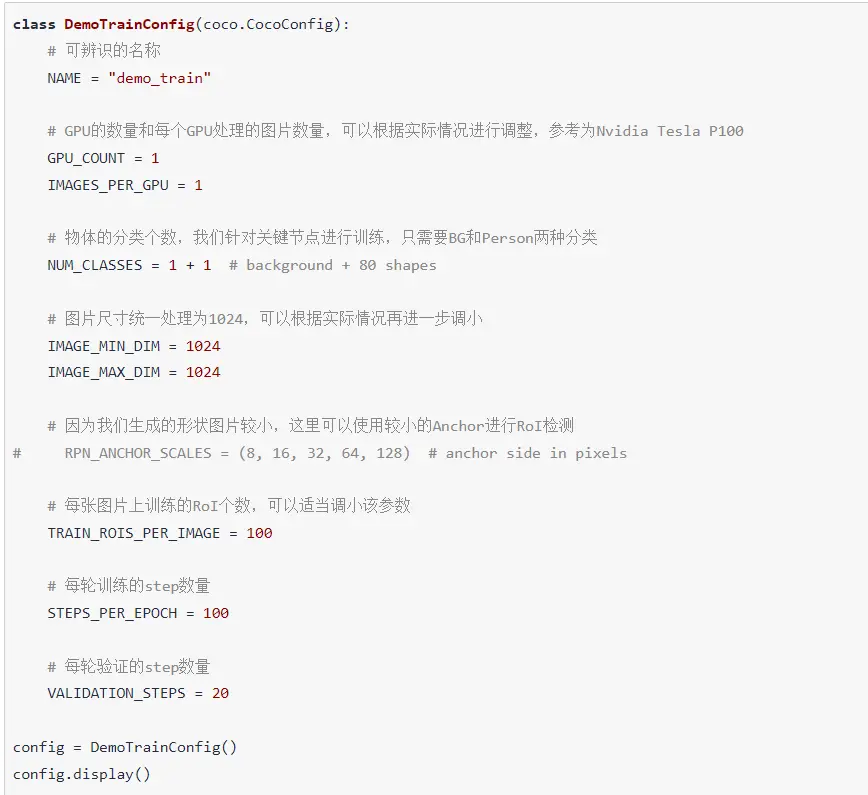
我们定义Config类的子类MyTrainConfig,指定相关的参数,较为关键的参数有:
- __NAME__: Config的唯一名称
- __NUM_CLASSIS__: 分类的数量,我们只生成圆形,正方形和三角形,再加上背景,因此一共是4个分类
- __IMAGE_MIN_DIM和IMAGE_MAX_DIM__: 图片的最大和最小尺寸,我们生成固定的128x128的图片,因此都设置为128
- __TRAIN_ROIS_PER_IMAGE__: 每张图片上训练的RoI个数
- __STEPS_PER_EPOCH和VALIDATION_STEPS__: 训练和验证时,每轮的step数量,减少step的数量可以加速训练,但是检测精度降低
第三步:创建数据集对象
我们使用封装好的CocoDataset类,生成训练集和验证集。

创建模型
用"training"模式创建模型对象,并加载预训练模型

运行完成后输出下面
训练模型
Keras中的模型可以按照制定的层进行构建,在模型的train方法中,我们可以通过layers参数来指定特定的层进行训练。layers参数有以下几种预设值:
- heads:只训练head网络中的分类、mask和bbox回归
- all: 所有的layer
- 3+: 训练ResNet Stage3和后续Stage
- 4+: 训练ResNet Stage4和后续Stage
- 5+: 训练ResNet Stage5和后续Stage
此外,layers参数还支持正则表达式,按照匹配规则指定layer,可以调用model.keras_model.summary()查看各个层的名称,然后按照需要指定要训练的层。
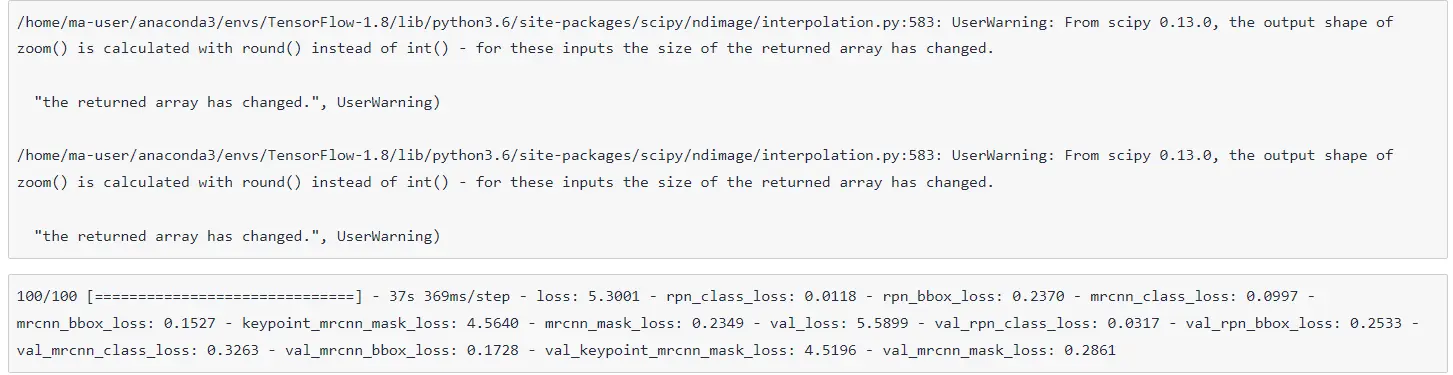
我们针对不同的layer进行训练,首先,训练head网络中的4个分支:

输出结果:

然后训练ResNet Stage4和后续Stage

最后,对所有layer进行优化,并将训练的模型保存到本地

输出结果:


使用模型检测图片物体
第一步:创建"Inference"模式的模型对象,并加载我们训练好的模型文件


第二步:从验证数据集中随机选出一张图片,显式Ground Truth信息

输出结果,识别图片如下:

第三步:使用模型对图片进行预测,并显示结果

最终识别结果:

总结
使用Mask R-CNN模型实现人体关键节点标注,在head网络中,有分类、位置框和分割(mask)信息的3个分支,我们可以对head网络进行扩展,加入一个人体关键节点keypoint分支。并对其进行训练,使得我们的模型具备关键节点分析的能力。对人体中17个关键点进行了标注,包括:鼻子,左眼,右眼,左耳,右耳,左肩,右肩,左肘,右肘,左手腕,右手腕,左膝盖,右膝盖,左脚踝,右脚踝,左小腿,右小腿,并且取得了不错的效果。
相关文章
- 与下属面谈,是我应该做的吗?
- UI自动化工具4399AT全方面更新
- iOS界面黑白实现
- 【C语言】计算器
- 将模型转为NNIE框架支持的wk模型第一步:tensorflow->caffe
- 不同数据库模式下DATE类型的行为解析
- 探索专有领域的端到端ASR解决之道
- 再不解决延迟不当,小心你的内存被打爆
- CG行业云渲染服务的演进之路
- 云小课 | 华为云KYON之L2CG
- 做开发,这几种锁机制你不得不了解一下
- 超详细的jQuery的 DOM操作,一篇就足够!
- 解密华为云FusionInsight MRS新特性:一架构三湖
- 一文带你认识MindSpore新一代分子模拟库SPONGE
- MindSpore:不用摘口罩也知道你是谁
- 技术干货 | 基于MindSpore更好的理解Focal Loss
- 云小课|DSC帮您管数据,保障您的云上数据安全
- 多方安全计算:隐私保护集合求交技术
- 保障实时音视频服务体验,华为云原生媒体网络有7大秘籍
- 云小课 | 玩转HiLens Studio之手机实时视频流调试代码