
正则表示式
假设你在一篇英文小说里查找hi,你可以使用正则表达式hi。
但是,很多单词里包含hi这两个连续的字符,比如him,history,high等等。用hi来查找的话,这里边的hi也会被找出来。如果要精确地查找hi这个单词的话,我们应该使用\bhi\b。
例子:
\bhi\b.*\bLucy\b 先是一个单词hi,然后是任意个任意字符(换行符以外),最后是Lucy这个单词。
\(?0\d{2}[\)\ -]?\d{8} 这个表达式可以匹配几种格式的电话号码,像(010)88886666,或022-22334455,或02912345678等。我们对它进行一些分析吧:首先是一个转义字符\(,它能出现0次或1次(?),然后是一个0,后面跟着2个数字(\d{2}),然后是)或-或空格中的一个,它出现1次或不出现(?),最后是8个数字(\d{8})。
贪婪模式和非贪婪模式:
区分.*和.*?
"张啊咩","小啊咩" //用正则检索这样一个字符串
//第一种贪婪模式,结果为: 1 处匹配:"张啊咩","小啊咩"
/\".*\"/
//第二种非贪婪模式,结果为: 2 处匹配:"张啊咩"和"小啊咩"
/\".*?\"/
如果用
下面给出一些正则的特殊符号表格:
元字符:
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
重复:
| 代码 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
反义:
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
tips:
JavaScript 的正则语法中,在这个语法里,[] 中貌似除了 \ ] - 这三个字符之外,任何特殊字符都都不需要转义。同样也不能在中括号中用到特殊字符原本的功能
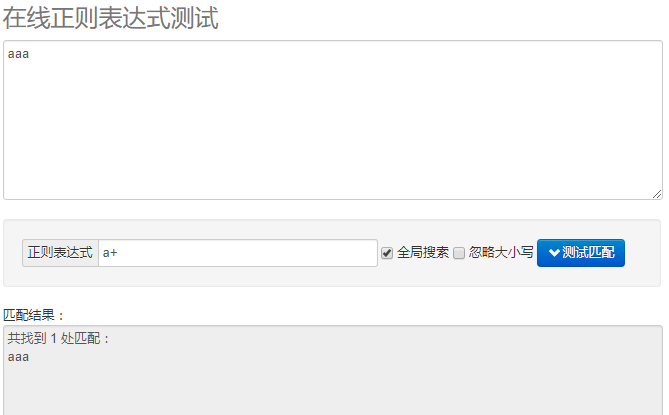
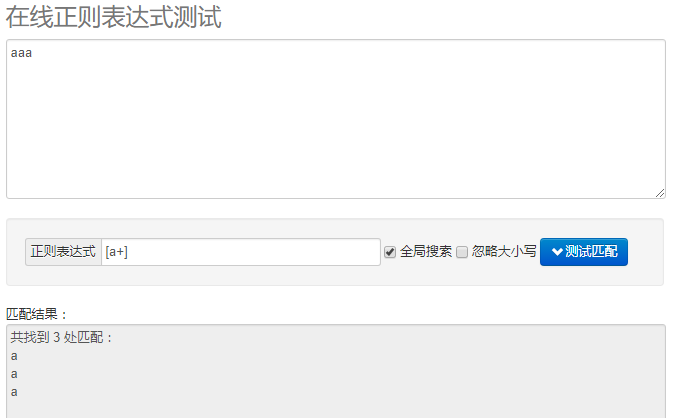
如下图:a+ 本来表示匹配一个或者多个a字符,放在中括号中就变成了匹配a字符或者+字符了
断言:
JS不支持负向的 (?<=exp) 和 (?<!exp),只支持正向的(?=exp) 和 (?!exp)。
正向断言,就是跟在字符后面的,例如 (?=exp)
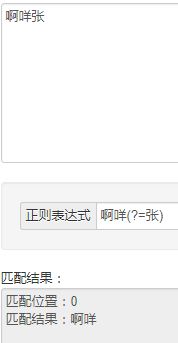

这里 "啊咩(?=张)" 表示匹配 "啊咩张",但是匹配结果不包含"张",正向正能放在啊咩后面,不支持放在前面
一些常用的正则表达式:
数字加逗号:'10000000'.replace(/(\d)(?=(?:\d{3})+$)/g, '$1,') ----> "10,000,000"
汉字:^[\u4e00-\u9fa5]{0,}$
(abc|def)和[abc|def]的区别
/^(abc|def)$/的意思是abc或者def。
/^[abc|def]$/的意思和/^[abcdef]$/一样,只能是abcdef的其中一个字符。