
hdfs平衡分布
HDFS 分布 平衡
2023-09-14 09:00:25 时间
这篇文章是从网上看到的,觉得很好就收藏了,但是最终不知道出处了。介绍hdfs平衡分布~
这篇文章是从网上看到的,觉得很好就收藏了,但是最终不知道出处了。 Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点。当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之间无法达到更好的网络带宽使用率,机器磁盘无法利用等等。可见,保证HDFS中的数据平衡是非常重要的。 在Hadoop中,包含一个Balancer程序,通过运行这个程序,可以使得HDFS集群达到一个平衡的状态,使用这个程序的命令如下: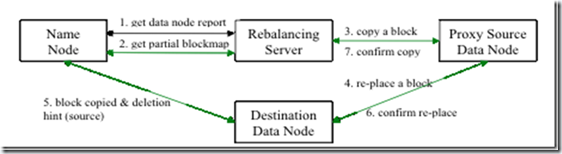
Rebalance程序作为一个独立的进程与name node进行分开执行。 1)Rebalance Server从Name Node中获取所有的Data Node情况:每一个Data Node磁盘使用情况。 2)Rebalance Server计算哪些机器需要将数据移动,哪些机器可以接受移动的数据。并且从Name Node中获取需要移动的数据分布情况。 3)Rebalance Server计算出来可以将哪一台机器的block移动到另一台机器中去。 4)5)6)需要移动block的机器将数据移动的目的机器上去,同时删除自己机器上的block数据。 7)Rebalance Server获取到本次数据移动的执行结果,并继续执行这个过程,一直没有数据可以移动或者HDFS集群以及达到了平衡的标准为止。 Hadoop现有的这种Balancer程序工作的方式在绝大多数情况中都是非常适合的。 现在我们设想这样一种情况: 1. 数据是3份备份。 2. HDFS由2个rack组成。 3. 2个rack中的机器磁盘配置不同,第一个rack中每一台机器的磁盘空间为1TB,第二个rack中每一台机器的磁盘空间为10TB。 4. 现在大多数数据的2份备份都存储在第一个rack中。 在这样的一种情况下,HDFS级群中的数据肯定是不平衡的。现在我们运行Balancer程序,但是会发现运行结束以后,整个HDFS集群中的数据依旧不平衡:rack1中的磁盘剩余空间远远小于rack2。 这是因为Balance程序的开发原则1导致的。 简单的说,就是在执行Balancer程序的时候,不会将数据中一个rack移动到另一个rack中,所以就导致了Balancer程序永远无法平衡HDFS集群的情况。 针对于这种情况,可以采取2中方案: 1. 继续使用现有的Balancer程序,但是修改rack中的机器分布。将磁盘空间小的机器分叉到不同的rack中去。 2. 修改Balancer程序,允许改变每一个rack中所具备的block数量,将磁盘空间告急的rack中存放的block数量减少,或者将其移动到其他磁盘空间富余的rack中去。
HDFS的副本放置策略及机架感知 副本放置策略的基本思想是: 第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。 第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。 第三个副本和第二个在同一个机架,随机放在不同的node中。
Hadoop-NameNode内存预估 NameNode通过NetworkTopology维护整个集群的树状拓扑结构;拓扑结构的叶子节点DatanodeDescriptor是标识DataNode的关键结构。DataNode节点一般会挂载多块不同类型存储单元;StorageMap描述的正是存储介质DatanodeStorageInfo集合(Map默认长度16)。
Flink落HDFS数据按事件时间分区解决方案 0x1 摘要 Hive离线数仓中为了查询分析方便,几乎所有表都会划分分区,最为常见的是按天分区,Flink通过以下配置把数据写入HDFS, BucketingSink Object sink = new BucketingSink (path); //通过这样的方式来实现数据跨天分区 sink.
浅谈HBase的数据分布 HBase的rowkey设计一直都是难点和痛点,不合适的rowkey设计会导致读写性能、吞吐不佳等诸多问题。本文从数据分布问题展开,介绍HBase基于Range的分布策略与region的调度问题,详细讨论了rowkey的比较规则及其应用,希望能够加深用户对HBase数据分布机制和rowkey的理解,从而做出更合适的设计,精准、高效的使用HBase。
Namenode 是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
这篇文章是从网上看到的,觉得很好就收藏了,但是最终不知道出处了。 Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点。当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之间无法达到更好的网络带宽使用率,机器磁盘无法利用等等。可见,保证HDFS中的数据平衡是非常重要的。 在Hadoop中,包含一个Balancer程序,通过运行这个程序,可以使得HDFS集群达到一个平衡的状态,使用这个程序的命令如下:
sh $HADOOP_HOME/bin/start-balancer.sh –t 10%这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。 Hadoop的开发人员在开发Balancer程序的时候,遵循了以下几点原则: 1.在执行数据重分布的过程中,必须保证数据不能出现丢失,不能改变数据的备份数,不能改变每一个rack中所具备的block数量。 2.系统管理员可以通过一条命令启动数据重分布程序或者停止数据重分布程序。 3.Block在移动的过程中,不能暂用过多的资源,如网络带宽。 4.数据重分布程序在执行的过程中,不能影响name node的正常工作。 基于这些基本点,目前Hadoop数据重分布程序实现的逻辑流程如下图所示:
Rebalance程序作为一个独立的进程与name node进行分开执行。 1)Rebalance Server从Name Node中获取所有的Data Node情况:每一个Data Node磁盘使用情况。 2)Rebalance Server计算哪些机器需要将数据移动,哪些机器可以接受移动的数据。并且从Name Node中获取需要移动的数据分布情况。 3)Rebalance Server计算出来可以将哪一台机器的block移动到另一台机器中去。 4)5)6)需要移动block的机器将数据移动的目的机器上去,同时删除自己机器上的block数据。 7)Rebalance Server获取到本次数据移动的执行结果,并继续执行这个过程,一直没有数据可以移动或者HDFS集群以及达到了平衡的标准为止。 Hadoop现有的这种Balancer程序工作的方式在绝大多数情况中都是非常适合的。 现在我们设想这样一种情况: 1. 数据是3份备份。 2. HDFS由2个rack组成。 3. 2个rack中的机器磁盘配置不同,第一个rack中每一台机器的磁盘空间为1TB,第二个rack中每一台机器的磁盘空间为10TB。 4. 现在大多数数据的2份备份都存储在第一个rack中。 在这样的一种情况下,HDFS级群中的数据肯定是不平衡的。现在我们运行Balancer程序,但是会发现运行结束以后,整个HDFS集群中的数据依旧不平衡:rack1中的磁盘剩余空间远远小于rack2。 这是因为Balance程序的开发原则1导致的。 简单的说,就是在执行Balancer程序的时候,不会将数据中一个rack移动到另一个rack中,所以就导致了Balancer程序永远无法平衡HDFS集群的情况。 针对于这种情况,可以采取2中方案: 1. 继续使用现有的Balancer程序,但是修改rack中的机器分布。将磁盘空间小的机器分叉到不同的rack中去。 2. 修改Balancer程序,允许改变每一个rack中所具备的block数量,将磁盘空间告急的rack中存放的block数量减少,或者将其移动到其他磁盘空间富余的rack中去。
HDFS的副本放置策略及机架感知 副本放置策略的基本思想是: 第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。 第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。 第三个副本和第二个在同一个机架,随机放在不同的node中。
Hadoop-NameNode内存预估 NameNode通过NetworkTopology维护整个集群的树状拓扑结构;拓扑结构的叶子节点DatanodeDescriptor是标识DataNode的关键结构。DataNode节点一般会挂载多块不同类型存储单元;StorageMap描述的正是存储介质DatanodeStorageInfo集合(Map默认长度16)。
Flink落HDFS数据按事件时间分区解决方案 0x1 摘要 Hive离线数仓中为了查询分析方便,几乎所有表都会划分分区,最为常见的是按天分区,Flink通过以下配置把数据写入HDFS, BucketingSink Object sink = new BucketingSink (path); //通过这样的方式来实现数据跨天分区 sink.
浅谈HBase的数据分布 HBase的rowkey设计一直都是难点和痛点,不合适的rowkey设计会导致读写性能、吞吐不佳等诸多问题。本文从数据分布问题展开,介绍HBase基于Range的分布策略与region的调度问题,详细讨论了rowkey的比较规则及其应用,希望能够加深用户对HBase数据分布机制和rowkey的理解,从而做出更合适的设计,精准、高效的使用HBase。
Namenode 是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
相关文章
- HDFS Exlorer初体验
- Hadoop 使用Linux操作系统与Java熟悉常用的HDFS操作
- 漫画大数据:为啥我把 HDFS 文件权限都改成 777 了还是删不掉?
- 采集文件到HDFS
- HDFS知识点总结详解大数据
- HDFS的Java客户端操作代码(查看HDFS下所有的文件或目录)详解大数据
- HDFS冗余数据块的自动删除详解大数据
- Hadoop2.7.6_03_HDFS原理详解大数据
- HDFS的shell操作详解大数据
- HDFS详解(1)大数据
- 查看HDFS文件系统数据的三种方法详解大数据
- HDFS源码分析(六)—–租约详解大数据
- HDFS源码分析(一)—–INode文件节点详解大数据
- Hadoop2源码分析-HDFS核心模块分析详解大数据
- 大数据存储解决方案:HDFS与MongoDB(hdfsmongodb)
- 比较分析HDFS与Oracle数据库的异同(hdfs oracle)