
Scala - 快速学习09 - 函数式编程:一些操作
2023-09-14 09:00:40 时间
1- 集合类(collection)
系统地区分了可变的和不可变的集合。
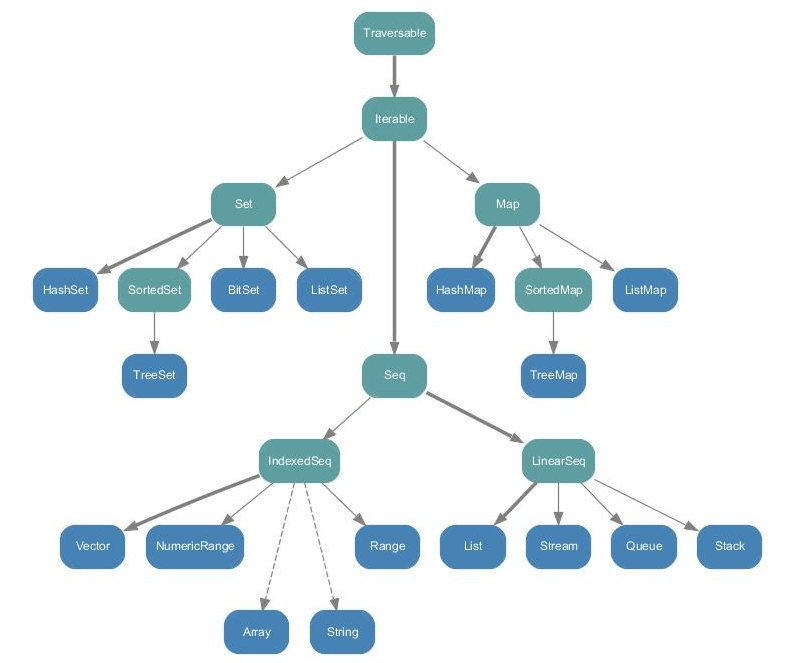
scala.collection包中所有的集合类
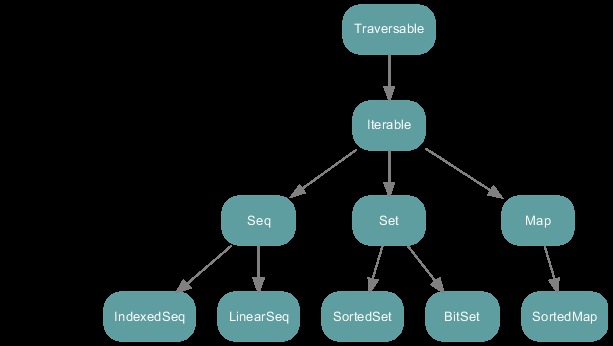
可变集合(Mutable)
顾名思义,意味着可以修改,移除或者添加一个元素。
scala.collection.mutable 中的所有集合类:
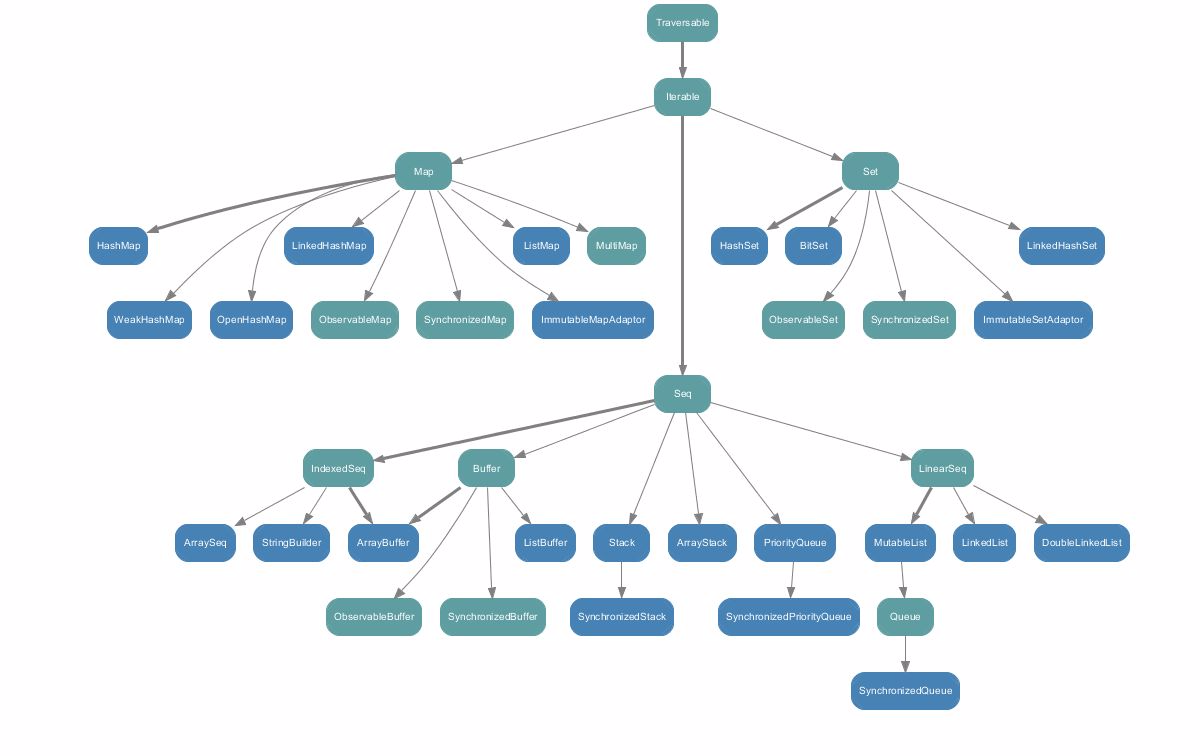
不可变集合(Immutable)
- 对不可变集合的操作(修改,添加,删除某个集合元素),都是返回一个新的集合,原来的集合不会发生改变。
- 由于“永远不会被改变”的特性,可以说不可变集合是线程安全的。
- Scala在默认情况下采用的是不可变集合。在使用上,优先使用不可变集合。
- 不可变集合适用于大多数情况。
scala.collection.immutable 中的所有集合类:
2- 列表(List)
List[T]
val a = List(1, 2, 3, 4) //> a : List[Int] = List(1, 2, 3, 4)
val b = 0 :: a //> b : List[Int] = List(0, 1, 2, 3, 4)
val c = "x" :: "y" :: "z" :: Nil //> c : List[String] = List(x, y, z)
val r0 = "z" :: Nil //> r0 : List[String] = List(z)
val r1 = "y" :: r0 //> r1 : List[String] = List(y, z)
val r2 = "x" :: r1 //> r2 : List[String] = List(x, y, z)
val d = a ::: c //> d : List[Any] = List(1, 2, 3, 4, x, y, z)
d.head //> res0: Any = 1
d.tail //> res1: List[Any] = List(2, 3, 4, x, y, z)
d.isEmpty //> res2: Boolean = false
Nil.isEmpty //> res3: Boolean = true
def test(tlist: List[Int]): String = {
if (tlist.isEmpty) ""
else tlist.head.toString + " " + test(tlist.tail)
} //> test: (tlist: List[Int])String
test(a) //> res4: String = "1 2 3 4 "
val test = List(1, 2, 3, 4, 5) //> test : List[Int] = List(1, 2, 3, 4, 5)
test.filter(x => x % 2 == 1) //> res0: List[Int] = List(1, 3, 5)
"Double in 2018!".toList //> res1: List[Char] = List(D, o, u, b, l, e, , i, n, , 2, 0, 1, 8, !)
"Double in 2018!".toList.filter(x => Character.isDigit(x))
//> res2: List[Char] = List(2, 0, 1, 8)
"Double in 2018!".toList.takeWhile(x => x != 'i')
//> res3: List[Char] = List(D, o, u, b, l, e, )
列表的遍历
可以使用for循环或foreach进行遍历
val list = List(1, 2, 3) //> list : List[Int] = List(1, 2, 3)
for (elem <- list) println(elem) //> 1
//| 2
//| 3
list.foreach(elem => print(elem)) //> 123
list.foreach(print) //> 123
3- 映射(Map)
键值对的集合
val test = Map(1 -> "Anliven", 9 -> "Angel") //> test : scala.collection.immutable.Map[Int,String] = Map(1 -> Anliven, 9 ->
//| Angel)
test(1) //> res0: String = Anliven
test(9) //> res1: String = Angel
test.contains(1) //> res2: Boolean = true
test.contains(2) //> res3: Boolean = false
test.keys //> res4: Iterable[Int] = Set(1, 9)
test.values //> res5: Iterable[String] = MapLike.DefaultValuesIterable(Anliven, Angel)
test + (8 -> "888") //> res6: scala.collection.immutable.Map[Int,String] = Map(1 -> Anliven, 9 -> An
//| gel, 8 -> 888)
test - 1 //> res7: scala.collection.immutable.Map[Int,String] = Map(9 -> Angel)
test ++ List(2 -> "222", 3 -> "333") //> res8: scala.collection.immutable.Map[Int,String] = Map(1 -> Anliven, 9 -> An
//| gel, 2 -> 222, 3 -> 333)
test ++ List(2 -> "222", 3 -> "333") -- List(1, 9)
//> res9: scala.collection.immutable.Map[Int,String] = Map(2 -> 222, 3 -> 333)
映射的遍历
循环遍历映射的基本格式:for ((k,v) <- 映射) 语句块
可以同时遍历k和v,也可以只遍历映射中的k或者v
val test3 = Map("1" -> "AAA", "2" -> "BBB", "3" -> "CCC")
//> test3 : scala.collection.immutable.Map[String,String] = Map(1 -> AAA, 2 -> B
//| BB, 3 -> CCC)
for ((k, v) <- test3) printf("Key is : %s and Value is: %s\n", k, v)
//> Key is : 1 and Value is: AAA
//| Key is : 2 and Value is: BBB
//| Key is : 3 and Value is: CCC
for (k <- test3.keys) println(k) //> 1
//| 2
//| 3
for (v <- test3.values) println(v) //> AAA
//| BBB
//| CCC
for (x <- test3) println(x) //> (1,AAA)
//| (2,BBB)
//| (3,CCC)
4- Range与Stream
- range 整数序列
- stream 惰性求值列表
1 to 10 //> res0: scala.collection.immutable.Range.Inclusive = Range 1 to 10 1 to 10 by 2 //> res1: scala.collection.immutable.Range = inexact Range 1 to 10 by 2 (1 to 10).toList //> res2: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) 1 until 10 //> res3: scala.collection.immutable.Range = Range 1 until 10 1 until 10 by 2 //> res4: scala.collection.immutable.Range = inexact Range 1 until 10 by 2 1 #:: 2 #:: 3 #:: Stream.empty //> res5: scala.collection.immutable.Stream[Int] = Stream(1, ?) val stream = (1 to 123456789).toStream //> stream : scala.collection.immutable.Stream[Int] = Stream(1, ?) stream.head //> res6: Int = 1 stream.tail //> res7: scala.collection.immutable.Stream[Int] = Stream(2, ?)
5- Tuple
与数据库的记录概念类似
(1, 2) //> res0: (Int, Int) = (1,2)
1 -> 2 //> res1: (Int, Int) = (1,2)
(1, "Alice", "Math", 95.5) //> res2: (Int, String, String, Double) = (1,Alice,Math,95.5)
val test = (1, "Alice", "Math", 95.5) //> test : (Int, String, String, Double) = (1,Alice,Math,95.5)
test._1 //> res3: Int = 1
test._2 //> res4: String = Alice
test._3 //> res5: String = Math
test._4 //> res6: Double = 95.5
val test2 = List(1, 2, 3, 4, 5) //> test2 : List[Int] = List(1, 2, 3, 4, 5)
def sumSq(in: List[Int]): (Int, Int, Int) =
in.foldLeft((0, 0, 0))((t, v) => (t._1 + 1, t._2 + v, t._3 + v * v))
//> sumSq: (in: List[Int])(Int, Int, Int)
sumSq(test2) //> res7: (Int, Int, Int) = (5,15,55)
6- 集合操作
Map操作与flatMap操作
Map操作是针对集合的典型变换操作,主要用作元素的转换。
Map操作将某个函数应用到集合中的每个元素,并产生一个结果集合。
示例:给定一个字符串列表,我们可以通过map操作对列表的中每个字符串进行变换,变换后可以得到一个新的集合。
val test = List[String]("x", "y", "z") //> test : List[String] = List(x, y, z)
test.map(x => x.toUpperCase) //> res0: List[String] = List(X, Y, Z)
test.map(_.toUpperCase) //> res1: List[String] = List(X, Y, Z)
val test2 = List(1, 2, 3, 4, 5) //> test2 : List[Int] = List(1, 2, 3, 4, 5)
test2.filter(x => x % 2 == 1) //> res2: List[Int] = List(1, 3, 5)
test2.filter(_ % 2 == 1) //> res3: List[Int] = List(1, 3, 5)
test2.filter(_ % 2 == 1).map(_ + 10) //> res4: List[Int] = List(11, 13, 15)
val test3 = List(test2, List(6, 7, 8, 9, 0)) //> test3 : List[List[Int]] = List(List(1, 2, 3, 4, 5), List(6, 7, 8, 9, 0))
test3.map(x => x.filter(_ % 2 == 0)) //> res5: List[List[Int]] = List(List(2, 4), List(6, 8, 0))
test3.map(_.filter(_ % 2 == 0)) //> res6: List[List[Int]] = List(List(2, 4), List(6, 8, 0))
test3.flatMap(_.filter(_ % 2 == 0)) //> res7: List[Int] = List(2, 4, 6, 8, 0)
flatMap操作是Map操作的一种扩展。
在flatMap中传入一个函数,该函数对每个输入都会返回一个集合(而不是一个元素),然后,flatMap把生成的多个集合“拍扁”成为一个集合。
val myStr = List("AAA", "BBB", "CCC") //> myStr : List[String] = List(AAA, BBB, CCC)
myStr flatMap (s => s.toList) //> res0: List[Char] = List(A, A, A, B, B, B, C, C, C)
myStr.flatMap(s => s.toList) //> res1: List[Char] = List(A, A, A, B, B, B, C, C, C)
示例说明:对于列表myStr中的每个元素,都执行Lamda表达式定义的匿名函数“s => s.toList”,myStr中的每个元素都调用toList,生成一个字符集合List[Char],最后,flatMap把这些集合中的元素“拍扁”得到一个集合List。
filter操作
filter操作:遍历一个集合并从中获取满足指定条件的元素组成一个新的集合。
filter操作还可以做进一步操作,例如:过滤指定内容开头的元素等。
val testMap = Map(11 -> "ABC", 22 -> "BCD", 33 -> "CDE")
//> testMap : scala.collection.immutable.Map[Int,String] = Map(11 -> ABC, 22 ->
//| BCD, 33 -> CDE)
val testFilter = testMap filter { kv => kv._2 contains "BC" }
//> testFilter : scala.collection.immutable.Map[Int,String] = Map(11 -> ABC, 22
//| -> BCD)
testFilter foreach { kv => println(kv._1 + ":" + kv._2) }
//> 11:ABC
//| 22:BCD
val testMap2 = Map(1 -> "ab", 2 -> "ac", 3 -> "bc")
//> testMap2 : scala.collection.immutable.Map[Int,String] = Map(1 -> ab, 2 -> a
//| c, 3 -> bc)
val testFilter2 = testMap2 filter { kv => kv._2 startsWith "a" }
//> testFilter2 : scala.collection.immutable.Map[Int,String] = Map(1 -> ab, 2 -
//| > ac)
testFilter2 foreach { kv => println(kv._1 + ":" + kv._2) }
//> 1:ab
//| 2:ac
reduce操作(归约)与fold操作(折叠)
reduce操作(归约)
- 使用reduce可以对集合中的元素进行归约,包含reduceLeft和reduceRight两种操作。
- reduceLeft从集合的头部开始操作,reduceRight从集合的尾部开始操作。
- reduce默认采用的是reduceLeft,其原型:reduceLeft(op: (T, T) => T)
val test = List(1, 2, 3, 4, 5) //> test : List[Int] = List(1, 2, 3, 4, 5) test.reduceLeft((x, y) => x + y) //> res0: Int = 15 test.reduceLeft(_ + _) //> res1: Int = 15 test.reduceRight(_ + _) //> res2: Int = 15 test.reduceLeft(_ - _) //> res3: Int = -13 test.reduceRight(_ - _) //> res4: Int = 3 test.reduce(_ - _) //> res5: Int = -13
示例说明:
- reduceLeft(_ - _)表示从列表头部开始,对两两元素进行求和操作
- reduceRight(_ - _)表示从列表尾部开始,对两两元素进行求和操作
- 下划线是占位符表示当前获取的两个元素,两个下划线之间的是操作符,表示对两个元素进行的操作
- 直接使用reduce,等同于reduceLeft
fold操作(折叠)
fold操作和reduce操作类似,但需要指定一个初始值,并以该值作为上下文,处理集合中的每个元素。
fold函数需要两个参数,一个参数是初始种子值,另一个参数是用于计算结果的累计函数。
包含foldLeft()和foldRight()两种操作。
- foldLeft(),第一个参数为累计值,从集合的头部开始操作。
- foldRight(),第二个参数为累计值,从集合的尾部开始操作。
fold默认采用的是foldLeft,其原型:foldLeft(z: U)(op: (U, T) => U)
val test = List(1, 2, 3, 4, 5) //> test : List[Int] = List(1, 2, 3, 4, 5) test.foldLeft(0)(_ + _) //> res0: Int = 15 test.foldRight(0)(_ + _) //> res1: Int = 15 test.foldLeft(0)(_ - _) //> res2: Int = -15 test.foldRight(0)(_ - _) //> res3: Int = 3 test.fold(0)(_ - _) //> res4: Int = -15 test.fold(10)(_ * _) //> res5: Int = 1200
示例说明:
执行test.fold(10)(_ * _)时,首先把初始值拿去和list中的第一个值1做乘法操作,得到累乘值10,然后再拿这个累乘值10去和list中的第2个值2做乘法操作,得到累乘值20,依此类推,一直得到最终的累乘结果1200。
7- 实例WordCount
按照函数式编程的风格,编写一个程序,对某个目录下所有文件中的单词进行词频统计。
1 - 在目录“D:\Anliven-Running\Zen\ScalaProjets\temptest”创建如下两个文件:
word1.txt
this is a test ! 1,2,3 4,5,6,7,8,9
word2.txt
1,2,3 4,5,6,7,8,9 4,5,6,7,8,9 this is a test !
2 - 编辑并运行如下代码:
package testscala
import java.io.File
import scala.io.Source
object TestScala {
def main(args: Array[String]): Unit = {
val dirfile = new File("D:\\Anliven-Running\\Zen\\ScalaProjets\\temptest")
val files = dirfile.listFiles //得到数组files
for (file <- files) println(file) //遍历数组
val aFilesList = files.toList //Array类的toList方法将连续存放的数组转换为递归存放的列表
val wordsMap = scala.collection.mutable.Map[String, Int]() //定义一个Map变量,key是单词,value是单词数量
aFilesList.foreach(
file => Source.fromFile(file).getLines().foreach(
line => line.split(" ").foreach(
word => {
if (wordsMap.contains(word)) {
wordsMap(word) += 1
} else {
wordsMap += (word -> 1)
}
})))
println(wordsMap) //打印内容
for ((key, value) <- wordsMap) println(key + ": " + value) //遍历内容
}
}
代码说明:
- 如果是在Linux系统下运行,目录格式应为“/d/Anliven-Running/Zen/ScalaProjets/temptest”
- aFilesList.foreach()对列表aFilesList中的每个元素进行遍历操作,按照括号中定义的逻辑进行处理
- file => Source.fromFile(file).getLines().foreach()遍历获取列表aFilesList的元素值(文件路径名)并赋值给file,然后调用getLines()方法获取该文件的所有行,并执行foreach()方法遍历所有行
- line=>line.split(" ").foreach()对一行内容进行切分得到一个集合,然后调用foreach()方法圆括号中定义的处理逻辑遍历集合
- foreach()方法中处理逻辑的功能是,对于当前遍历到的某个单词,如果这个单词以前已经统计过,就把映射中以该单词为key的映射条目的value增加1。如果以前没有被统计过,则为这个单词新创建一个映射条目。
3 - 运行结果:
D:\Anliven-Running\Zen\ScalaProjets\temptest\word1.txt D:\Anliven-Running\Zen\ScalaProjets\temptest\word2.txt Map(is -> 2, 1,2,3 -> 2, a -> 2, 4,5,6,7,8,9 -> 3, ! -> 2, this -> 2, test -> 2) is: 2 1,2,3: 2 a: 2 4,5,6,7,8,9: 3 !: 2 this: 2 test: 2
相关文章
- Scala 【15 Actor 入门 】
- Scala 【 7 object 】
- Scala 【 5 数组常见操作和 Map 】
- Scala和Python有什么区别?
- SDP(13): Scala.Future – far from completion,绝不能用来做甩手掌柜详解编程语言
- 怎样学习Scala泛函编程详解编程语言
- Scala编程快速入门系列(二)详解编程语言
- Scala编程快速入门系列(一)详解编程语言
- 使用Scala操作MySQL数据库(scalamysql)
- 《Scala教程》 2.Scala Overview
- Linux平台上的Scala编程语言简介(linuxscala)
- 利用Scala轻松连接Redis(scala连接redis)
- Scala高效操作Redis实现高性能数据读取(scala读取redis)