
MaxCompute 中的Code Generation技术简介
2023-09-14 09:00:28 时间
前言
在《数据库系统中的Code Generation技术介绍》中,我们简单介绍了一下Code Generation技术及其在大规模OLAP系统,特别是大规模分布式OLAP系统中的重要性。MaxCompute采用了Code Generation技术来提高计算效率。在MaxCompute
前言 在《数据库系统中的Code Generation技术介绍》中,我们简单介绍了一下Code Generation技术及其在大规模OLAP系统,特别是大规模分布式OLAP系统中的重要性。MaxCompute采用了Code Generation技术来提高计算效率。在MaxCompute2.0中,我们又引入了基于LLVM的JIT(Just In Time) Code Generation技术。结合向量化的执行引擎,基于SIMD技术的执行效率优化等方式,较之MaxCompute 1.0,MaxCompute 2.0在性能方便有了较大的提升,具体可以参照《MaxCompute2.0性能评测:更强大、更高效之上的更快速》。
MaxCompute 1.0中的Code Generation
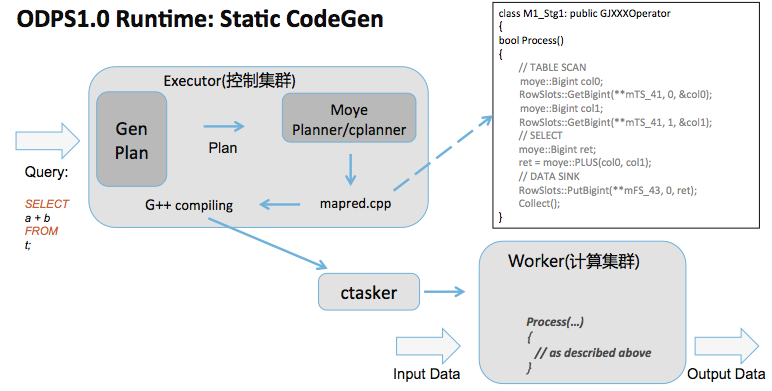 如上图,MaxCompute 1.0采用了静态的Code Generation技术,工作主要在MaxCompute控制集群中名为“Executor”的角色上完成。其流程如下:
如上图,MaxCompute 1.0采用了静态的Code Generation技术,工作主要在MaxCompute控制集群中名为“Executor”的角色上完成。其流程如下:
用户的SQL语句在Executor上经过Parsing和Optimization之后,生成对应的查询计划。 Executor上的Code Generation模块将查询计划翻译成一个名为“mapred.cpp”的C++源文件。如上图所示,查询计划中的每一个Task(就是MaxCompute作业中的一个Stage)会被翻译成C++中的一个Class, 而所有的处理逻辑被生成到该Class的Process()方法当中。 Executor调用g++将“mapred.cpp”编译成一个动态库,并将其下发到计算集群中的每一个Worker上。 被调度起来的Worker会Load该动态库,调用相应的Process()方法以完成计算逻辑。 可以看到,利用Code Generation技术,对于每一个SQL来说执行时代码都是经过定制的,因此执行效率较传统的Volcano Model更好。但是,其中也有一些问题。
g++ 编译还是比较消耗CPU/内存的,特别是当优化选项开到O2以上的时候。特别是用户SQL比较复杂的情况下(有些SQL在SELECT语句中有多达上千个表达式,或者表达式的嵌套计算特别深入),生成的C++源文件也比较大,编译更加耗时。在实际生产中,我们见过编译耗时数十秒,消耗上G内存的情况。 生成的动态库在控制集群和计算集群之间传输也会有带来一定的网络开销。因为这个动态库的与SQL逻辑紧密相关的,因此无法复用,因此每个SQL都会经历编译,下发的过程,在任务提交比较频繁的情况下,控制集群的稳定性会收到一定挑战。 因为较高的编译时开销,这种Code Generation的方式在处理复杂的语句加中小数据规模查询的场景,比如service mode下,overhead太大。 MaxCompute 2.0中的Code Generation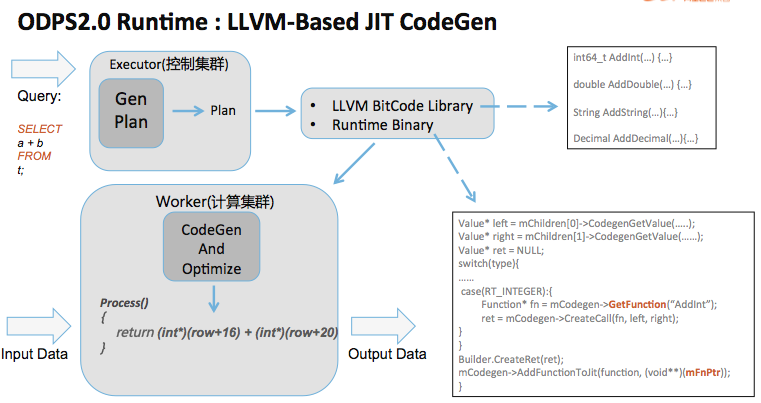
MaxCompute 2.0采用了基于LLVM的JIT Code Generation技术。所谓JIT,就是程序在运行期间根据需要动态生成相应的机器指令。这样,整个Code Generation的工作由控制集群移交到了真正执行计算逻辑的计算集群各个Worker上。其流程如下:
和MaxCompute 1.0中一样,用户的SQL语句在Executor上经过Parsing和Optimization之后,生成对应的查询计划。 查询计划直接被发送到计算集群各个Worker上。 MaxCompute 2.0执行引擎的Code Generation模块Load查询计划,并利用LLVM C++ API生成相应的机器码。Code Generation模块返回一个函数指针作为调用的入口。 Worker通过调用Code Generation模块返回的函数指针以完成计算逻辑。 与MaxCompute 1.0相比,MaxCompute 2.0中Code Generation速度有明显提升。在1.0中,一个SQL的平均Code Generation耗时大概在2-3s左右,这个时间在2.0中被缩短到100 - 200ms。因为在2.0中Code Generation都在计算集群的Worker上完成,因此相对来说减轻了控制集群的压力,有助于MaxCompute控制集群的稳定性。此外,因为MaxCompute 2.0的执行引擎是复用的(不因为SQL不同而不一样),因此无需像1.0中一样,在控制集群与计算集群之间传输动态库,降低了控制集群与计算机群之间的网络负载。
后续工作
塑云科技:性能突破,基于KafKa+OTS+MaxCompute 完成了一次物联网系统技术重构 创业团队,专注于氢能燃料电池生态链的运营支撑,当前主要的业务组成为新能源车整车实时运营监控分析,加氢站实时运营监控分析,车辆安全运营支撑。
云数据仓库MaxCompute最佳实践之数据上云 | 2019飞天大数据平台技术公开课第五季 秋日杲杲,大数据技术公开课第五季开播!本季主题 “云数据仓库 MaxCompute 最佳实践之数据上云”。10.22日-11.12日,每周二 19:00,一起学习大数据。
MaxCompute技术人背后的故事:从ApacheORC到AliORC | 7月25号云栖夜读 今天的首篇文章,讲述了:2019大数据技术公开课第一季《技术人生专访》来袭,本季将带领开发者们探讨大数据技术,分享不同国家的工作体验。本文整理自阿里巴巴计算平台事业部高级技术专家吴刚的专访,将为大家介绍Apache ORC开源项目、主流的开源列存格式ORC和Parquet的区别以及MaxCompute选择ORC的原因。
海胜专访--MaxCompute 与大数据查询引擎的技术和故事 在2019大数据技术公开课第一季《技术人生专访》中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了《MaxCompute 与大数据查询引擎的技术和故事》,主要介绍了MaxCompute与MPP Database的异同点,分布式系统上Join的实现,且详细讲解了MaxCompute针对Join和聚合引入的Hash Clustering Table和Range Clustering Table的优化。
春蔚专访--MaxCompute 与 Calcite 的技术和故事 2019大数据技术公开课第一季《技术人生专访》,来自阿里云计算平台事业部高级开发工程师雷春蔚向大家讲述了MaxCompute 与 Calcite 的技术和故事。 具体内容包括: 1) 什么是查询优化器;2)MaxCompute查询优化器的具体实践;3)MaxCompute后续计划;4)从校招到阿里巴巴工程师到Calcite committer,他经历了怎样的个人成长。
吴刚专访--大数据和 MaxCompute 技术和故事 2019大数据技术公开课第一季《技术人生专访》来袭,本季将带领开发者们探讨大数据技术,分享不同国家的工作体验。本文整理自阿里巴巴计算平台事业部高级技术专家吴刚的专访,将为大家介绍Apache ORC开源项目、主流的开源列存格式ORC和Parquet的区别以及MaxCompute选择ORC的原因。
MaxCompute技术人背后的故事:从ApacheORC到AliORC 2019大数据技术公开课第一季《技术人生专访》来袭,本季将带领开发者们探讨大数据技术,分享不同国家的工作体验。本文整理自阿里巴巴计算平台事业部高级技术吴刚的专访,将为大家介绍Apache ORC开源项目、主流的开源列存格式ORC和Parquet的区别以及MaxCompute选择ORC的原因。
【内含分享PPT/视频/文章】阿里云MVP学院MaxCompute技术闭门会线上首播 | 2019大数据技术公开课第二季 数据的价值是解释业务还是预测业务?是支撑业务还是驱动业务?企业级计算服务的核心问题是什么?企业级计算平台要解决的核心问题是什么?商业和技术的平衡点在哪里? 一起直播学习,让数据真正驱动业务。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
隐林 阿里云大数据产品专家,擅长MaxCompute、机器学习、分布式、可视化、人工智能等大数据领域;
前言 在《数据库系统中的Code Generation技术介绍》中,我们简单介绍了一下Code Generation技术及其在大规模OLAP系统,特别是大规模分布式OLAP系统中的重要性。MaxCompute采用了Code Generation技术来提高计算效率。在MaxCompute2.0中,我们又引入了基于LLVM的JIT(Just In Time) Code Generation技术。结合向量化的执行引擎,基于SIMD技术的执行效率优化等方式,较之MaxCompute 1.0,MaxCompute 2.0在性能方便有了较大的提升,具体可以参照《MaxCompute2.0性能评测:更强大、更高效之上的更快速》。
MaxCompute 1.0中的Code Generation
如上图,MaxCompute 1.0采用了静态的Code Generation技术,工作主要在MaxCompute控制集群中名为“Executor”的角色上完成。其流程如下:用户的SQL语句在Executor上经过Parsing和Optimization之后,生成对应的查询计划。 Executor上的Code Generation模块将查询计划翻译成一个名为“mapred.cpp”的C++源文件。如上图所示,查询计划中的每一个Task(就是MaxCompute作业中的一个Stage)会被翻译成C++中的一个Class, 而所有的处理逻辑被生成到该Class的Process()方法当中。 Executor调用g++将“mapred.cpp”编译成一个动态库,并将其下发到计算集群中的每一个Worker上。 被调度起来的Worker会Load该动态库,调用相应的Process()方法以完成计算逻辑。 可以看到,利用Code Generation技术,对于每一个SQL来说执行时代码都是经过定制的,因此执行效率较传统的Volcano Model更好。但是,其中也有一些问题。
g++ 编译还是比较消耗CPU/内存的,特别是当优化选项开到O2以上的时候。特别是用户SQL比较复杂的情况下(有些SQL在SELECT语句中有多达上千个表达式,或者表达式的嵌套计算特别深入),生成的C++源文件也比较大,编译更加耗时。在实际生产中,我们见过编译耗时数十秒,消耗上G内存的情况。 生成的动态库在控制集群和计算集群之间传输也会有带来一定的网络开销。因为这个动态库的与SQL逻辑紧密相关的,因此无法复用,因此每个SQL都会经历编译,下发的过程,在任务提交比较频繁的情况下,控制集群的稳定性会收到一定挑战。 因为较高的编译时开销,这种Code Generation的方式在处理复杂的语句加中小数据规模查询的场景,比如service mode下,overhead太大。 MaxCompute 2.0中的Code Generation
MaxCompute 2.0采用了基于LLVM的JIT Code Generation技术。所谓JIT,就是程序在运行期间根据需要动态生成相应的机器指令。这样,整个Code Generation的工作由控制集群移交到了真正执行计算逻辑的计算集群各个Worker上。其流程如下:
和MaxCompute 1.0中一样,用户的SQL语句在Executor上经过Parsing和Optimization之后,生成对应的查询计划。 查询计划直接被发送到计算集群各个Worker上。 MaxCompute 2.0执行引擎的Code Generation模块Load查询计划,并利用LLVM C++ API生成相应的机器码。Code Generation模块返回一个函数指针作为调用的入口。 Worker通过调用Code Generation模块返回的函数指针以完成计算逻辑。 与MaxCompute 1.0相比,MaxCompute 2.0中Code Generation速度有明显提升。在1.0中,一个SQL的平均Code Generation耗时大概在2-3s左右,这个时间在2.0中被缩短到100 - 200ms。因为在2.0中Code Generation都在计算集群的Worker上完成,因此相对来说减轻了控制集群的压力,有助于MaxCompute控制集群的稳定性。此外,因为MaxCompute 2.0的执行引擎是复用的(不因为SQL不同而不一样),因此无需像1.0中一样,在控制集群与计算集群之间传输动态库,降低了控制集群与计算机群之间的网络负载。
后续工作
目前,MaxCompute 2.0 的执行引擎还是以Volcano Model为基础。只是在Volcano Model中各个算子之间以Batch模式传递数据,并且以列式执行的方式提高执行速度。基于LLVM的JIT Code Generation现在主要用在表达式计算,Streamline等热点部分。之后,我们准备尝试Full Stage的Code Generation, 类似http://www.hyper-db.com/。 有兴趣的同学可以看看这个:http://www.vldb.org/pvldb/vol4/p539-neumann.pdf。 附件中的PDF结合了《数据库系统中的Code Generation技术介绍》和本文的部分内容,有兴趣的同学可以作为参考。
欢迎加入“数加·MaxCompute购买咨询”钉钉群(群号: 11782920)进行咨询,群二维码如下:
塑云科技:性能突破,基于KafKa+OTS+MaxCompute 完成了一次物联网系统技术重构 创业团队,专注于氢能燃料电池生态链的运营支撑,当前主要的业务组成为新能源车整车实时运营监控分析,加氢站实时运营监控分析,车辆安全运营支撑。
云数据仓库MaxCompute最佳实践之数据上云 | 2019飞天大数据平台技术公开课第五季 秋日杲杲,大数据技术公开课第五季开播!本季主题 “云数据仓库 MaxCompute 最佳实践之数据上云”。10.22日-11.12日,每周二 19:00,一起学习大数据。
MaxCompute技术人背后的故事:从ApacheORC到AliORC | 7月25号云栖夜读 今天的首篇文章,讲述了:2019大数据技术公开课第一季《技术人生专访》来袭,本季将带领开发者们探讨大数据技术,分享不同国家的工作体验。本文整理自阿里巴巴计算平台事业部高级技术专家吴刚的专访,将为大家介绍Apache ORC开源项目、主流的开源列存格式ORC和Parquet的区别以及MaxCompute选择ORC的原因。
海胜专访--MaxCompute 与大数据查询引擎的技术和故事 在2019大数据技术公开课第一季《技术人生专访》中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了《MaxCompute 与大数据查询引擎的技术和故事》,主要介绍了MaxCompute与MPP Database的异同点,分布式系统上Join的实现,且详细讲解了MaxCompute针对Join和聚合引入的Hash Clustering Table和Range Clustering Table的优化。
春蔚专访--MaxCompute 与 Calcite 的技术和故事 2019大数据技术公开课第一季《技术人生专访》,来自阿里云计算平台事业部高级开发工程师雷春蔚向大家讲述了MaxCompute 与 Calcite 的技术和故事。 具体内容包括: 1) 什么是查询优化器;2)MaxCompute查询优化器的具体实践;3)MaxCompute后续计划;4)从校招到阿里巴巴工程师到Calcite committer,他经历了怎样的个人成长。
吴刚专访--大数据和 MaxCompute 技术和故事 2019大数据技术公开课第一季《技术人生专访》来袭,本季将带领开发者们探讨大数据技术,分享不同国家的工作体验。本文整理自阿里巴巴计算平台事业部高级技术专家吴刚的专访,将为大家介绍Apache ORC开源项目、主流的开源列存格式ORC和Parquet的区别以及MaxCompute选择ORC的原因。
MaxCompute技术人背后的故事:从ApacheORC到AliORC 2019大数据技术公开课第一季《技术人生专访》来袭,本季将带领开发者们探讨大数据技术,分享不同国家的工作体验。本文整理自阿里巴巴计算平台事业部高级技术吴刚的专访,将为大家介绍Apache ORC开源项目、主流的开源列存格式ORC和Parquet的区别以及MaxCompute选择ORC的原因。
【内含分享PPT/视频/文章】阿里云MVP学院MaxCompute技术闭门会线上首播 | 2019大数据技术公开课第二季 数据的价值是解释业务还是预测业务?是支撑业务还是驱动业务?企业级计算服务的核心问题是什么?企业级计算平台要解决的核心问题是什么?商业和技术的平衡点在哪里? 一起直播学习,让数据真正驱动业务。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
隐林 阿里云大数据产品专家,擅长MaxCompute、机器学习、分布式、可视化、人工智能等大数据领域;
相关文章
- 【华为云技术分享】云原生数据库三驾马车之TaurusDB
- 【技术贴】xp下改变7zip默认关联图标和美化教程
- [Tools] Scroll, Zoom, and Highlight code in a mdx-deck slide presentation with Code Surfer <🏄/>
- 【云栖大会】软件供应链革命:容器技术
- 【云栖大会】用技术驱动企业提效
- QoS队列调度技术详解
- 从技术雷达看持续交付
- 如何让 Visual Studio Code 里显示 Cypress 的 intelligent code suggestion
- Paip.论语义分析与语义搜索技术.attilax(艾龙)总结
- 余额宝技术架构及演进
- XAI之GS:全局代理(Global Surrogate,对黑盒机器学习执行模型可解释性的技术)的简介、常用工具包、案例应用之详细攻略
- 视频编解码及H264技术
- 技术解码 | WebRTC 发送方码率预估实现解析
- MongoDB 谨防索引seek的效率问题【华为云技术分享】
- NB-IoT技术
- SpringBoot整合SpringMVC、持久层技术MyBatis、连接mysql数据库技术
- 004-搭建框架-实现AOP机制【一】代理技术
- 技术分享 | Jenkins job 机制该如何使用?
- WMI后门技术的攻击与检测
- 一文吃透 VS Code+Git 操作(vs code中git的相关配置与使用)
- 【CSDN首发】2021最新《Android Framework开发详解》腾讯技术团队出品,限时分享
- 【YOLOv7/v5系列算法改进NO.45】首发最新特征融合技术RepGFPN(DAMO-YOLO)