
数加平台如何通过Serverless 架构实现普惠大数据
阿里云大数据 Serverless 理念
Serverless是一种架构理念,指的是以服务的形式来提供计算能力而不是以服务器形式,让开发者在构建应用的过程中不用过多考虑基础设施的问题。大数据业务本来就是最典型的计算业务,从计算的场景上来说,涵盖了离线批量计算、实时流计算、在线实时计算等,在很多情况下还需要把这些计算能力组合起来才能满足需求。所以Serverless 的架构天生就能很好的适用于大数据应用的场景,能把数据科学家从底层服务器层的运维管理等解放出来,让数据科学家专注在数据价值的探索挖掘上。
当前大数据云服务商里面只有Google 跟阿里云可以给用户提供完整的大数据Serverless 服务。Google 和阿里巴巴本身都是真正的大数据公司,对大数据的应用代表了行业领先的水平,今天在大数据云服务的提供上都一致的选择Serverless 的架构,也能很好的代表Serverless 架构在大数据应用领域的先进性。
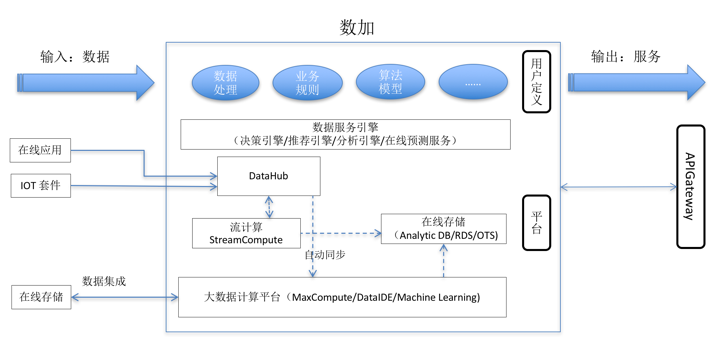
以阿里云最重要的大数据产品MaxCompute 为例,无论是计算还是存储能力都是以服务的形式对外提供的,是典型的Serverless 服务。事实上,阿里云从一开始就坚持要把计算能力做成像水电煤一样的公共服务,而不是卖服务器给客户,这跟当下流行的Serverless 架构理念是一致的。这个理念在数加平台得到了很好的体现,数加平台能工一站式提供完整的大数据能力,离线,在线处理,大规模机器学习等,但没有一个服务以服务器形式提供的。
在更高层面的抽象,阿里云大数据平台今天已经可以提供很多业务场景化的计算服务,比如推荐引擎,规则引擎,以及各种人工智能的服务,甚至可以把数据和计算融合起来提供服务,典型的场景如下:
数据分析服务化:按需组合使用各类Serverless 的服务,将多种数据源集成,清洗转换,关联分析,并以可视化的方式展现数据的洞察。过程中不用关心任何的物理架构,也不用关心各种工具的集成。
数据服务化:指将已有的数据通过Serverless的方式(如API化)提供给使用者,常见的有:气象数据获取,根据地理位置获取对应位置的地点信息,图像识别(指能识别出特定的图片信息),特征新闻抓取服务等。
算法服务化:主要是将输入的数据根据特定的算法进行提炼和运算,然后将结果输出,如人脸特征值提取,基因计算,图像渲染等。开发者无需考虑计算资源,只需将计算代码托管到大数据平台或者通过API接口调用大数据计算服务,由服务商提供计算资源的调度,监控和维护工作,能极大的降低运维工作量,同时具有更好的资源弹性伸缩能力。
技术体系复杂,不存在一个通用的引擎可以解决所有大数据的场景,离线处理,流式处理,在线分析都需要使用不同的引擎来支持
这些特点使得Serverless 的架构对大数据应用尤为重要,如果数据科学家陷入到这么复杂的底层构建和运维的细节,效率会变得非常低,甚至会导致很多的想法无法落地。
数加平台从用户视角来看,输入的是数据,输出的是智慧的服务。数加平台从底层将整个数据应用的链条全部打通,并提供了一系列的Serverless 服务,从数据采集,存储,各种处理,到最终变成数据服务。用户需要做的是开发、配置业务相关的处理逻辑、业务规则和算法等,把所有精力关注在数据价值的实现上,而不用关心底层技术和运维层面的架构,也不用关心系统资源管理等。
案例1:智慧水务
整体架构如下图:
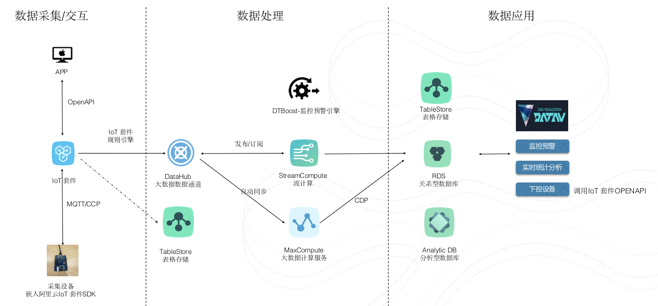
利用IoT 套件采集设备数据,通过简单的配置即可将数据实时对接到大数据平台的DataHub.驱动以下典型的计算场景,
1) 在流计算中自定义SQL 对这些数据做实时的汇总统计,比如流量的统计
2) 在规则引擎中配置业务规则,通过这些规则对数据进行实时分析,判断设备的状态
3) 在规则引擎中配置异常检测的算法对设备状态进行预测,或者利用时间序列算法对管网运行状态进行预测,底层会应用到Maxcompute 对历史数据进行分析,产出的模型对接到StreamCompute,进而对新产生的数据进行实时预测
这个案例里面,利用到了大量的大数据的能力,离线存储和计算,流式计算,机器学习模型训练,数据可视化等等,但对使用者来说,需要做的是流计算SQL 的开发,业务规则的配置,以及偏业务的算法参数配置。而不用去管底层的平台要如何搭建,不同引擎之间的数据如何流转,以及系统的扩展性,稳定性,更不用关心要准备多少的物理资源。
案例2:智能服务机器人
将跟机器人交互的语音数据实时上传到大数据平台,驱动语音识别引擎对交互的内容进行识别,自然语言处理,构建知识库,最终形成一个问答系统。随着数据的积累,问答系统会变得越来越智能。
在这个案例里面,用户只需要将语音数据接入,输出的就是一个智能问答系统,完全不用关心底层的实现,而这个实现是非常复杂的,有能力的用户都需要花很大的成本才能搭建起来。
案例3:参考小红唇 https://yq.aliyun.com/articles/57256
这个案例组合使用数加的各种服务,快速的获得了大数据BI 的能力,所有的投入都是在数据业务价值的发现上,而没有花精力在技术平台的构建上。
上面这些案例都很好的展示了Serverless 架构对于大数据应用的价值:把用户从底层的部署,运维,以及资源管理的复杂性中解放出来,让所有的精力都可以投入在数据业务价值的探索和实现上。并且,利用数加平台,可以大大的提升数据应用的效率,传统的模式要数以月计才能完成的事情,使用Serverless 服务,几天就能完成,甚至可以更快,时效对于数据价值的最大化是至关重要的。
阿里云数加平台简介
阿里云数加平台是阿里云为企业大数据实施提供的一套完整的一站式大数据解决方案,主要基于大数据基础服务提供用户大数据存储和计算能力。开发者使用数加可以轻松进行各种数据采集、数据加工、BI商业智能、人工智能和数据创新等操作。阿里云数加平台作为大数据Serverless的典范,助力企业在DT时代更敏捷、更智能、更具洞察力。
透过数加平台的数据市场相关API,开发者可以通过几行代码调用数据市场中由第三方提供商开发的各种数据服务(如获取各种交通数据、气象数据、海洋数据、水利数据等),方便快捷的获取各种数据,缩短开发时间,降低开发难度。通过数据市场的各种数据原料、数据API,数据越用越有价值,数据越关联越有价值。用户可以按需以服务的方式调用所需的第三方数据,并结合自有数据实现大数据分析和应用,以得到数据价值的最大化。数据服务化是数加平台的典型特点。
在数加平台,各种计算服务开箱即用,用户不必关心大数据集群的搭建、配置和运维工作,仅需简单的几步操作,用户就可以在数加平台中上传数据、分析数据并得到分析结果。用户不必关心数据规模增长带来的存储困难、运算时间延长等烦恼,数加平台根据用户的数据规模自动扩展大数据集群的存储和计算能力,使用户专心于数据分析和挖掘,最大化发挥数据的价值。
23、一文读懂 Spring Boot、微服务架构和大数据治理三者之间的故事(十五) 微服务的诞生并非偶然,它是在互联网高速发展,技术日新月异的变化以及传统架构无法适应快速变化等多重因素的推动下诞生的产物。互联网时代的产品通常有两类特点:需求变化快和用户群体庞大,在这种情况下,如何从系统架构的角度出发,构建灵活、易扩展的系统,快速应对需求的变化呢?同时随着用户的增加,如何保证系统的可伸缩性、高可用性,成为系统架构面临的挑战。
X86 vs ARM 架构同台竞技: 生物大数据大规模并行计算(如何将WGS全基因组计算成本降到1美元) Sentieon DNAseq 实施的全基因组测序 (WGS) 二级分析流程与行业标准的 BWA-GATK 最佳实践流程结果相匹配,且运行速度提高了 5-20 倍。 Sentieon软件安装简单,开箱即用,并且提供了与ARM和x86指令集适配的版本。使30X WGS 数据样本在OCI 实例上的计算成本压缩到每个样本 1 美元以下,处理时间缩短到近一小时。
大数据繁荣生态圈组件之实时大数据Druid小传(二)Druid架构与原理 索引服务是数据摄入创建和销毁Segment的重要方式,Druid提供一组支持索引服务(Indexing Service)的组件,即Overlord和MiddleManager节点。
谈谈数据治理成熟度模型及大数据治理参考架构 数据是企业拥有的最大资产之一,但是数据也越来越难以管理和控制。干净、可信的数据能够为企业提供更好的服务,提高客户忠诚度,提高生产效率,提高决策能力。
阿里巴巴内部:2022年全技术栈PPT分享(架构篇+算法篇+大数据) 我只截图不说话,PPT大全,氛围研发篇、算法篇、大数据、Java后端架构!除了大家熟悉的交易、支付场景外,支撑起阿里双十一交易1682亿元的“超级工程”其实包括以下但不限于客服、搜索、推荐、广告、库存、物流、云计算等。 Java核心技术栈:覆盖了JVM、锁、并发、Java反射、Spring原理、微服务、Zookeeper、数据库、数据结构等大量知识点。 大数据:Spark、Hadoop
从传统的架构到云上大数据 在云计算走向成熟之前,我们更应该关注系统云计算架构的细节,从传统的架构到云上大数据,实现了很多的转变。
给 K8s 装上大数据调度引擎:伏羲架构升级 K8s 统一调度 飞天伏羲作为有着十多年历史的调度团队,在服务好 MaxCompute 大数据平台的过程中,一直在不断通过自我革新赶超业界先进水平,我们经历了 Fuxi 2.0 的这样的大规模升级,今天通过 K8s 统一调度项目又再次实现了系统架构的蜕变,将大数据平台强大的调度能力赋予 K8s 系统,同时去拥抱 K8s 周边丰富的生态。除了集团弹内集群,将来我们在公共云、专有云等多个场景,也会以 K8s 统一调度的方式进行输出,以更好地服务云上的用户,敬请期待!
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
相关文章
- Android 图形架构
- 亿级流量架构之服务器扩容思路及问题分析
- 基于开源方案构建统一的文件在线预览与office协同编辑平台的架构与实现历程
- 主数据管理平台产品功能组成架构
- 架构:第七章:基于Dubbo+Zookeeper项目架构
- 搭建spring cloud框架并且配置权限架构
- ARM 架构简介_芯片arm架构
- MVC架构模式与三层架构的关系
- 集群日志收集架构ELK
- 【Linux 内核】Linux 内核体系架构 ( 硬件层面 | 内核空间 | 用户空间 | 内核态与用户态切换 | 系统调用 | 体系结构抽象层 )
- 计费平台部高一致性存储层架构变迁之路
- 如何用一套底层低代码架构支撑近百个低代码平台 | GMTC
- 某互联网公司广告平台技术架构详解架构师
- 织架构重塑Linux架构:全新组织模式(linux改组)
- 架构一个适用于Linux的Wiki系统(linux搭建wiki)
- 基于MongoDB的高并发高可用政府云平台架构实践
- 初谈架构
- 微众万向矩阵元联合开源底层架构BCOS平台,入局联盟链三国杀
- bc跨服架构搭建Mysql数据库的实践(bc跨服mysql搭建)
- 建立稳健的数据架构,Redis为首选(数据架构redis)
- 分布式架构Redis集群实现无感知分布式架构技术研究(redis集群无感知)
- 全面解析腾讯云金融业务支撑平台,四位一体聚焦底层架构自主可控
- 技术干货|如何在微服务架构下构建高效的运维管理平台?