
HTTP协议header中Content-Disposition中文文件名乱码
2023-09-14 08:59:44 时间
在做文件下载时当文件名为中文时经常会出现乱码现象。
参考文章 http://blog.robotshell.org/2012/deal-with-http-header-encoding-for-file-download/
本文就详细给出案例来解决这一乱码问题以及还一直未解决的一个疑问欢迎大家一起来探讨。
大体的原因就是header中只支持ASCII所以我们传输的文件名必须是ASCII当文件名为中文时必须要将该中文转换成ASCII。
转换方式有很多
方式一将中文文件名用ISO-8859-1进行重新编码如headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("UTF-8"),"ISO-8859-1")+".txt");
方式二可以对中文文件名使用url编码如headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt");
疑问中文文件名转换成ASCII后传给浏览器浏览器遇到一堆ASCII如何能正确的还原出来我们原来的中文文件名的呢
实验案例
乱码现象如下
?
这里的filename直接使用中文文件然后就造成了下面的乱码现象
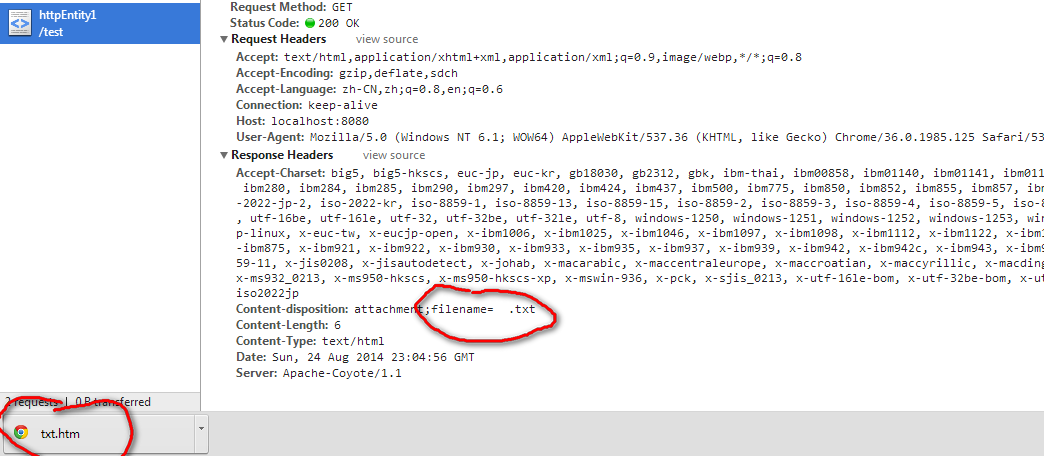
文件名后缀也完全变了。
原因就是header只支持ASCII所以我们要把"中国"转换成ASCII。
解决方案一将中文文件名用ISO-8859-1进行重新编码
?
headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("UTF-8"),"ISO-8859-1")+".txt");
chrome为
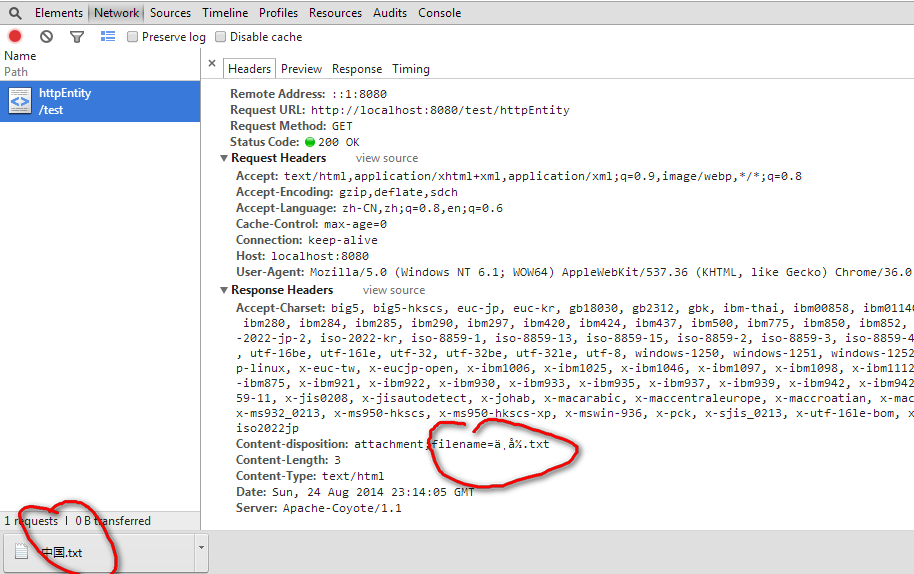
IE11为

chrome解决了乱码现象但IE没有。但是你是否想过浏览器面对一堆Content-disposition:attachment;filename=ä¸å½.txt它又是如何来正确显示的中文文件名"中国.txt"的呢它肯定要对ä¸å½重新进行UTF-8编码才能正确显示出"中国"即必须进行类似如下的操作new String("ä¸å½".getBytes("ISO-8859-1"),"UTF-8")才能正常显示出"中国.txt"。而IE11进行的类似操作为new String("ä¸å½".getBytes("ISO-8859-1"),"GBK")。
同样的实验只是把UTF-8改成GBK
?
headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("GBK"),"ISO-8859-1")+".txt");
chrome为
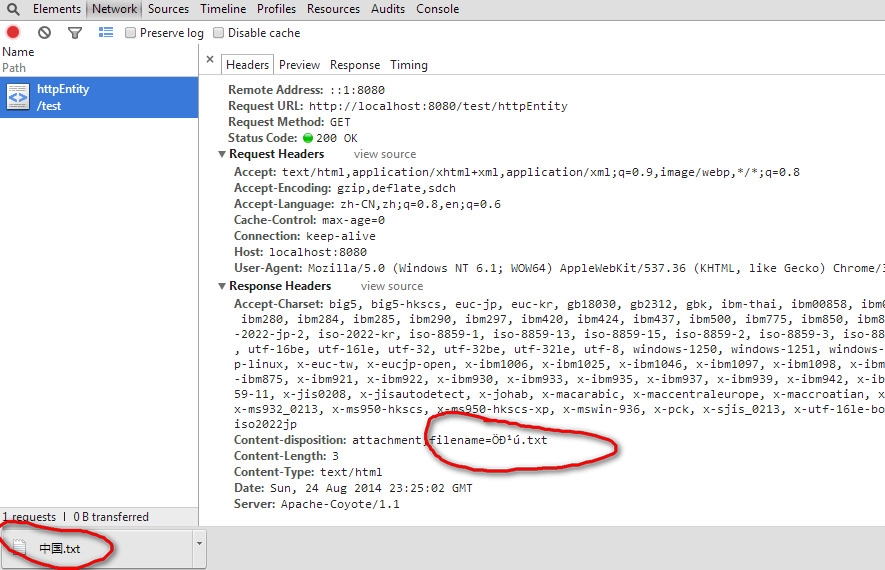
IE11为

IE11和chrmoe都能正确显示面对Content-disposition:attachment;filename=Öйú.txt浏览器也必须进行如下类似的操作才能正确还原出"中国"new String("Öйú".getBytes("ISO-8859-1"),"GBK")。
这里就可以提出我们的疑问了浏览器面对ä¸å½、Öйú都能正确还原出"中国"选择UTF-8还是GBK它到底是怎么做到的呢依据又是什么呢难道它是要计算出概率这便是我的疑问还请大家一起探讨和研究。
接下来说说其他的解决方案
解决方案二可以对中文文件名使用url编码
?
headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt");
headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","GBK")+".txt");
chrome为
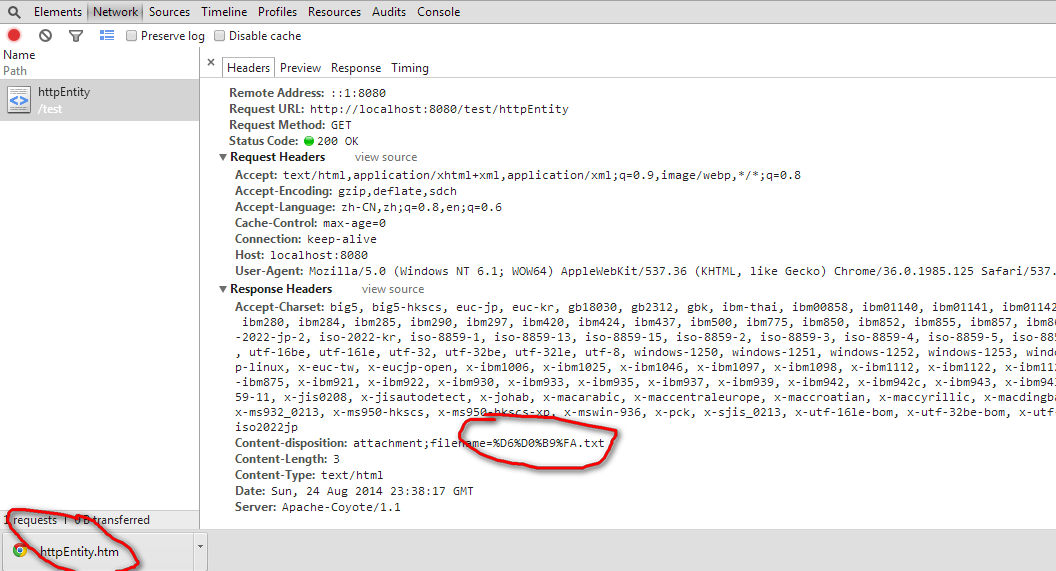
文件名也全变了。
IE11为

这里就是说对于URL编码支持UTF-8其他的好像还不支持。
解决方案三
使用最新的解决方案即filename*=charsetlangvalue。charset则是给浏览器指明以什么编码方式来还原中文文件名。
如filename*=UTF-8value其中value为原始数据的UTF-8形式的URL编码。
如下
?
HttpHeaders headers=new HttpHeaders();//filename="+URLEncoder.encode("中国","UTF-8")+";
headers.add("Content-Disposition","attachment;filename*=UTF-8"+URLEncoder.encode("中国","UTF-8")+".txt");
chrome为
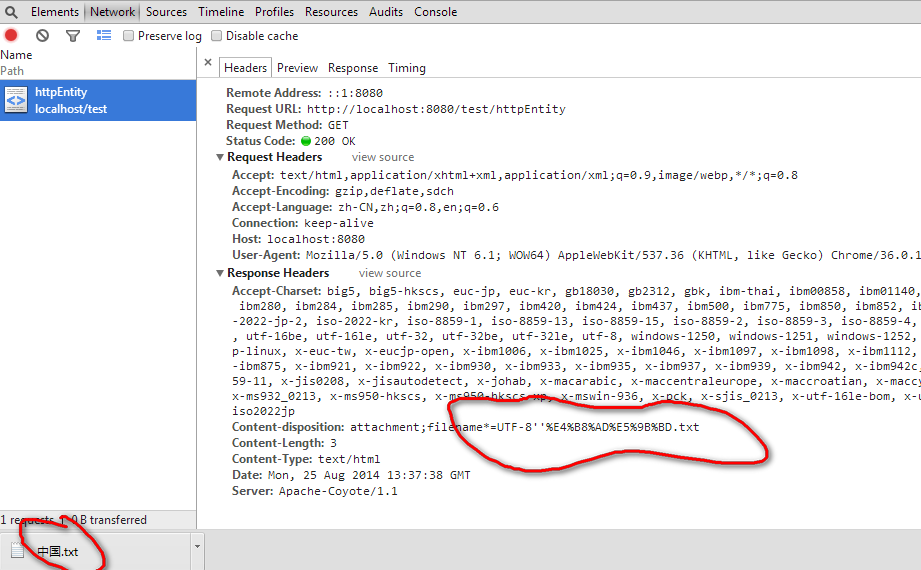
IE11为

都能够正确显示。
若使用headers.add("Content-Disposition","attachment;filename*=GBK"+URLEncoder.encode("中国","UTF-8")+".txt"),对此chrome则是按照GBK方式来还原中文文件名的所以就会变成
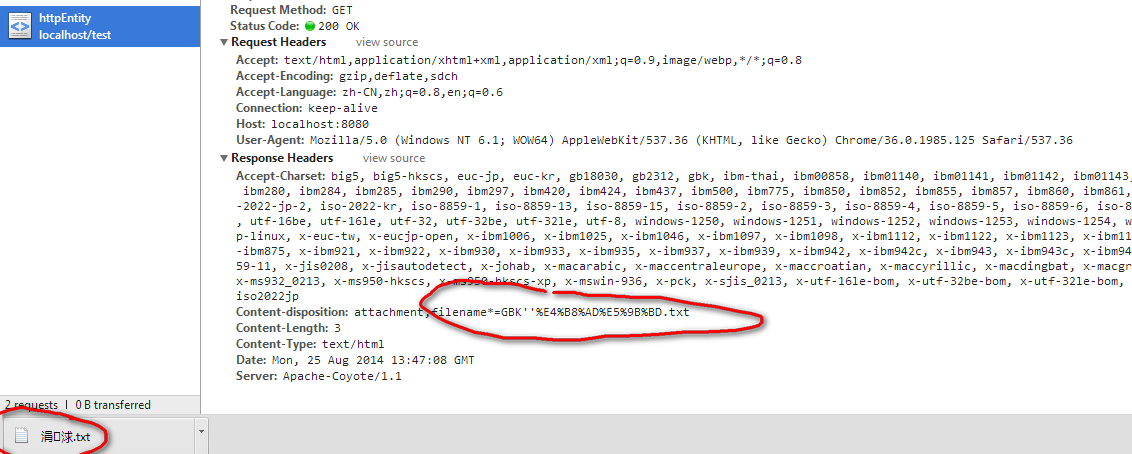
造成乱码。而IE11则直接是

若使用headers.add("Content-disposition","attachment;filename*=GBK"+URLEncoder.encode("中国","GBK")+".txt")
chrome为
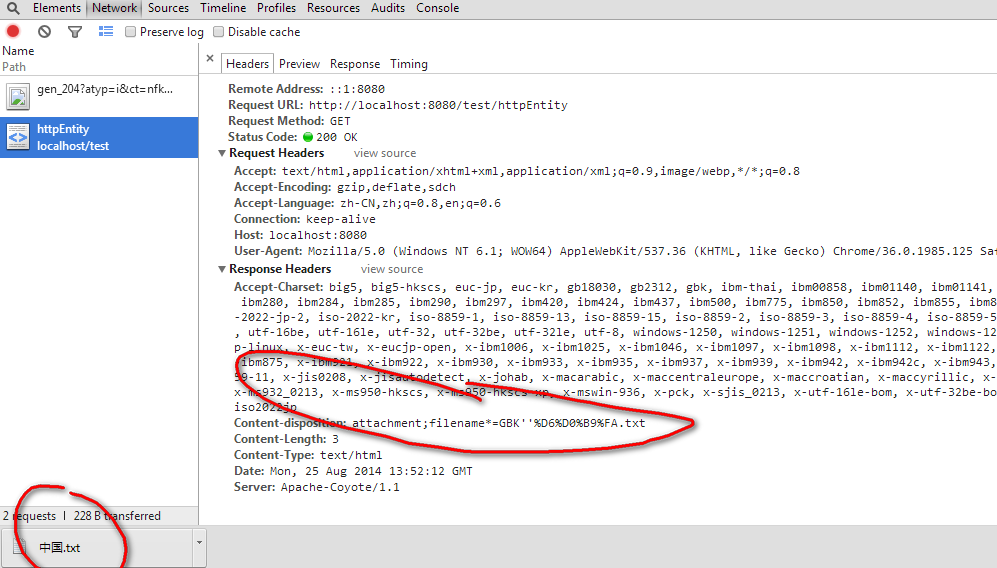
IE11为

即IE11仅支持filename*=UTF-8编码形式的。
然后就是headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt;filename*=UTF-8"+URLEncoder.encode("中国","UTF-8")+".txt");filename和filename*可以组合使用来解决跨浏览器的问题。
对于上面提出的疑问还请网友们解答。
【Node.js】HTTP协议、HTTP的请求报文和响应报文 HTTP 全称为超文本传输协议,是用于从WWW服务器传输超文本到本地浏览器的传送协议,基于TCP的连接方式,它可以使浏览器更加高效,使网络传输减少。
参考文章 http://blog.robotshell.org/2012/deal-with-http-header-encoding-for-file-download/
本文就详细给出案例来解决这一乱码问题以及还一直未解决的一个疑问欢迎大家一起来探讨。
大体的原因就是header中只支持ASCII所以我们传输的文件名必须是ASCII当文件名为中文时必须要将该中文转换成ASCII。
转换方式有很多
方式一将中文文件名用ISO-8859-1进行重新编码如headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("UTF-8"),"ISO-8859-1")+".txt");
方式二可以对中文文件名使用url编码如headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt");
疑问中文文件名转换成ASCII后传给浏览器浏览器遇到一堆ASCII如何能正确的还原出来我们原来的中文文件名的呢
实验案例
乱码现象如下
?
这里的filename直接使用中文文件然后就造成了下面的乱码现象
文件名后缀也完全变了。
原因就是header只支持ASCII所以我们要把"中国"转换成ASCII。
解决方案一将中文文件名用ISO-8859-1进行重新编码
?
headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("UTF-8"),"ISO-8859-1")+".txt");
chrome为
IE11为
chrome解决了乱码现象但IE没有。但是你是否想过浏览器面对一堆Content-disposition:attachment;filename=ä¸å½.txt它又是如何来正确显示的中文文件名"中国.txt"的呢它肯定要对ä¸å½重新进行UTF-8编码才能正确显示出"中国"即必须进行类似如下的操作new String("ä¸å½".getBytes("ISO-8859-1"),"UTF-8")才能正常显示出"中国.txt"。而IE11进行的类似操作为new String("ä¸å½".getBytes("ISO-8859-1"),"GBK")。
同样的实验只是把UTF-8改成GBK
?
headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("GBK"),"ISO-8859-1")+".txt");
chrome为
IE11为
IE11和chrmoe都能正确显示面对Content-disposition:attachment;filename=Öйú.txt浏览器也必须进行如下类似的操作才能正确还原出"中国"new String("Öйú".getBytes("ISO-8859-1"),"GBK")。
这里就可以提出我们的疑问了浏览器面对ä¸å½、Öйú都能正确还原出"中国"选择UTF-8还是GBK它到底是怎么做到的呢依据又是什么呢难道它是要计算出概率这便是我的疑问还请大家一起探讨和研究。
接下来说说其他的解决方案
解决方案二可以对中文文件名使用url编码
?
headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt");
headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","GBK")+".txt");
chrome为
文件名也全变了。
IE11为
这里就是说对于URL编码支持UTF-8其他的好像还不支持。
解决方案三
使用最新的解决方案即filename*=charsetlangvalue。charset则是给浏览器指明以什么编码方式来还原中文文件名。
如filename*=UTF-8value其中value为原始数据的UTF-8形式的URL编码。
如下
?
HttpHeaders headers=new HttpHeaders();//filename="+URLEncoder.encode("中国","UTF-8")+";
headers.add("Content-Disposition","attachment;filename*=UTF-8"+URLEncoder.encode("中国","UTF-8")+".txt");
chrome为
IE11为
都能够正确显示。
若使用headers.add("Content-Disposition","attachment;filename*=GBK"+URLEncoder.encode("中国","UTF-8")+".txt"),对此chrome则是按照GBK方式来还原中文文件名的所以就会变成
造成乱码。而IE11则直接是
若使用headers.add("Content-disposition","attachment;filename*=GBK"+URLEncoder.encode("中国","GBK")+".txt")
chrome为
IE11为
即IE11仅支持filename*=UTF-8编码形式的。
然后就是headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt;filename*=UTF-8"+URLEncoder.encode("中国","UTF-8")+".txt");filename和filename*可以组合使用来解决跨浏览器的问题。
对于上面提出的疑问还请网友们解答。
【Node.js】HTTP协议、HTTP的请求报文和响应报文 HTTP 全称为超文本传输协议,是用于从WWW服务器传输超文本到本地浏览器的传送协议,基于TCP的连接方式,它可以使浏览器更加高效,使网络传输减少。
相关文章
- HTTP could not register URL http://+:8000/testservice/. Your...
- HTTP Status 500 - The absolute uri: http://java.sun.com/jsp/jstl/core cannot be resolved in either web.xml or the jar files deployed with this application
- npm的package.json中文文档
- Nodejs Express 4.X 中文API 4--- Router篇
- Cocos2d-x初入学堂(17)-->打包成APK中文显示乱码
- spring boot: 用pinyin4j把中文转换为汉语拼音(spring boot v2.5.4)
- PhpExcel中文帮助手册|PhpExcel使用方法
- 使用 http-proxy 代理 SAP UI5 应用发起的 HTTP 请求
- App Transport Security has blocked a cleartext HTTP (http://) resource load since it is insecure. Te
- HTTP隧道ABPTTS——加密型的http隧道,todo自己搭建一个玩玩
- 【zabbix】解决zabbix在web页面显示中文乱码问题