
Spark SQL性能优化
2023-09-14 08:59:49 时间
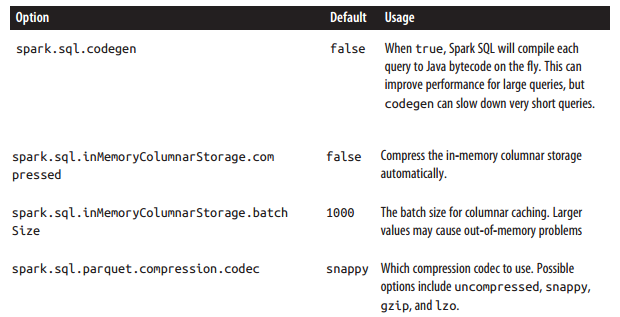
针对Spark SQL 性能调优参数如下:
import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.sql.api.java.JavaSQLContext; import org.apache.spark.sql.api.java.Row; import org.apache.spark.sql.hive.api.java.JavaHiveContext;Beeline 命令行设置优化参数
public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("simpledemo").setMaster("local"); conf.set("spark.sql.codegen", "false"); conf.set("spark.sql.inMemoryColumnarStorage.compressed", "false"); conf.set("spark.sql.inMemoryColumnarStorage.batchSize", "1000"); conf.set("spark.sql.parquet.compression.codec", "snappy"); JavaSparkContext sc = new JavaSparkContext(conf); JavaSQLContext sqlCtx = new JavaSQLContext(sc); JavaHiveContext hiveCtx = new JavaHiveContext(sc); List Row result = hiveCtx.sql("SELECT foo,bar,name from pokes2 limit 10").collect(); for (Row row : result) { System.out.println(row.getString(0) + "," + row.getString(1) + "," + row.getString(2)); } } }
beeline set spark.sql.codegen=true; SET spark.sql.codegen=true spark.sql.codegen=true Time taken: 1.196 seconds重要参数说明
spark.sql.codegen Spark SQL在每次执行次,先把SQL查询编译JAVA字节码。针对执行时间长的SQL查询或频繁执行的SQL查询,此配置能加快查询速度,因为它产生特殊的字节码去执行。但是针对很短(1 - 2秒)的临时查询,这可能增加开销,因为它必须先编译每一个查询。
spark.sql.inMemoryColumnarStorage.batchSize:
When caching SchemaRDDs, Spark SQL groups together the records in the RDD in batches of the size given by this option (default: 1000), and compresses each batch. Very small batch sizes lead to low compression, but on the other hand very large sizes can also be problematic, as each batch might be too large to build up in memory.
MySQL性能优化(硬件,系统配置,表结构,SQL语句) 想必大家都知道,面试期间一提到数据库,就会聊到数据库优化相关问题。网上关于数据库优化的文章也是眼花缭乱,层出不穷。今天将会通过这篇文章细分几点给大家汇总整理出一套关于MySQL数据库的优化方案,让大家通过学习这篇文章不再被面试官吊打!
相关文章
- SQL Server使用Offset/Fetch Next实现分页
- 如何转换SQL Server 2008数据库到SQL Server 2005
- SQL疑难杂症【3】链接服务器提示"无法启动分布式事物"
- SQL Server调优系列基础篇(并行运算总结)
- [Postgres] Removing Data with SQL Delete, Truncate, and Drop
- SQL语句基础
- Hudi(7):Hudi集成Spark之spark-sql方式
- SQL Server 为什么事务日志自动增长会降低你的性能
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- 使用事务码 SAT 比较传统的 SELECT SQL 语句和 OPEN / FETCH CURSOR 分块读取 ABAP 数据库表两种方式的性能差异试读版
- SQL编码中注意的性能问题
- SQL Server DATEADD() 函数
- 替代sql in 性能优化
- 十八般武艺玩转GaussDB(DWS)性能调优(二):坏味道SQL识别
- 【编程实践】每个开发者都应该知道的数据库查询 SQL 命令
- SQL 常用操作
- shell动态生成.sql文件的方法进阶
- sql 精读(五) 标准 SQL窗口函数一
- sql 精读(三) 标准 SQL 中的编号函数示例
- sql判断字段是否为空
- IDEA : SQL dialect is not configured
- mysql_18 _ 为什么这些SQL语句逻辑相同,性能却差异巨大
- Oracle SQL性能优化篇02-选用适合的Oracle优化器
- 基础SQL Server 操作问题——仅当使用了列表并且IDENTITY_INSERT为ON时,才能为表中的标识列制定显示值