
并发系列64章(异步编程)第二章
前言
异步编程的概念我在第一章概要的时候,提及了。在此再次简略概要一次。
它采用future模式或者回调模式机制,以避免产生不必要的线程。
异步编程测试的标准
在第一个写这个的原因,是因为测试可能比开发重要。因为在开发一个项目的时候呢?有一个自动化高效精准测试,决定了上线是否稳定。因为程序出bug测试出来可以改,方案不行换方案,但是测试不行上线了。这时候面临的问题就比较大,因为这时候产生了数据。
比如说 app 一张表的设计不合理,在自动化测试中没有体现出来,那么你要更换表的时候就显得异常困难,这时候到底换不换表的结构呢?换了之后,如何兼容之前的版本?迭代的方案是啥。好的,扯得很远了。
当然我们作为开发人员也要做好单元测试,及子系统测试。好的,近了一点了。
我们在写一个异步程序的时候,是有3个测试必须通过。
1.同步成功
2.异步成功
3.异步失败
先介绍一下如何异步测试:
public static async Task<T> DelayResult<T>(T result, TimeSpan delay)
{
await Task.Delay(delay);
return result;
}
如何测试的时候如果这样写:
[Fact]
public async void Test1()
{
TimeSpan timeSpan = new TimeSpan();
Program.DelayResult<int>(1, timeSpan);
}
那么这个测试是有问题的。
比如:
public static async Task<T> DelayResult<T>(T result, TimeSpan delay)
{
await Task.Delay(delay);
throw new Exception("error");
return result;
}
本来我是应该抛出异常的,但是:

结果是下面这样的。
原因就涉及到一个异常捕获的问题了,可以查询一下原理。
运行测试的时候应该加上await:
[Fact]
public async void Test1()
{
TimeSpan timeSpan = new TimeSpan();
await Program.DelayResult<int>(1, timeSpan);
}
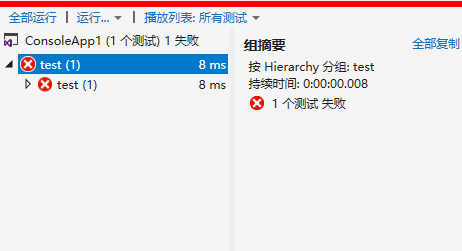
那么这个时候就可以捕获到异常。
下面介绍一些例子。
指数退避
这个是什么意思呢?比如说,我们访问我们的一条url的时候,访问失败。
接下来我们应该做的是重试,那么是否马上重试?不是的,除非是阻塞式的api调用,例如登录。
但是呢,如果不是阻塞式的,那么应该把资源分配均衡。因为你一次失败,第二次的也有可能失败。
那么这时候指数退避是一种良好的方法。
static async Task<string> visitUrl(string url)
{
using (var client = new HttpClient())
{
var nextDelay = TimeSpan.FromSeconds(1);
for (int i = 0; i != 3; ++i)
{
try
{
return await client.GetStringAsync(url);
}
catch
{
}
await Task.Delay(nextDelay);
nextDelay = nextDelay + nextDelay;
}
// 返回最后的结果方便得出错误
return await client.GetStringAsync(url);
}
}
测试:
[Fact]
public async void Test1()
{
await Program.visitUrl("www.xxx.com");
}
结果:

测试花了7秒。
正确验证测试我就不测了。
实现超时功能
上面的这个代码,我们发现一个问题啊,如果访问那个链接要好久,那么这也很受伤啊。
是否能加入一个超时,如果访问一段时间没有返回结果,那么把资源留给别的需求者。
public static async Task<string> visitTimeoutUrl(HttpClient client,string url)
{
var visitTask=client.GetStringAsync(url);
var timeoutTask = Task.Delay(3000);
var completedTask = await Task.WhenAny(visitTask,timeoutTask);
if (completedTask == timeoutTask)
{
return null;
}
return await visitTask;
}
上文实现了一个简单的超时。
然后改一下:
public static async Task<string> visitUrl(string url)
{
using (var client = new HttpClient())
{
var nextDelay = TimeSpan.FromSeconds(1);
for (int i = 0; i != 3; ++i)
{
try
{
var result= await visitTimeoutUrl(client,url);
if (result != null)
{
return result;
}
}
catch
{
}
await Task.Delay(nextDelay);
nextDelay = nextDelay + nextDelay;
}
// 返回最后的结果方便得出错误
return await visitTimeoutUrl(client, url);
}
}
未完
今天写博客的时候,一直出现error,就先到这吧。
下一章,还是几个例子感受一下。以上为个人理解,如有不对望请指出。
相关文章
- 奉劝那些刚参加工作的学弟学妹们:要想学好并发编程,这些并发容器的坑是你必须要注意的!!(建议收藏)「建议收藏」
- java volatile关键字的作用_Java并发编程彻底搞懂volatile关键字「建议收藏」
- 聊聊并发编程的10个坑
- 同步类容器和并发类容器的区别_jdk提供的用于并发编程的同步器有
- 高并发核心编程SpringCloud+Nginx秒杀实战,秒杀系统的系统架构
- 【深度长文】学好并发编程不一定需要了解的MESI和内存屏障
- PHP 使用数据库的并发问题
- Java高并发之CyclicBarrier简介
- 【Java并发编程】- 02 线程池总结
- 【Java 并发编程】线程简介 ( 并发类型 | 线程状态 | CPU 数据缓存 )
- 【Java 并发编程】线程池机制 ( 线程池阻塞队列 | 线程池拒绝策略 | 使用 ThreadPoolExecutor 自定义线程池参数 )
- 干货:Java并发编程必懂知识点解析详解编程语言
- Java 多线程并发编程之 Synchronized 关键字详解编程语言
- Java 并发开发:Lock 框架详解编程语言
- Java并发编程之内存模型详解编程语言
- 【Java并发编程(1)】:可重入内置锁详解编程语言
- Linux并发编程:引领软件新思维(linux并发编程思想)
- C++ 并发编程,std::unique_lock与std::lock_guard区别示例详解编程语言
- Oracle数据库并发控制技术(oracle并发控制)
- Java并发编程视频分享-第一期
- MySQL实现1万并发连接的架构优化(mysql1万并发)
- Oracle SQL:如何避免并发问题(oraclesql并发)
- MySQL锁机制:如何实现高效的并发控制(mysql锁是如何实现的)
- 破解单机Redis的高并发读写大门(单机redis高并发读写)
- Redis实现高性能高可用的高并发系统(redis 高并发高可用)
- 解析Redis高并发的缺点(redis高并发缺点)
- 解决Redis高并发系统中的瓶颈问题(redis高并发的问题)
- Java并发编程示例(一):线程的创建和执行
- Java并发编程示例(七):守护线程的创建和运行