
scrapy怎么同时运行多个爬虫?
2023-09-14 08:59:02 时间
######
可以通过以下几种方式:
1.开启多个命令行,分别执行scrapy cralw xxxx
2.编写一个脚本,写入以下代码,执行工程下的所有爬虫:
from scrapy.utils.project import get_project_settings from scrapy.crawler import CrawlerProcess def main(): setting = get_project_settings() process = CrawlerProcess(setting) didntWorkSpider = ['sample'] for spider_name in process.spiders.list(): if spider_name in didntWorkSpider : continue print("Running spider %s" % (spider_name)) process.crawl(spider_name) process.start()
3.使用scrapyd,部署爬虫,通过scrapyd的API调用爬虫
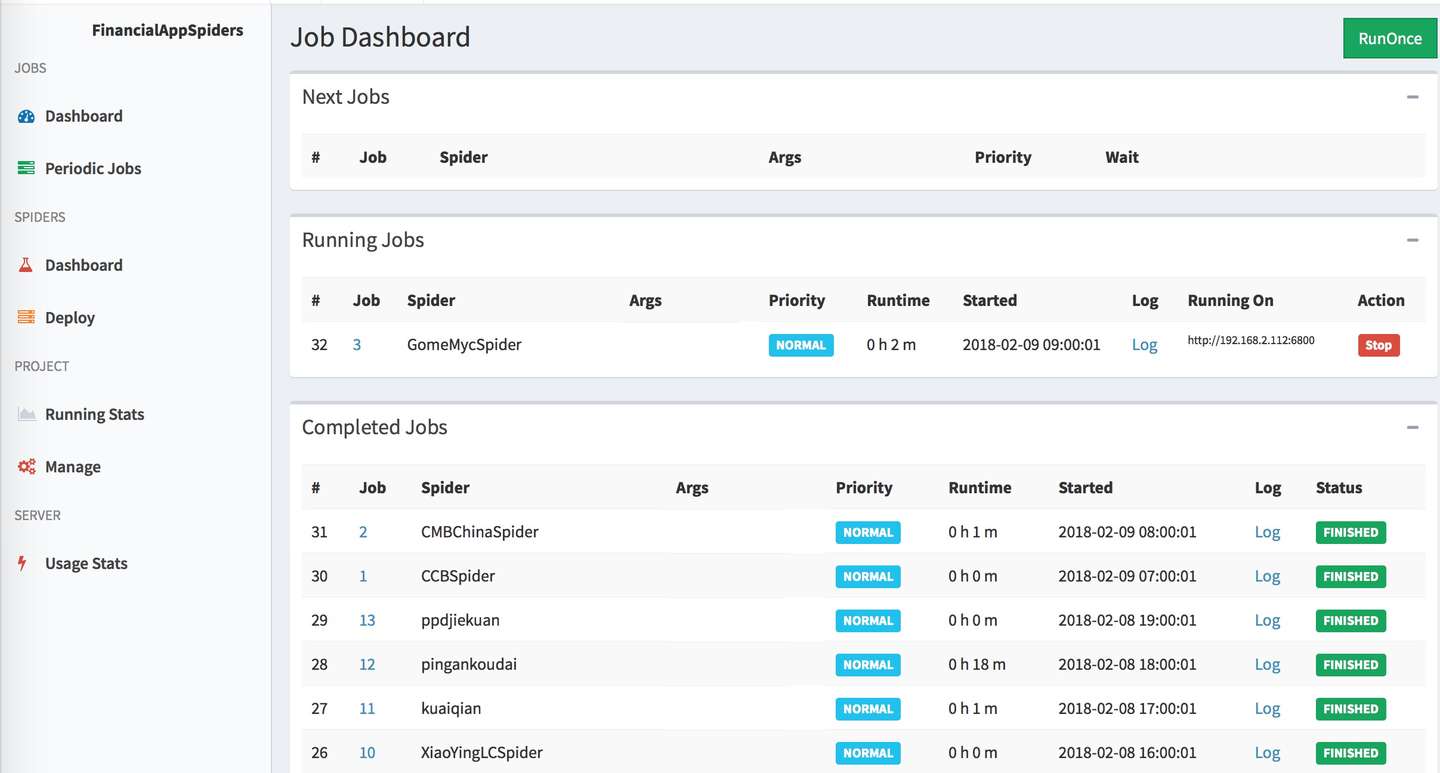
4.推荐使用spiderkeeper或者gerapy,这两个提供的WebUI都很好用,个人更喜欢spiderkeeper一些,因为可以定时运行爬虫。
如图:

####
####
相关文章
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
- 第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
- 爬虫scrapy快速解析
- scrapy框架使用.Request使用meta传递数据,以及deepcopy的使用,这种三层for循环,就会有deepcopy的问题,
- Scrapy+eChart自动爬取生成网络安全词云
- scrapy设置cookie的三种方式
- scrapy主动触发关闭爬虫
- Python编程:windows安装scrapy及报错
- Python爬虫:关于scrapy、Gerapy等爬虫相关框架和工具
- 爬虫日记(83):Scrapy的CrawlerProcess类(三)
- 爬虫日记(61):Scrapy的数据去重处理管道
- 爬虫日记(24):Scrapy 中设置随机 User-Agent
- 爬虫日记(16):scrapy特殊功能的蜘蛛类
- 基于Python的scrapy框架的广州天气爬虫源码下载