
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
2023-09-14 08:58:24 时间
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
我们自定义一个main.py来作为启动文件
main.py
#!/usr/bin/env python # -*- coding:utf8 -*- from scrapy.cmdline import execute #导入执行scrapy命令方法 import sys import os sys.path.append(os.path.join(os.getcwd())) #给Python解释器,添加模块新路径 ,将main.py文件所在目录添加到Python解释器 execute(['scrapy', 'crawl', 'pach', '--nolog']) #执行scrapy命令
爬虫文件
# -*- coding: utf-8 -*- import scrapy from scrapy.http import Request import urllib.response from lxml import etree import re class PachSpider(scrapy.Spider): name = 'pach' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): pass
xpath表达式
1、
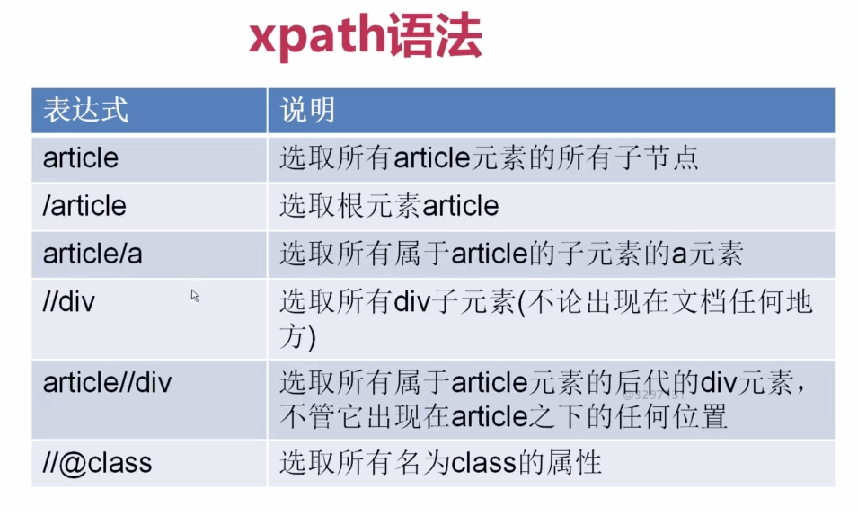
2、
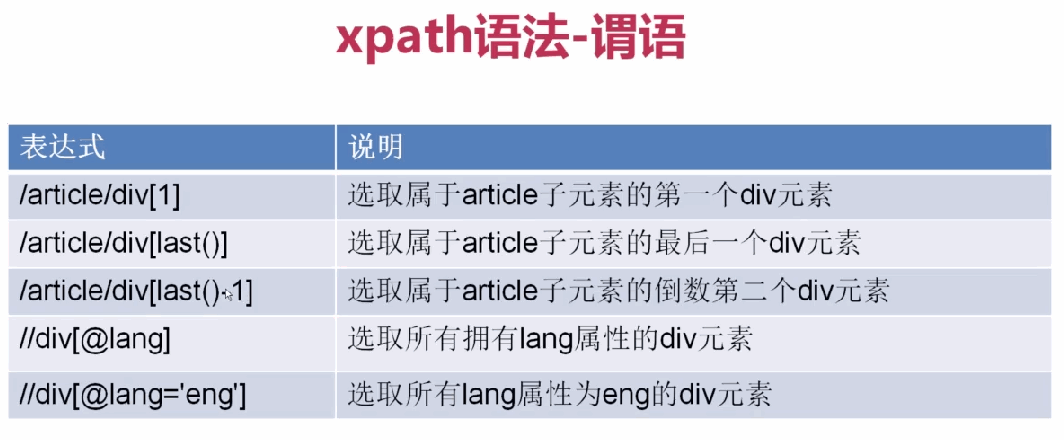
3、

基本使用
allowed_domains设置爬虫起始域名
start_urls设置爬虫起始url地址
parse(response)默认爬虫回调函数,response返回的是爬虫获取到的html信息对象,里面封装了一些关于htnl信息的方法和属性
responsehtml信息对象下的方法和属性
response.url获取抓取的rul
response.body获取网页内容
response.body_as_unicode()获取网站内容unicode编码
xpath()方法,用xpath表达式过滤节点
extract()方法,获取过滤后的数据,返回列表
# -*- coding: utf-8 -*- import scrapy class PachSpider(scrapy.Spider): name = 'pach' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): leir = response.xpath('//a[@class="archive-title"]/text()').extract() #获取指定标题 leir2 = response.xpath('//a[@class="archive-title"]/@href ').extract() #获取指定url print(response.url) #获取抓取的rul print(response.body) #获取网页内容 print(response.body_as_unicode()) #获取网站内容unicode编码 for i in leir: print(i) for i in leir2: print(i)
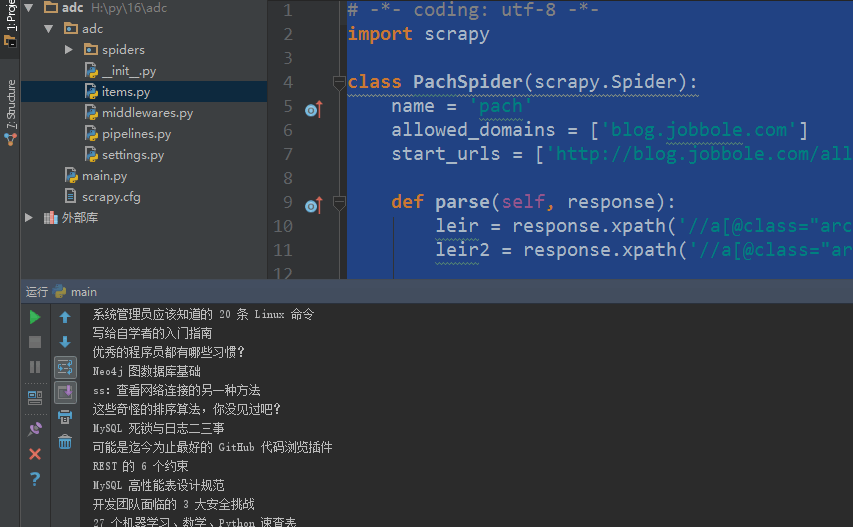
相关文章
- 如何为pycharm配置Python解释器_pycharm选择python解释器
- 2022年最新Python大数据之Python基础【八】文件的操作与类
- python venv文件夹_pycharm的venv文件夹的自定义处理「建议收藏」
- 如何使用python删除一个文件?
- python安装不了whl文件_Python安装whl文件过程图解
- python删除首行_Python删除文件第一行
- Python入门系列(五)一篇搞懂python语句
- Python—-pywin32如何获取窗口句柄
- 怎么用python打开csv文件_Python文本处理之csv-csv文件怎么打开[通俗易懂]
- python对csv文件的读写
- 【说站】python输入成绩求平均分
- 【说站】python中Pylint的信息类型
- python输出unicode编码_Python以utf8编码读取文件
- python打开h5文件可视化_python环境变量的配置
- python读取pkl_Python读取文件的一段内容
- Python保存json_python保存json文件
- python判断文件后缀_Python 判断文件后缀是否被篡改
- 使用Python批量筛选上千个Excel文件中的某一行数据并另存为新Excel文件(下篇)
- Windows安装和配置Python及pip.ini文件配置
- 跟着Nature ecology and evolution学python:vcf文件转换成fasta文件
- python免费压缩PDF文件
- 这款编译器能让Python和C++一样快:最高提速百倍,MIT出品
- python-Python与SQLite数据库-SQLite数据库的基本知识(一)
- python-Python与SQLite数据库-使用Python执行SQLite查询(二)
- python-Python与MongoDB数据库-MongoDB数据库的基本知识
- Python抓取文件夹的所有文件,包括子文件夹和子文件夹的文件详解编程语言
- 管理Linux系统下Python文件管理实践(linuxpy文件)
- 使用Python连接MySQL数据库,实现高效数据交互(python连接mysql)
- Linux系统下安装Python模块指南(linux安装python模块)
- Linux下Python编程:从入门到精通(linux下python编程)
- Python中无限元素列表的实现方法