
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1、映射(mapping)介绍
映射:创建索引的时候,可以预先定义字段的类型以及相关属性
elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项,mapping就是我们自己定义的字段数据类型,同时告诉elasticsearch如何索引数据以及是否可以被搜索
作用:会让索引建立的更加细致和完善
类型:静态映射和动态映射
2、内置映射类型(也就是数据类型)
string类型:text,keyword两种
text类型:会进行分词,抽取词干,建立倒排索引
keyword类型:就是一个普通字符串,只能完全匹配才能搜索到
数字类型:long,integer,short,byte,double,float
日期类型:date
bool(布尔)类型:boolean
binary(二进制)类型:binary
复杂类型:object,nested
geo(地区)类型:geo-point,geo-shape
专业类型:ip,competion
3、属性介绍
store属性
index属性
null_value属性
analyzer属性
include_in_all属性
format属性

更多属性:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-boost.html
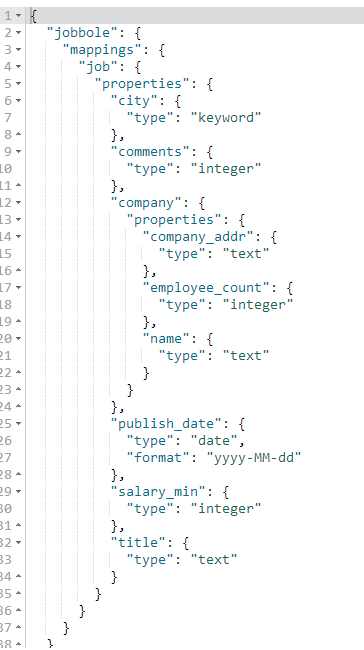
4、创建索引(相当于创建数据库)、创建表、创建字段-设置字段类型,添加数据
说明:
#创建索引(设置字段类型) PUT jobbole #创建索引设置索引名称 { "mappings": { #设置mappings映射字段类型 "job": { #表名称 "properties": { #设置字段类型 "title":{ #title字段 "type": "text" #text类型,text类型可以分词,建立倒排索引 }, "salary_min":{ #salary_min字段 "type": "integer" #integer数字类型 }, "city":{ #city字段 "type": "keyword" #keyword普通字符串类型 }, "company":{ #company字段,是嵌套字段 "properties":{ #设置嵌套字段类型 "name":{ #name字段 "type":"text" #text类型 }, "company_addr":{ #company_addr字段 "type":"text" #text类型 }, "employee_count":{ #employee_count字段 "type":"integer" #integer数字类型 } } }, "publish_date":{ #publish_date字段 "type": "date", #date时间类型 "format":"yyyy-MM-dd" #yyyy-MM-dd格式化时间样式 }, "comments":{ #comments字段 "type": "integer" #integer数字类型 } } } } } #保存文档(相当于数据库的写入数据) PUT jobbole/job/1 #索引名称/表/id { "title":"python分布式爬虫开发", #字段名称:字段值 "salary_min":15000, #字段名称:字段值 "city":"北京", #字段名称:字段值 "company":{ #嵌套字段 "name":"百度", #字段名称:字段值 "company_addr":"北京市软件园", #字段名称:字段值 "employee_count":50 #字段名称:字段值 }, "publish_date":"2017-4-16", #字段名称:字段值 "comments":15 #字段名称:字段值 }
代码:
#创建索引(设置字段类型) PUT jobbole { "mappings": { "job": { "properties": { "title":{ "type": "text" }, "salary_min":{ "type": "integer" }, "city":{ "type": "keyword" }, "company":{ "properties":{ "name":{ "type":"text" }, "company_addr":{ "type":"text" }, "employee_count":{ "type":"integer" } } }, "publish_date":{ "type": "date", "format":"yyyy-MM-dd" }, "comments":{ "type": "integer" } } } } } #保存文档(相当于数据库的写入数据) PUT jobbole/job/1 { "title":"python分布式爬虫开发", "salary_min":15000, "city":"北京", "company":{ "name":"百度", "company_addr":"北京市软件园", "employee_count":50 }, "publish_date":"2017-4-16", "comments":15 }
5、获取索引下的mappings映射字段类型
#获取一个索引下的所有表的mappings映射字段类型 GET jobbole/_mapping #获取一个索引下的指定表的mappings映射字段类型 GET jobbole/_mapping/job
【重点】在创建索引时一旦给字段设置了类型后就不可修改了,如果必须要修改就的重新创建索引,所以在创建索引时就必须确定好字段类型
相关文章
- 用 Python 控制了室友电脑的开机密码
- python qt是什么_初识Python与Qt「建议收藏」
- python编程是什么-Python编程
- python控制mt4自动交易软件下载_MT4 EA智能自动交易系统使用教程[通俗易懂]
- python的random()函数用法_Python随机函数random用法示例
- python截图识别文字_Python文字截图识别OCR工具实例解析
- python-sort函数[通俗易懂]
- 学习爬虫之Scrapy框架学习(六)–1.直接使用scrapy;使用scrapy管道;使用scrapy的媒体管道类进行猫咪图片存储。媒体管道类学习。自建媒体管道类存储图片
- Python 爬虫 校花网[通俗易懂]
- python chr()和ord()_Python函数ord
- Python爬虫——爬取王者荣耀全英雄台词语音
- Python编程 标识符
- 【说站】python os.path.join()函数的使用
- PYTHON-列表推导式「建议收藏」
- python爬虫scrapy框架_python主流爬虫框架
- 正则表达式Python_python正则表达式匹配字符串
- python如何判断一个目录下是否存在某个文件?
- Python分布式爬虫框架Scrapy 打造搜索引擎(四) - 爬取博客网站
- Python中的装饰器
- scrapy 管理部署的爬虫项目的python类详解程序员
- 高效爬虫利器:Redis与Scrapy的完美结合(redis scrapy)
- python爬虫教程之爬取百度贴吧并下载的示例
- 使用Python编写简单网络爬虫抓取视频下载资源
- 零基础写python爬虫之爬虫的定义及URL构成