
单链表操作之插入
一、在开始处插入
链表结构存在优于线性操作的几种操作。再某些情况下,这些操作使得链表结构比数组更加合适。第一种情况就是在结构的开始处插入一项。如下:
# coding: utf-8 class Node(object): def __init__(self, data, next=None): self.data = data self.next = next head = None for count in range(1,6): head = Node(count, head) print head.data, head.next,head newItem = 100 head = Node(newItem, head)
下图记录了这个操作的两种情况。在第一种情况下,head指针是None,因此向结构中插入了第1项。第2种情况下,将第2项插入到了同一结构的开头处。
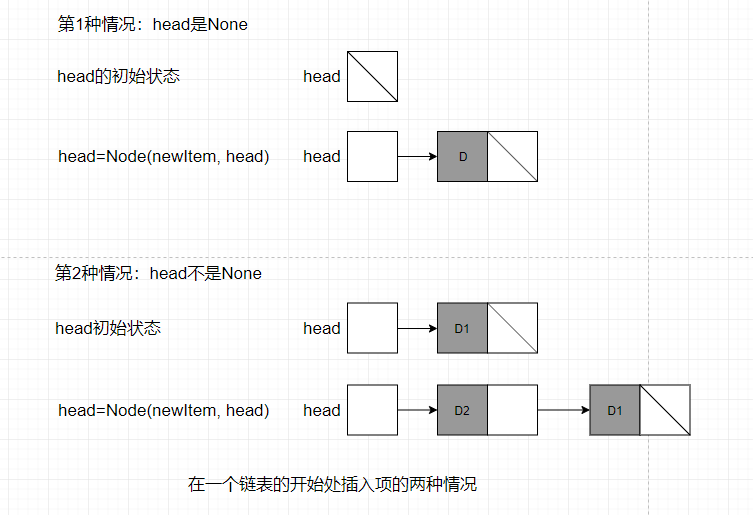
注意第2种情况,不需要复制数据并向下移动,并且不需要额外的内存。这意味着,在一个链表结构的开始处插入数据,时间和内存都是常数,这与数组的响应操作有所不同。
二、在行尾插入
在一个数组的行尾插入一项(python的oppend操作)需要的时间和内存都是常数,除非必须调整数组大小。对于单链表来说,在行尾插入一项必须考虑如下两种情况:
- head指针为None,此时,将head指针设置为新的节点。
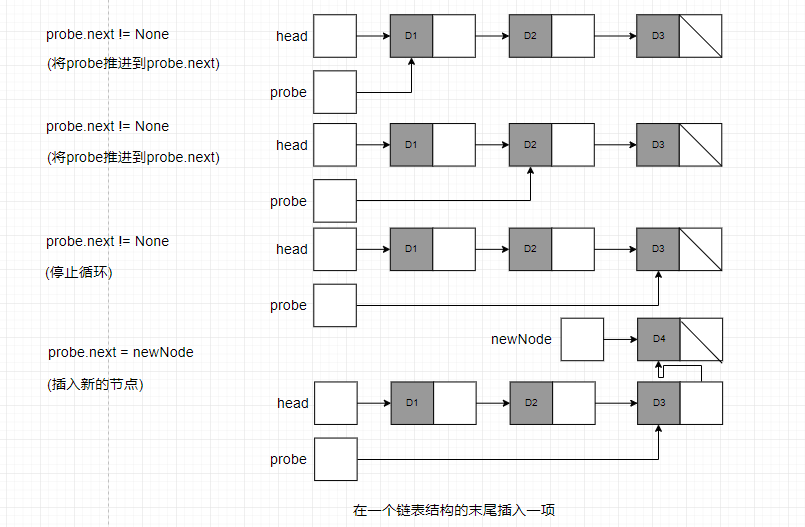
- head指针不为None,此时,代码将搜索最后一个节点,并将其next指针指向新的节点。
第2种情况又回到遍历模式。其形式如下:
# coding: utf-8 class Node(object): def __init__(self, data, next=None): self.data = data self.next = next head = None for count in range(1,4): # 为了尽量减少下图的步骤,此处创建有3个节点的单链表 head = Node(count, head) print head.data, head.next,head newItem = 100 newNode = Node(newItem) if head is None: head = newNode else: probe = head while probe.next != None: probe = probe.next probe.next = newNode while head.next: head = head.next print head.data
这样就在head链表末尾插入一个新的链接。该操作在时间上是线性的,在空间是是常数的。
三、在任何位置插入
在数组第i个位置插入一项,需要将从位置i到n+1的项都想下移动。因此,实际上是在当前位于i位置的项的前面插入了一项,从而让新的项占据了i位置,而旧的项则占据了i+1的位置。
在一个链表中的第i个位置插入一项,也必须处理相同的情况。在i的位置插入一项,首先必须找到位置为i-1(如果i<n)或n-1(如果i>=n)的节点。然后考虑如下两种情况:
- 该节点的next指针weiNone。意味着,i>=n,因此应该将新的项放在链表结构的末尾。
- 该节点的next指针不为None,意味着,0<i<n,因此必须将新的项放在位于i-1和i的节点之间。
和搜索第i项相同,插入操作必须计数节点,直到到达了想要的位置。然而,由于目标索引可能会大于或等于节点的数目,因此在搜索中,必须小心避免超出链表结构的末尾。为了解决这一问题,循环有一个额外的条件,就是测试当前节点的next指针,看看这个节点是否为最后一个节点。形式如下:
# coding: utf-8 class Node(object): def __init__(self, data, next=None): self.data = data self.next = next head = None for count in range(1,4): head = Node(count, head) print head.data, head.next,head index = 2 newItem = 100 if head is None or index <= 0: head = Node(newItem, head) else: probe = head while index > 1 and probe.next != None: probe = probe.next index -= 1 probe.next = Node(newItem, probe.next)
下图展示了包含3个项的链表结构的第二个位置插入一项的情况。
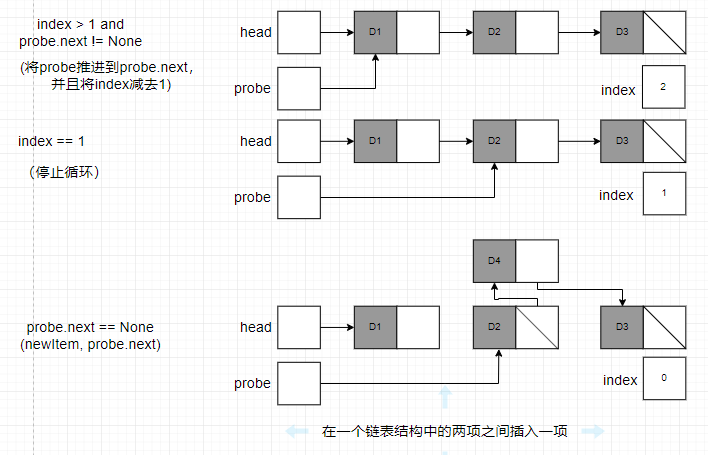
和使用了遍历模式的单链表结构操作一样,这个操作也是线性的。然而,它使用的内存确是常数的。
结束!
相关文章
- MySQL 批量操作,一次插入多少行数据效率最高?
- SpringBoot 使用 FTP 操作文件
- 【Android 应用开发】Activity 返回堆栈清除操作 ( 默认状态 | 清除返回堆栈配置 | 不清除返回堆栈配置 | 清除指定界面配置 )
- MongoDB 数据库基础 之 CRUD操作中的插入范例
- PostgreSQL upsert(插入更新)数据的操作详解
- 从控制台输入输出,来进行数据库的插入和查询操作的小程序详解数据库
- 一:Mongodb快速入门之使用Java操作Mongodb详解大数据
- Linux快速操作数据库的技巧与技术(linux怎么操作数据库)
- 极速操作:如何快速连接 Redis(怎么连接redis)
- Oracle中插入数据的快速操作技巧(oracle插入数据语句)
- PHP与MySQL之间的数据插入操作技巧(phpmysql插入)
- C语言实现MySQL数据库插入操作(c语言插入mysql)
- 深入探究MySQL批量插入操作对性能的影响(mysql批量插入性能)
- Oracle插入记录:操作指南(oracle插入一条记录)
- 如何避免Oracle数据库中的重复插入操作(oracle重复插入)
- SQL Server中快速插入列操作指南(sqlserver插入列)
- Oracle游标操作的详细指南(oracle游标使用步骤)
- MSSQL数据库附加:一步操作帮助您简化迁移(mssql附加)
- MSSQL中利用表变量插入操作缓慢的原因分析(mssql表变量插入慢)
- 如何通过 MySQL 将两个表进行插入操作(mysql两表插入)
- 用C语言编写Oracle插入语句实现数据操作(c 插入oracle语句)
- MySQL插入数据操作详解(mysql。insert)
- MySQL禁止文件写入操作(mysql不允许写到文件)
- python数据库操作常用功能使用详解(创建表/插入数据/获取数据)
- Python操作sqlite3快速、安全插入数据(防注入)的实例
- C++操作MySQL大量数据插入效率低下的解决方法