
Apache Mina通信框架架构与应用
从官网文档“MINA based Application Architecture”中可以看到Mina作为一个通信层框架,在实际应用所处的位置,如图所示:
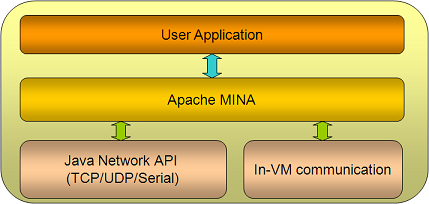
Mina位于用户应用程序和底层Java网络API(和in-VM通信)之间,我们开发基于Mina的网络应用程序,就无需关心复杂的通信细节。
应用整体架构
再看一下,Mina提供的基本组件,如图所示:
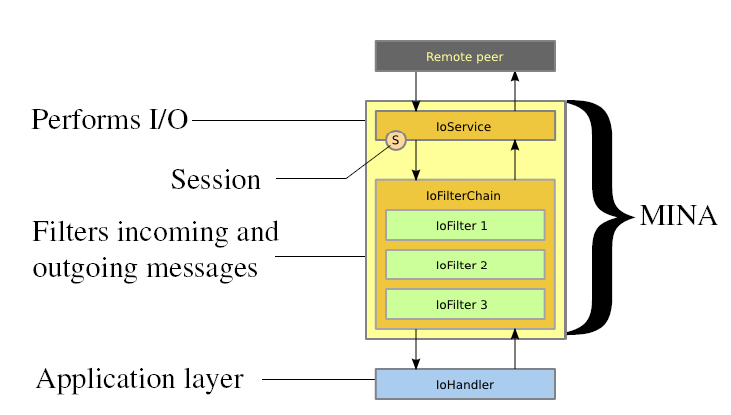
也就是说,无论是客户端还是服务端,使用Mina框架实现通信的逻辑分层在概念上统一的,即包含如下三层:
I/O Service – Performs actual I/O I/O Filter Chain – Filters/Transforms bytes into desired Data Structures and vice-versa I/O Handler – Here resides the actual business logic想要开发基于MIna的应用程序,你只需要做如下事情:
Create an I/O service – Choose from already available Services (*Acceptor) or create your own Create a Filter Chain – Choose from already existing Filters or create a custom Filter for transforming request/response Create an I/O Handler – Write business logic, on handling different messages下面看一下使用Mina的应用程序,在服务器端和客户端的架构细节:
服务器端架构
服务器端监听指定端口上到来的请求,对这些请求经过处理后,回复响应。它也会创建并处理一个链接过来的客户会话对象(Session)。服务器端架构如图所示:
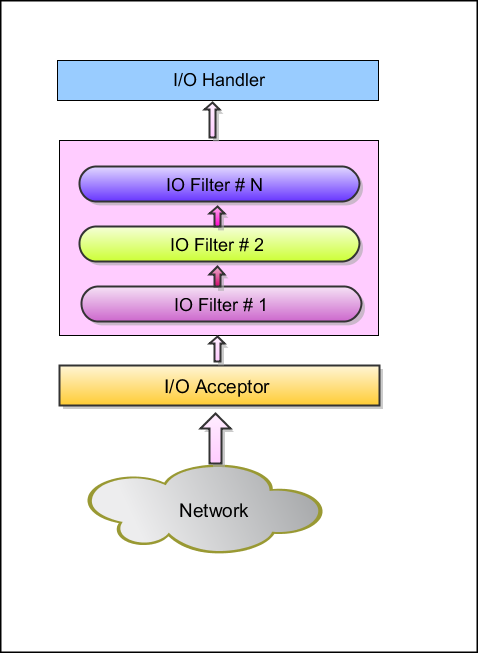
对服务器端的说明,引用官网文档,如下所示:
IOAcceptor listens on the network for incoming connections/packets For a new connection, a new session is created and all subsequent request from IP Address/Port combination are handled in that Session All packets received for a Session, traverses the Filter Chain as specified in the diagram. Filters can be used to modify the content of packets (like converting to Objects, adding/removing information etc). For converting to/from raw bytes to High Level Objects, PacketEncoder/Decoder are particularly useful Finally the packet or converted object lands in IOHandler. IOHandlers can be used to fulfill business needs.客户端架构
客户端主要做了如下工作:
客户端架构,如图所示:
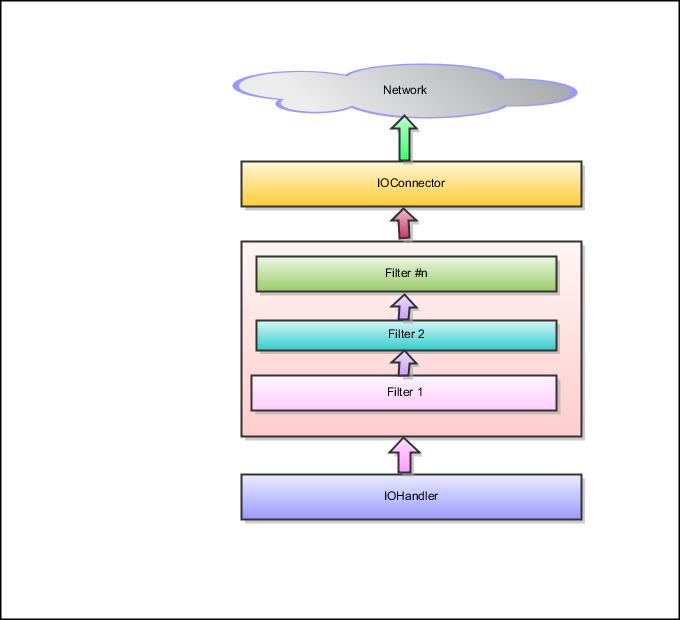
对客户端架构的说明,引用官网文档内容,如下所示:
Client first creates an IOConnector (MINA Construct for connecting to Socket), initiates a bind with Server Upon Connection creation, a Session is created and is associated with Connection Application/Client writes to the Session, resulting in data being sent to Server, after traversing the Filter Chain All the responses/messages received from Server are traverses the Filter Chain and lands at IOHandler, for processing应用实例开发
下面根据上面给出的架构设计描述,看一下Mina(版本2.0.7)自带的例子,如何实现一个简单的C/S通信的程序,非常容易。
服务端
首先,服务器端需要使用的组件有IoAdaptor、IoHandler、IoFilter,其中IoFilter可选.
我们基于Mina自带的例子进行了简单地修改,实现服务端IoHandler的代码如下所示:
private final static Logger LOGGER = LoggerFactory.getLogger(TinyServerProtocolHandler.class);
这个版本中,IoHandlerAdapter实现了IoHandler接口,里面封装了一组用于事件处理的空方法,其中包含服务端和客户端的事件。在实际应用中,客户端可以选择客户端具有的事件,服务器端选择服务器端具有的事件,然后分别对这两类事件进行处理(有重叠的事件,如连接事件、关闭事件、异常事件等)。
客户端的IoHandler的具体实现也是类似的,不过多累述。
下面看启动服务器的主方法类,代码如下所示:
acceptor.getFilterChain().addLast("codec", new ProtocolCodecFilter(newTextLineCodecFactory()));
LOG.info("R: " + acceptor.getStatistics().getReadBytesThroughput() + ", W: " + acceptor.getStatistics().getWrittenBytesThroughput());
connector.getFilterChain().addLast("codec", new ProtocolCodecFilter(newTextLineCodecFactory()));
我们只是发送了十个数字,每发一次间隔1500ms。
测试上述服务器端与客户端交互,首先启动服务器端,监听8080端口。
接着启动客户端,连接到服务器端8080端口,然后发送消息,服务器端接收到消息后,直接将到客户端的连接关闭掉。
应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设 同程数科成立于 2015 年,是同程集团旗下的旅游产业金融服务平台。2020 年,同程数科基于 Apache Doris 丰富的数据接入方式、优异的并行运算能力、极简运维等特性,引入 Apache Doris 进行数仓架构2.0 的搭建。本文详细讲述了架构1.0 到 2.0 的演进过程及 Doris 的应用实践,希望对大家有所帮助
应用实践 | 10 亿数据秒级关联,货拉拉基于 Apache Doris 的 OLAP 体系演进 货拉拉成立于 2013 年,成长于粤港澳大湾区,是一家从事同城、跨城货运、企业版物流服务、搬家、汽车销售及车后市场服务的互联网物流公司。截至 2022 年 4 月,货拉拉的业务范围已经覆盖了国内 352 座城市,月活司机达到 58 万,月活用户达到 760 万,包含 8 条以上的业务线。 货拉拉大数据体系为支撑公司业务,现在已经成立三个 IDC 集群、拥有上千台规模的机器数量,存储量达到了 20PB、日均任务数达到了 20k 以上,并且还处在快速增长的过程中
Apache Hudi在华米科技的应用-湖仓一体化改造 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术。在华米科技,数据建设主要围绕两类数据:设备数据和APP数据,这些数据存在延迟上传、更新频率高且广、可删除等特性,基于这些特性,前期数仓ETL主要采取历史全量+增量模式来每日更新数据。随着业务的持续发展,现有数仓基础架构已经难以较好适应数据量的不断增长,带来的显著问题就是成本的不断增长和产出效率的降低。
Apache Hudi在Hopworks机器学习的应用 Hopsworks特征存储库统一了在线和批处理应用程序的特征访问而屏蔽了双数据库系统的复杂性。我们构建了一个可靠且高性能的服务,以将特征物化到在线特征存储库,不仅仅保证低延迟访问,而且还保证在服务时间可以访问最新鲜的特征值。
相关文章
- nginx php apache php 对比,Apache和nginx的比较「建议收藏」
- Apache站点优化-下载限速
- Apache配置虚拟主机_apache中配置虚拟主机的作用
- Apache配置虚拟主机_apache启动但是访问不到
- Linux 系统Apache配置SSL证书
- 2022 IoTDB Summit:中国核电刘旭嘉《工业时序数据库 Apache IoTDB 在核电的应用实践》
- 2022 IoTDB Summit:Dr.Feinauer《Apache IoTDB 在德国汽车生产线多级数据同步中的应用实践》
- 利用Apache commons exec 实现指定应用打开对应文件详解编程语言
- apache用Linux服务器架设QQ五笔输入法服务:基于Apache技术(qq五笔linux)
- 搭配Apache MySQL:超强联手服务器助力(apache和mysql)
- 的结合Apache和MySQL的完美结合(apache与mysql)
- Linux下Apache服务器扩展功能实现(linuxapxs)
- apache深度探索Linux下的Apache服务器(linuxgt)
- 使用Apache和MSSQL构建强大的数据库系统(apache mssql)
- 如何在Apache中配置MySQL数据库连接(mysql、apache)
- linux下安装apache与php;Apache+PHP+MySQL配置攻略
- Apache、SSL、MySQL和PHP平滑无缝地安装
- apache的access.log和error.log减肥
- Apache配置详解(最好的APACHE配置教程)
- win8下XAMPP中Apache模块无效(apache无法打开)的解决方法
- apache正常访问mht类型文件的配置方法
- apache密码生成工具htpasswd使用详解
- Linux+php+apache+oracle环境搭建之CentOS下安装Oracle数据库
- PHP脚本内存泄露导致Apache频繁宕机解决方法