
Apache Kafka使用默认配置执行一些负载测试来完成性能测试和基准测试
Kafka是一种分布式,分区,复制的提交日志服务。它提供了消息传递系统的功能。

我们先来看看它的消息传递术语:
- Kafka在称为主题的类别中维护消息的提要。
- 我们将调用向Kafka主题生成器发布消息的进程。
- 我们将调用订阅主题的流程并处理已发布消息的消费者。
- Kafka作为由一个或多个服务器组成的集群运行,每个服务器称为代理。
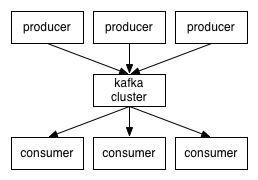
因此,在高层次上,生产者通过网络向Kafka集群发送消息,而Kafka集群又向消费者提供这样的服务:
有关Apache Kafka的更多信息,请参阅以下链接:
Kafka文档
因此,为了对Kafka进行性能测试或基准测试,我们需要考虑两个方面:
- Producer End的表现
- 消费者端的表现
我们需要为Producer和Consumer执行此测试,以便我们可以确保Producer可以生成多少消息,而Consumer可以在给定时间内消耗这些消息。对于大量消息,我们也可以确保数据丢失。
此测试的主要目的是找出以下统计信息:
1。数据大小的
吞吐量(消息/秒)2。消息数量的吞吐量(消息/秒)
3。总数据
4.消息总数
让我们继续下载并设置Kafka,请点击这里
完成后,您可以继续执行性能统计,按照下面提到的步骤执行此操作:
1.启动一个新的终端窗口
2.将目录设置为Kafka / bin
3.在这里您可以找到多个shell脚本,我们将使用以下内容来获取性能统计信息:
- kafka-producer-perf-test.sh
- kafka-consumer-perf-test.sh
如果要查看有关shell脚本(perf工具)的帮助,只需键入即可
sh ./kafka-producer-perf-test.sh --help
or
sh ./kafka-consumer-perf-test.sh --help分别为制片人和消费者。
Producer End的表现
在控制台上键入以下命令,然后按Enter键:
sh ./kafka-producer-perf-test.sh --broker-list localhost:9092 --topic test --messages 100让我们一个一个地理解这些命令行选项..
- 第一个参数是“broker-list”,在这里我们需要提到代理信息,它是代理的主机和引导程序的端口列表,这是必需的参数。
- 第二个参数是“topic”,这个参数还需要参数并显示我们之前讨论过的消息类别。
- 第三个显示您要生成和发送的消息数量,我们将第一个场景设置为100。
一旦测试完成,一些统计数据将打印在控制台上,如:
start.time:2016-02-03 21:38:28:094
end.time:2016-02-03 21:38:28:449
compression:0
message.size:100
batch.size:200
total.data.sent .in.MB:0.01
MB.sec:0.0269
total.data.sent.in.nMsg:100
nMsg.sec:281.6901
- start.time,end.time将显示测试何时开始并完成。
- 如果Compression为'0',则表示消息压缩已关闭(默认)。
- 信息。size显示每条消息的大小。
- batch.size表示一批中将发送的消息数,默认情况下设置为200。
- total.data.sent.in.MB显示以MB为单位发送到集群的总数据。
- MB.sec表示每秒以MB为单位传输的数据量(吞吐量大小)。
- total.data.sent.in.nMsg将显示在此测试期间发送的总消息数。
- 最后nMsg.sec显示一秒内发送的消息数(消息计数的吞吐量)。
在进行此性能测试时,您可以使用更多参数,例如;
- csv-reporter-enabled:如果设置,将启用CSV指标报告器
- initial-message-id:用于生成测试数据,如果设置,消息将使用ID标记,并由生产者从此ID开始按顺序发送。消息内容将是字符串类型,并以“消息:000 ... 1:abc ...”的形式,使用此参数,您将能够看到消费者正在消费的消息。
- message-size:它表示每条消息的大小,当你想用一些大的消息加载测试Kafka时,它会很有用。
- vary-message-size:如果设置,则消息大小将根据给定的最大值而变化。
还有一些其他选项可以在Producer性能测试期间根据需要使用。
对于这个博客,我根据消息的数量获取了一些性能数据,并通过图形内联显示了性能。
消费者端的表现
现在让我们看一下如何在消费者端获取性能统计数据,输入以下命令并按Enter键。
sh ./kafka-consumer-perf-test.sh --topic test --zookeeper localhost:2181让我们理解它的命令行选项,
- 第一个参数是“topic”,这个参数还需要参数并显示消息类别。
- 第二个参数是“zookeeper”,这个参数还需要参数,并以host:port的形式显示zookeeper连接的连接字符串。
一旦测试完成,一些统计数据将打印在控制台上,如:
start.time:2016-02-04 11:29:41:806
end.time:2016-02-04 11:29:46:854
fetch.size:1048576
data.consumed.in.MB:0.0954
MB.sec: 1.9869
data.consumed.in.nMs:1001
nMsg.sec:20854.1667
- start.time,end.time将显示测试何时开始并完成。
- fetch.size **显示单个请求中要获取的数据量。
- data.consumed.in.MB ****显示所有消息的大小。
- * ** MB.sec *表示每秒以MB为单位传输的数据量(吞吐量大小)。
- data.consumed.in.nMsg将显示在此测试期间消耗的总消息数。
- 最后nMsg.sec显示一秒内消耗的消息数量(消息计数的吞吐量)。
Consumer的性能测试也基于消息数量,结果以图形内联显示。
通过使用统计数据,我们可以决定批量大小,消息大小和给定配置可以生成/消耗的最大消息数,换句话说,我们可以为Kafka基准数量。
所有上述分析都是使用Kafka的默认设置完成的,可以有多种情况我们可以测试并获取Kafka Producer和Consumer的性能统计数据,其中一些情况可以是:
- 更改主题数量
- 更改异步批量大小
- 更改邮件大小
- 更改分区数
- 网络延迟
- 更改经纪人数量
- 更改生产者/消费者等的数量
上述更改可以在文件夹中可用的属性文件中完成:
sh /Kafka/kafka_2.9.1-0.8.2.2/config相关文章
- 四大开源协议比较:BSD、Apache、GPL、LGPL
- Apache系列:Centos7.2下安装与配置apache
- kafka学习之-雅虎开源管理工具Kafka Manager
- Apache Kafka - How to Load Test with JMeter
- Apache ZooKeeper在Kafka中的角色 - 监控和配置
- Apache Kafka工作流程| Kafka Pub-Sub Messaging
- 为什么Apache Kafka如此受欢迎
- Kafka压测— 搞垮kafka的方法(转)
- 自己玩KAFKA 版本 kafka_2.13-3.2.1
- CentOS Apache配置详解
- APACHE 2.2.8+TOMCAT6.0.14配置负载均衡
- CVE-2021-44228-Apache-Log4j-Rce漏洞反弹win&linux
- centos下yum搭建安装linux+apache+mysql+php环境
- Apache Spark源码走读(七)Standalone部署方式分析&sql的解析与执行
- Apache Doris 分析型数据库(一)数据库简介
- kafka可视化客户端工具(Kafka Tool)的基本使用
- kafka-eagle报错解决:Kafka version is “-“ or JMX Port is “-1“ maybe kafka broker jmxport disable.
- 在Docker Swarm上部署Apache Storm:第1部分
- centos下 Apache、php、mysql默认安装路径
- apache下配置认证用户
- Apache Flink®极简教程: 架构及原理 Stateful Computations over Data Streams
- 【大数据OLAP引擎】图文详解 Apache Kylin 架构原理
- Apache htaccess 重写假设文件存在!
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
- Maven deploy 报错: Failed to execute goal org.apache.maven.plugins:maven-deploy-plugin:deploy (default-deploy) on project Failed to retrieve remote metadata /maven-metadata.xml
- Kafka集群管理工具kafka-manager的安装使用
- 又一国产开源项目走向世界,百度RPC框架Apache bRPC正式成为ASF顶级项目
- Apache Impala数据连接
- 【消息中间件】Apache Kafka 教程
- 解开Kafka神秘的面纱(四):kafka stream及interceptor
- 解开Kafka神秘的面纱(五):kafka优雅应用
- Apache Kafka 消费者组示例
- Apache Kafka 基本操作
- Apache Kafka 工作流程
- Apache Kafka 基础
- Apache Kafka 集群架构
- Apache Kafka 概述