
Apache Crunch:简化编写MapReduce Pipeline程序
Apache Crunch提供了一套Java API,能够简化编写、测试、运行MapReduce Pipeline程序。Crunch的基本思想是隐藏编写MapReduce程序的细节,基于函数式编程的思想,定义了一套函数式编程接口,因为Java并不支持函数式编程,只能通过回调的方式来实现,虽然写起来代码不够美观简洁,但是编写MapReduce程序的思路是非常清晰的,而且比编写原生的MapReduce程序要容易地多。如果直接使用MapReduce API编写一个复杂的Pipeline程序,可能需要考虑好每个Job的细节(Map和Reduce的实现内容),而使用Crunch变成库来编写,只需要清晰地控制好要实现的业务逻辑处理的操作流程,调用Crunch提供的接口(类似函数操作的算子、如union、join、filter、groupBy、sort等等)。
下面,我们简单说明一下Crunch提供的一些功能或内容:
我们看一下Crunch提供的用来在处理分布式数据集的集合类型的抽象定义,如下面类图所示: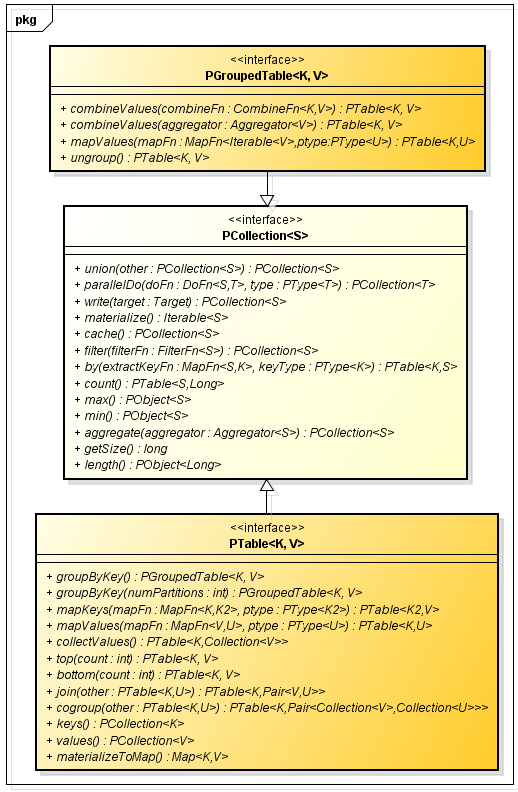
上面,我给出了集合类对应的方法签名,其中具有相同名称签名的方法还具有重载的其他方法签名(参数列表不同),Crunch集合类型的高层抽象就包含这3个接口,相关集合子类的实现可以参考Crunch源码。
连接操作(Join)上面类图中,PTable接口中有个一个join方法,这个默认是实现内连接功能(INNER JOIN),Crunch还提供了一个实现各种join操作的工具类,这个类中包含了join相关的静态方法,如下所示:
public static K, V PTable K, V sample(PTable K, V input, Long seed, doubleprobability)
public static T PCollection T reservoirSample(PCollection T input, int sampleSize, Long seed)
public static T, N extends Number PCollection T weightedReservoirSample(PCollection Pair T, N input, int sampleSize)
public static T, N extends Number PCollection T weightedReservoirSample(PCollection Pair T, N input, int sampleSize, Long seed)
public static T, N extends Number PCollection Pair Integer, T groupedWeightedReservoirSample( PTable Integer, Pair T, N input, int[] sampleSizes)
public static T, N extends Number PCollection Pair Integer, T groupedWeightedReservoirSample(PTable Integer, Pair T, N input, int[] sampleSizes, Long seed)
运行原生MapReduce程序
通过Mapreduce和Mapred两个工具类,可以运行我们已经存在的MapReduce程序,静态方法如下所示:
下面,我们通过实现两个例子,来体验使用Crunch和原生MapReduce API编程的不同。
WordCount计算词频程序
我们要实现的WordCount程序,基于Crunch编程库,按照操作来定义分为如下步骤:
从HDFS上读取一个保存Text文件的目录 将文件中每行内容根据空格分隔,分成 word, 单个单词词频 对(MapReduce程序的Map阶段) 将得到的集合按照key分组 化简结果得到每个单词的频率计数 word, 全局词频 (MapReduce程序的Reduce阶段) 根据单词全局词频计数,得到降序排序的结果集 输出结果到HDFS中基于上述步骤,根据Crunch编程库实现代码,如下所示:
Sort.sortPairs(reducedWords, ColumnOrder.by(2, Sort.Order.DESCENDING));
PTable String, Integer mappedWords = lines.parallelDo(new DoFn String, Pair String, Integer () {
public void process(String input, Emitter Pair String, Integer emitter) {
private final PTable String, Integer reduce(PGroupedTable String, Integer groupedWords) {
PTable String, Integer reducedWords = groupedWords.combineValues(newCombineFn String, Integer () {
public void process(Pair String, Iterable Integer values, Emitter Pair String, Integer emitter) {
上述代码中,可以在run方法中看到在完成一个计算任务的过程中,有序步骤序列中的每一步需要做什么都非常明确,而如果使用MapReduce API编写,我们可能会完全陷入API的使用方法中,而对整体执行流程没有一个更加直观的印象,尤其是对接触MapReduce不久的开发人员来说,更是难以理解。
运行程序和使用MapReduce API编写的程序使用相同的命令格式,下面运行我们基于Crunch编写的程序,执行如下命令:
hadoop jar crunch-0.0.1-SNAPSHOT.jar org.shirdrn.crunch.examples.WordCount /data/crunch/in /data/crunch/out
15/03/06 15:48:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/03/06 15:48:45 INFO impl.FileTargetImpl: Will write output files to new path: /data/crunch/out
15/03/06 15:48:45 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
15/03/06 15:48:46 INFO client.RMProxy: Connecting to ResourceManager at h1/192.168.4.142:8032
15/03/06 15:48:47 INFO Configuration.deprecation: dfs.block.size is deprecated. Instead, use dfs.blocksize
15/03/06 15:48:47 INFO input.CombineFileInputFormat: DEBUG: Terminated node allocation with : CompletedNodes: 2, size left: 51480009
15/03/06 15:48:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1422867923292_0012
15/03/06 15:48:48 INFO impl.YarnClientImpl: Submitted application application_1422867923292_0012
15/03/06 15:48:48 INFO jobcontrol.CrunchControlledJob: Running job "org.shirdrn.crunch.examples.WordCount: Text(/data/crunch/in)+S0+GBK+combine+S1+SeqFile(/tmp/crun... ID=1 (1/2)"
15/03/06 15:48:48 INFO jobcontrol.CrunchControlledJob: Job status available at:http://h1:8088/proxy/application_1422867923292_0012/
15/03/06 15:54:57 INFO client.RMProxy: Connecting to ResourceManager at h1/192.168.4.142:8032
15/03/06 15:54:58 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1422867923292_0013
15/03/06 15:54:58 INFO impl.YarnClientImpl: Submitted application application_1422867923292_0013
15/03/06 15:54:58 INFO jobcontrol.CrunchControlledJob: Running job "org.shirdrn.crunch.examples.WordCount: SeqFile(/tmp/crunch-1592377036/p1)+GBK+ungroup+PTables.va... ID=2 (2/2)"
15/03/06 15:54:58 INFO jobcontrol.CrunchControlledJob: Job status available at:http://h1:8088/proxy/application_1422867923292_0013/
上面,我们基于Crunch编程库实现的WordCount程序,最终在Hadoop集群上运行时,被转换成2个Job(application_1422867923292_0012和application_1422867923292_0013),也可以通过YARN Application页面,如图所示:
运行成功后,可以通过命令查看程序执行结果,内容如下所示:
15/03/06 16:24:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
表join操作程序
使用MapReduce API编写join程序时,非常复杂,尤其是如果对MapReduce执行的原理理解不是很深刻时,实现程序可能会有一点困难,而且完成后可能也不是很直观。下面,我们使用Crunch API来实现一个表join的例子,两个表做连接,首先准备的数据文件如下所示:
用户信息表用户信息表对应的文件为user_info.txt,这是来自手机应用程序的,包含两个字段,第一个是用户编号,第二个是做推广的渠道来源,中间使用TAB键分隔,文件行内容,示例如下所示:
渠道信息表
渠道信息表对应的文件为channel_info.txt,文件行内容包含两个字段,第一个是渠道编号,第二个是渠道名称,中间使用TAB键分隔,示例文件行内容如下所示:
由于用户表只保存了渠道编号,在出报表的时候需要将渠道名称显示出来,我们需要将两个表基于渠道编号做一个连接,就能在报表中展示用户所在的渠道名称。
使用Crunch实现这个需求时,非常简单明了,代码如下所示:
JoinUserChannel.class.getName() + " user_input channel_input output ");
PTable String, String left = users.parallelDo(new DoFn String, Pair String, String () {
public void process(String input, Emitter Pair String, String emitter) {
emitter.emit(Pair.of(channelId, userId)); // key=channelId, value=userId
PTable String, String right = channels.parallelDo(new DoFn String, Pair String, String () {
public void process(String input, Emitter Pair String, String emitter) {
emitter.emit(Pair.of(channelId, channelName)); // key=channelId, value=channelName
PTable String, Pair String, String joinedResult = Join.innerJoin(left, right);
首先分别将两个文件的数据读取到PCollection String 集合对象中,返回PTable String, String 集合对象,然后通过Join工具类调用innerJoin方法实现内连接操作,返回PTable String, Pair String, String ,最后写入HDFS文件系统中。进行表join操作时,如果是内连接,也可以直接调用PTable String, String 集合的join方法,与调用Join工具类的innerJoin和join方法功能相同。
运行上述程序,执行如下命令:
hadoop jar crunch-0.0.1-SNAPSHOT.jar org.shirdrn.crunch.examples.JoinUserChannel /data/crunch/user/user_info.txt /data/crunch/user/channel_info.txt /data/crunch/user/joined
15/03/06 18:53:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-rw-r--r-- 3 hadoop supergroup 0 2015-03-06 18:53 /data/crunch/user/joined/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 1777 2015-03-06 18:53 /data/crunch/user/joined/part-r-00000
15/03/06 18:54:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
总结说明
上面的两个例子只是简单使用Crunch开发了两MapReduce程序,无论对有经验的开发人员还是新手,都很容易上手开发。
目前,Crunch还处在项目初期,最新版本是0.11,当前只在Hadoop的2.2.0以及以下几个平台下测试过,如果在高于2.2.0的版本的平台上运行,可能会有若干一些小问题或不完善之处。上面我们开发的例子程序,就是运行在Hadoop 2.6.0平台上,比如在读取提交程序的节点上的Hadoop配置文件中block size配置时,不支持高版本的类似64m、2g等的配置内容,而必须使用数字类型表示的字节数配置。
Crunch后续开发迭代中一定会使各项功能更加完善,API也更加简洁,尤其是在程序运行调优方面,Crunch的目标是做到几乎不需要进行复杂的调优配置就能够使程序高效地运行,非常期待。
另外,Crunch也提供了对Spark计算平台的支持,想要了解与Spark计算相关的内容,可以参考官网文档。
有一个日志文件visitlog.txt,其中记录了用户访问网站的日期和访问的网站地址信息,每行一条记录。要求编写mapreduce程序完成以下功能: 1、 将不同访问日期的访问记录分配给不同的red 有一个日志文件visitlog.txt,其中记录了用户访问网站的日期和访问的网站地址信息,每行一条记录。要求编写mapreduce程序完成以下功能: 1、 将不同访问日期的访问记录分配给不同的red
相关文章
- Apache系列:Centos7.2下安装与配置apache
- Exception in thread "main" java.lang.UnsupportedClassVersionError: org/apache/maven/cli/MavenCli : Unsupported major.minor version 51.0
- 【异常(待解决)】org.apache.http.NoHttpResponseException: api.weixin.qq.com:443 failed to respond
- Apache中KeepAlive 配置
- yum安装Apache,Mysql,PHP
- 使用 Apache POI 处理 Microsoft Office 文档
- apache fileupload源码分析
- Apache Doris 分析型数据库(一)数据库简介
- maven报错解决:执行mvn package时package org.apache.ibatis.annotations does not exist
- Apache虚拟主机配置
- apache服务器php程序
- swagger 在apache CXF 中的使用——JAX-RS Swagger2Feature
- jetty访问jsp页面出现异常:org.apache.jasper.JasperException: PWC6345: A full JDK (not just JRE) is required解决