
Dubbo实现RPC调用使用入门
使用Dubbo进行远程调用实现服务交互,它支持多种协议,如Hessian、HTTP、RMI、Memcached、Redis、Thrift等等。由于Dubbo将这些协议的实现进行了封装了,无论是服务端(开发服务)还是客户端(调用服务),都不需要关心协议的细节,只需要在配置中指定使用的协议即可,从而保证了服务提供方与服务消费方之间的透明。
另外,如果我们使用Dubbo的服务注册中心组件,这样服务提供方将服务发布到注册的中心,只是将服务的名称暴露给外部,而服务消费方只需要知道注册中心和服务提供方提供的服务名称,就能够透明地调用服务,后面我们会看到具体提供服务和消费服务的配置内容,使得双方之间交互的透明化。
示例场景
我们给出一个示例的应用场景:
服务方提供一个搜索服务,对服务方来说,它基于SolrCloud构建了搜索服务,包含两个集群,ZooKeeper集群和Solr集群,然后在前端通过Nginx来进行反向代理,达到负载均衡的目的。
服务消费方就是调用服务进行查询,给出查询条件(满足Solr的REST-like接口)。
应用设计
基于上面的示例场景,我们打算使用ZooKeeper集群作为服务注册中心。注册中心会暴露给服务提供方和服务消费方,所以注册服务的时候,服务先提供方只需要提供Nginx的地址给注册中心,但是注册中心并不会把这个地址暴露给服务消费方,如图所示:
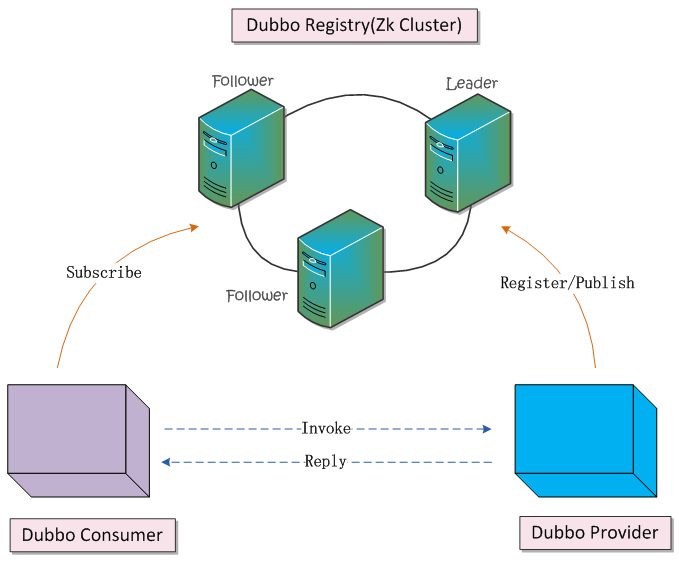
我们先定义一下,通信双方需要使用的接口,如下所示:
package org.shirdrn.platform.dubbo.service.rpc.api;基于上图中的设计,下面我们分别详细说明Provider和Consumer的设计及实现。
Provider服务设计Provider所发布的服务组件,包含了一个SolrCloud集群,在SolrCloud集群前端又加了一个反向代理层,使用Nginx来均衡负载。Provider的搜索服务系统,设计如下图所示:
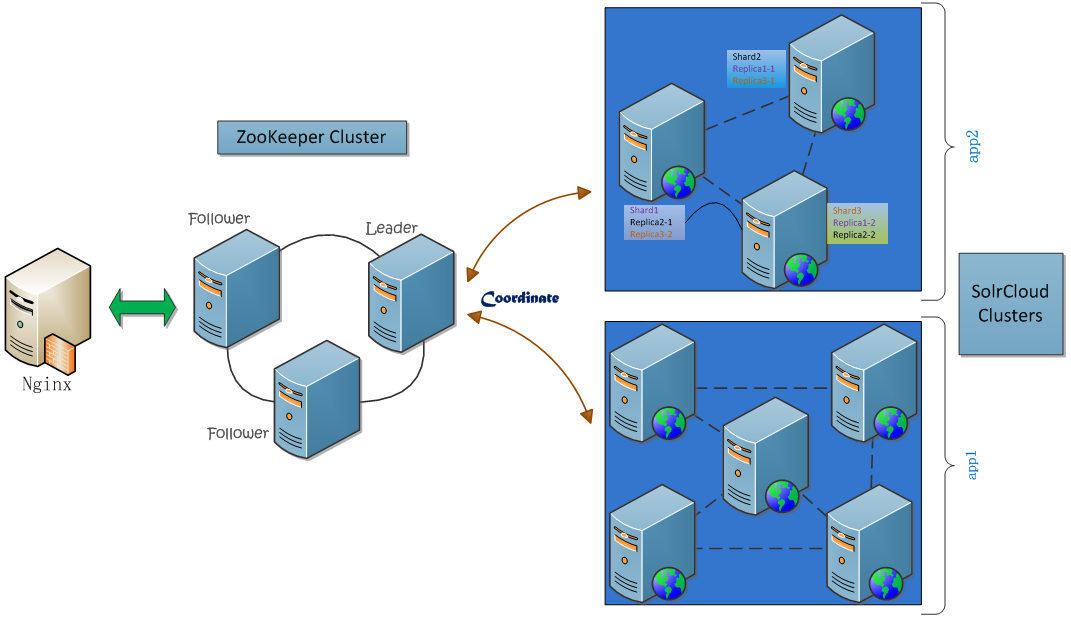
上图中,实际Nginx中将请求直接转发内部的Web Servers上,在这个过程中,使用ZooKeeper来进行协调:从多个分片(Shard)服务器上并行搜索,最后合并结果。我们看一下Nginx配置的内容片段:
user nginx;一共配置了3台Solr服务器,因为SolrCloud集群中每一个节点都可以接收搜索请求,然后由整个集群去并行搜索。最后,我们要通过Dubbo服务框架来基于已有的系统来开发搜索服务,并通过Dubbo的注册中心来发布服务。
首先需要实现服务接口,实现代码如下所示:
private static final Map ResponseType, FormatHandler handlers = newHashMap ResponseType, FormatHandler (0);
String config = SolrSearchServer.class.getPackage().getName().replace(.,/) + "/search-provider.xml";
dubbo:serviceinterface="org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService"ref="searchService" /
上面,Dubbo服务注册中心指定ZooKeeper的地址:zookeeper://slave1:2188?backup=slave3:2188,slave4:2188,使用Dubbo协议。配置服务接口的时候,可以按照Spring的Bean的配置方式来配置,注入需要的内容,我们这里指定了搜索集群的Nginx反向代理地址http://nginx-lbserver/solr-cloud/。
Consumer调用服务设计这个就比较简单了,拷贝服务接口,同时要配置一下Dubbo的配置文件,写个简单的客户端调用就可以实现。客户端实现的Java代码如下所示:
package org.shirdrn.platform.dubbo.service.rpc.client;public SearchConsumer(String collection, Callable AbstractXmlApplicationContext call) {
public Future String asyncCall(final String q, final ResponseType type, final intstart, final int rows) {
public String syncCall(final String q, final ResponseType type, final int start,final int rows) {
private String search(final String q, final ResponseType type, final int start,final int rows) {
final String config = SearchConsumer.class.getPackage().getName().replace(.,/) + "/" + beanXML;
SearchConsumer consumer = new SearchConsumer(collection, newCallable AbstractXmlApplicationContext () {
final AbstractXmlApplicationContext context = newClassPathXmlApplicationContext(config);
查询的时候,需要提供查询字符串,符合Solr语法,例如“q=上海 fl=* fq=building_type:1”。配置文件,我们使用search-consumer.xml,内容如下所示:
?xml version="1.0" encoding="UTF-8"?dubbo:reference id="searchService"interface="org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService" /
运行说明
首先保证服务注册中心的ZooKeeper集群正常运行,然后启动SolrSearchServer,启动的时候直接将服务注册到ZooKeeper集群存储中,可以通过ZooKeeper的客户端脚本来查看注册的服务数据。一切正常以后,可以启动运行客户端SearchConsumer,调用SolrSearchServer所实现的远程搜索服务。
Dubbo调用流程学习总结 首先我们知道Dubbo是一个RPC框架,因此解决的问题是服务治理,这个治理是解决服务注册和调用列表的维护治理,产生注册中心维护服务列表和更新,同时方便远程调用和本地调用是一样的,同时方便解耦,我猜这个是dubbo框架产生的初衷吧。而服务的调用和服务的引用是采用网络编程框架Netty,由于其基于NIO,因此其具有很高的性能。同时因为服务的调用和服务的引用,与IM通信或者我们看到的Http请求三次握手是类似的,采用的是应答模式。
盘古开发框架集成 ShenYu 网关实现 Dubbo 泛化调用 ShenYu 网关基于 Webflex 非阻塞模型通过泛化调用后端 Dubbo 服务。依赖 Netty 不需要 Servlet 容器,不需要引入服务接口包即可通过 Dubbo 泛化调用服务接口的方式就可以将后端 Dubbo 服务转换为 HTTP API。同时网关支持鉴权、动态限流、熔断、防火墙、灰度发布等。
dubbo分布式日志调用链追踪 任何系统都无法100%保证不出错误,线上系统报错之后,首先要做的就是在第一时间内找出问题,解决问题,定位线上问题最主要的途径就是看日志。
分布式RPC服务调用框架选型:使用Dubbo实现分布式服务调用 本文是一篇详细介绍分布式RPC调用框架Dubbo的文章,介绍了Dubbo服务治理和服务调用的实现。分析了Dubbo中的核心功能,包括Remoting,Cluster和RetRegistry的作用和功能。详细说明了Dubbo中几个角色以及各个角色之间的调用关系。通过这篇文章,可以快速了解Dubbo框架的基本面貌和重要原理,为以后更加深入细致的学习RPC调用框架做出准备。
相关文章
- Dubbo 入门
- Nacos Go 微服务生态系列(一)| Dubbo-go 云原生核心引擎探索
- 架构师成长系列 | 从 2019 到 2020,Apache Dubbo 年度回顾与总结
- Dubbo 如何成为连接异构微服务体系的最佳服务开发框架
- Zookeeper+Dubbo+SpringMVC环境搭建
- Dubbo:@DubboService和@Service、@DubboReference和@Reference的区别和关系
- Dubbo项目入门
- 在DockerHub发布Dubbo Admin镜像
- Dubbo调用远程服务详解_导入jar方式
- Docker-compose 安装 zookeeper dubbo-admin
- Dubbo负载均衡算法
- dubbo入门学习
- Zookeeper笔记(四)Zookeeper在Dubbo中的应用