
解决Spark读取tmp结尾的文件报错的问题
2023-09-14 08:57:20 时间
业务场景
flume采集文件到hdfs中,在采集中的文件会添加.tmp后缀。一个批次完成提交后,会将.tmp后缀重名名,将tmp去掉。
所以,当Spark程序读取到该hive外部表映射的路径时,如果恰好这个文件被重命名过,就会出现找不到xxx.tmp文件的问题出现。
解决思路:
Hdfs提供了读取文件筛选的接口PathFilter。
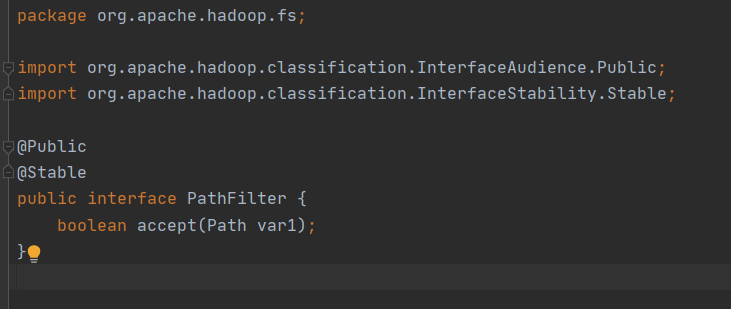
这个接口在hadoop-common包中,所以我们实现这个接口即可。
解决方法:
1.实现PathFilter接口,添加过滤文件后缀的逻辑。
新建了一个项目HdfsFileFilter,在项目中新建了一个类ExcludeTmpFile,如下
package org.apache.hadoop.hdfs;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
/**
* @Author: KingWang
* @Date: 2023/4/13
* @Desc: 解决读取hive外部表时,过滤tmp后缀的文件
**/
class ExcludeTmpFile implements PathFilter {
@Override
public boolean accept(Path path) {
return !path.getName().startsWith("_") && !path.getName().startsWith(".") && !path.getName().endsWith(".tmp");
}
}
在Pom中引入
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.0.0-cdh6.3.1</version>
<scope>compile</scope>
</dependency>
</dependencies>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
2.打包部署
生成的包文件HdfsFileFilter-1.0.0.jar,然后上传到服务器。
我的目录是/home/hadoop/extra-jars/HdfsFileFilter-1.0.0.jar
3. 使用方法
在执行程序中引入包:
spark-shell --master yarn \
--queue root.users.hadoop \
--driver-memory 8G --executor-memory 8G \
--num-executors 50 --executor-cores 2 \
--jars /home/hadoop/extra-jars/HdfsFileFilter-1.0.0.jar \
--conf spark.driver.maxResultSize=20G \
--conf spark.port.maxRetries=16 \
--conf spark.executor.memoryOverhead=5120 \
--conf spark.dynamicAllocation.enabled=false \
--name testSparkShell
在程序中添加以下配置
spark.conf.set("mapred.input.pathFilter.class","org.apache.hadoop.hdfs.ExcludeTmpFile")
相关文章
- excel文件的groovy脚本在SoapUI中进行数据驱动测试
- Laravel 教程:使用Fast Excel解决导出超大 XLSX 文件(千万级)带来的内存问题
- 使用python删除一个文件或文件夹
- 大数据基础之Spark(9)spark部署方式yarn/mesos
- 大叔经验分享(23)spark sql插入表时的文件个数研究
- Apache Spark技术实战(三)利用Spark将json文件导入Cassandra &SparkR的安装及使用
- python处理文件、文件夹-小结
- Hudi(7):Hudi集成Spark之spark-sql方式
- Linux rsync远程文件同步工具:只对差异文件进行更新
- 已解决‘pip‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。
- Python学习57:文件读写
- linux下利用nohup后台运行jar文件包程序
- Linux-ubuntu向windows共享文件
- Spark 以及 spark streaming 核心原理及实践
- Spark读取本地文件时报错:java.io.FileNotFountException:file doesn't exist
- Spring MVC单文件上传(附带实例)