
[Hadoop]chukwa与ganglia的区别
hadoop 区别
2023-09-14 08:56:50 时间
众所周知, hadoop 是运行在分布式的集群环境下,同是是许多用户或者组共享的集群,因此任意时刻都会有很多用户来访问 NN 或者 JT ,对分布式文件系统或者 mapreduce 进行操作,使用集群下的机器来完成他们的存储和计算工作。当使用 hadoop 的用户越来越多时,就会使得集群运维人员很难客观去分析集群当前状况和趋势。比如 NN 的内存会不会在某天不知晓的情况下发生内存溢出,因此就需要用数据来得出 hadoop 当前的运行状况。
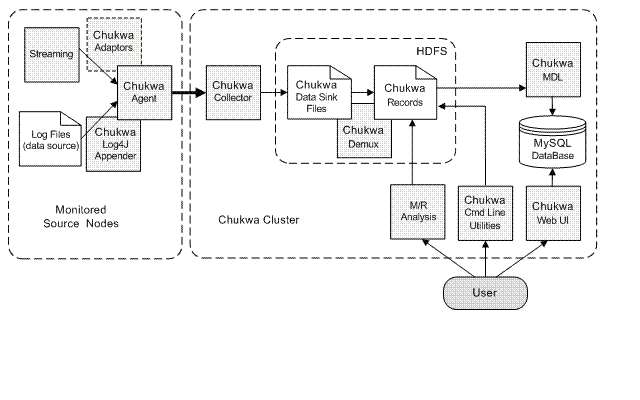
Chukwa 就是利用了集群中的几个进程输出的日志,如 NN,DN,JT,TT 等进程都会有 log 信息,因为这些进程的程序里面都调用 log4j 提供的接口来记录日志,而到底日志的物理存储是由 log4j.properties 的配置文件来配置的,可以写在本地文件,也可以写到数据库。 Chukwa 就是来控制这些日志的记录,由 chukwa 程序来接替这部分工作,完成日志记录和采集工作。 Chukwa 由以下几个组件组成: agent 收集各个进程的日志,并将收集的日志发送给 collector 。 Collector 收集 agent 发送为的数据,同时将这些数据保存到 hdfs 上, MR job 利用 mapreduce 来分析这些数据。 DumpTool 将结果下载保存到 mysql 数据库。 HICC 将数据展现出来。更多信息: http://incubator.apache.org/chukwa/
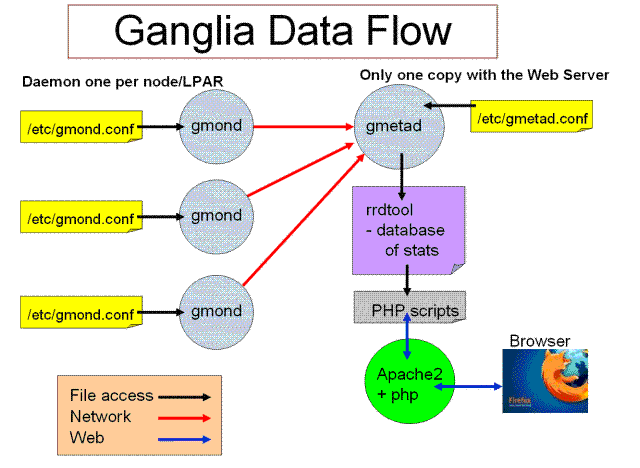
Ganglia 则更偏向于操作系统低层一点的监控,主要是收集集群中的各个机器的 CPU 使用情况,内存使用情况,磁盘 I0, 网络 IO ,磁盘容量等,更像是 windows 的任务管理器,只不过它是管理分布集群机器。类似的,它也由以下组件组成:数据采集组件,每隔一段时间采集一次数据,然后将数据发送给收集器,收集器收集好数据,再将数据保存到数据库,最后一个叫做 rrdtool 通过图形化来展现数据。更值的一提的是, ganglia 更加通用性,除了收集固定的机器性性外,它还提供了相关插件,可以插入到其他进程,如 JAVA 程序,然后可以收集起这些进程的相关信息。
更多信息: http://ganglia.info/
http://www.javabloger.com/article/j2ee-linux-ganglia-rrdtool-java-mysql-1.html
对于深入了解当前平台的状态以及集群中机器的运行情况, chukwa 和 ganglia 无疑是不错的工具,可以用来去得到相关的准确数据,用来知道当前的运行状态,为未来做决策,推断出当前的瓶颈,以及优化相关的应用程序等。
以容器部署Ganglia并监控Hadoop集群 网上有很多Ganglia部署的教程,每一个我都觉得繁琐,我的目的只是用来监控Hadoop测试集群,能即刻使用才是王道,于是我想到通过Rancher部署Ganglia应用服务(类似于我在上一篇文章中部署Jmeter容器集群的方式),以容器的方式一键部署,省去了中间繁琐的安装过程。
Hadoop集群基本部署完成,接下来就需要有一个监控系统,能及时发现性能瓶颈,给故障排除提供有力依据。监控hadoop集群系统好用的比较少,自身感觉ambari比较好用,但不能监控已有的集群环境,挺悲催的。
【原创】ganglia监控hadoop集群 最近研究了一下ganglia监控hadoop集群,大致可以监控hadoop集群中节点的性能。比如CPU、内存、IO、交换分区等。这里就不一一介绍!网上部署监控的文档很多,乱起八糟的也很多,主要是每个人的环境都不一样导致,但是我自己看的还是比较头晕,以至于有的人还直接发布安装脚本,结果可笑的就是脚本拿下来后运行直接报错。
Chukwa 就是利用了集群中的几个进程输出的日志,如 NN,DN,JT,TT 等进程都会有 log 信息,因为这些进程的程序里面都调用 log4j 提供的接口来记录日志,而到底日志的物理存储是由 log4j.properties 的配置文件来配置的,可以写在本地文件,也可以写到数据库。 Chukwa 就是来控制这些日志的记录,由 chukwa 程序来接替这部分工作,完成日志记录和采集工作。 Chukwa 由以下几个组件组成: agent 收集各个进程的日志,并将收集的日志发送给 collector 。 Collector 收集 agent 发送为的数据,同时将这些数据保存到 hdfs 上, MR job 利用 mapreduce 来分析这些数据。 DumpTool 将结果下载保存到 mysql 数据库。 HICC 将数据展现出来。更多信息: http://incubator.apache.org/chukwa/
Ganglia 则更偏向于操作系统低层一点的监控,主要是收集集群中的各个机器的 CPU 使用情况,内存使用情况,磁盘 I0, 网络 IO ,磁盘容量等,更像是 windows 的任务管理器,只不过它是管理分布集群机器。类似的,它也由以下组件组成:数据采集组件,每隔一段时间采集一次数据,然后将数据发送给收集器,收集器收集好数据,再将数据保存到数据库,最后一个叫做 rrdtool 通过图形化来展现数据。更值的一提的是, ganglia 更加通用性,除了收集固定的机器性性外,它还提供了相关插件,可以插入到其他进程,如 JAVA 程序,然后可以收集起这些进程的相关信息。
更多信息: http://ganglia.info/
http://www.javabloger.com/article/j2ee-linux-ganglia-rrdtool-java-mysql-1.html
对于深入了解当前平台的状态以及集群中机器的运行情况, chukwa 和 ganglia 无疑是不错的工具,可以用来去得到相关的准确数据,用来知道当前的运行状态,为未来做决策,推断出当前的瓶颈,以及优化相关的应用程序等。
以容器部署Ganglia并监控Hadoop集群 网上有很多Ganglia部署的教程,每一个我都觉得繁琐,我的目的只是用来监控Hadoop测试集群,能即刻使用才是王道,于是我想到通过Rancher部署Ganglia应用服务(类似于我在上一篇文章中部署Jmeter容器集群的方式),以容器的方式一键部署,省去了中间繁琐的安装过程。
Hadoop集群基本部署完成,接下来就需要有一个监控系统,能及时发现性能瓶颈,给故障排除提供有力依据。监控hadoop集群系统好用的比较少,自身感觉ambari比较好用,但不能监控已有的集群环境,挺悲催的。
【原创】ganglia监控hadoop集群 最近研究了一下ganglia监控hadoop集群,大致可以监控hadoop集群中节点的性能。比如CPU、内存、IO、交换分区等。这里就不一一介绍!网上部署监控的文档很多,乱起八糟的也很多,主要是每个人的环境都不一样导致,但是我自己看的还是比较头晕,以至于有的人还直接发布安装脚本,结果可笑的就是脚本拿下来后运行直接报错。
相关文章
- Hadoop、spark、hive到底是什么,做算法要不要学?
- hadoop生态圈详解
- Hadoop之hdfs体系结构
- Spark和Hadoop的区别和比较[通俗易懂]
- 一文搞懂hadoop的metrics
- hadoop学习之hadoop2.8.0完全分布式集群安装详解大数据
- Maven引入Hadoop依赖报错:Missing artifact jdk.tools:jdk.tools:jar:1.6详解大数据
- spark和hadoop的区别详解大数据
- 程序员必须要知道的Hadoop的12个事实详解大数据
- Hadoop2源码分析-Hadoop V2初识详解大数据
- 配置高可用的Hadoop平台详解大数据
- hadoop家族成员详解大数据
- reduce hadoop利用MySQL、MapReduce、Hadoop轻松解决大数据问题(mysqlmap)
- Linux系统下安装配置Hadoop(linux下安装hadoop)
- Hadoop入门扫盲:hadoop发行版介绍与选择
- 实现R与Hadoop联合作业的三种方法
- 利用Hadoop搭建MySQL数据库存储系统(hadoop和mysql)
- Hadoop与MySQL联合打造大数据分析平台(hadoop与mysql)
- Hadoop与MySQL技术协同打造大数据完美解决方案(hadoopmysql)