
【H2O系列】H2O概述
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。
- 推荐:kuan 的首页,持续学习,不断总结,共同进步,活到老学到老
- 导航
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨

博客目录
一、下载并安装
1.h2o 介绍
H2O 概述:开源,分布式内存机器学习平台
为了社会和经济稳定,让每个人都可以使用 AI 非常重要
H2O 的核心代码是用 Java 编写的,它的 REST API 允许从外部程序或脚本访问 H2O 的所有功能。该平台包括用于 R,Python,Scala,Java,JSON 和 CoffeeScript / JavaScript 的接口,以及内置的 Web 界面 Flow
最新的版本叫做H2O-3 是 H2O 的第三个化身,并与 Hadoop 和 Spark 等大数据技术无缝协作。 H2O 可以通过更快,更好的预测建模,轻松快速地从数据中获取洞察力。
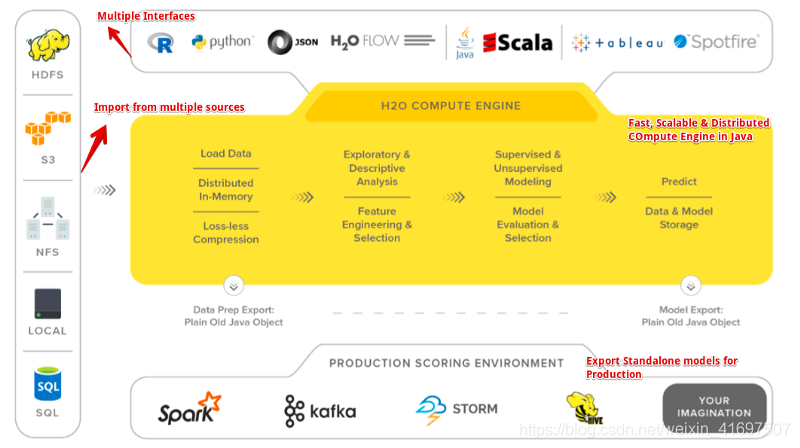
一个简单方便的建模工具,提供多种接入方式.java ,python 等客户端.还有一个 h2o-flow 的可视化界面
cluster是一组一起工作的 H2O 节点; 将作业提交到群集时,群集中的所有节点都会处理作业的一部分。
h2o 包括很多产品,h2o flow 是其中一款便利的机器学习,深度学习的工具,在 web UI 上操作即可,不用编写代码就能轻松实现数据的挖掘(当然这也是它的弊端,不写代码肯定功能会受到一定的限制啦)。
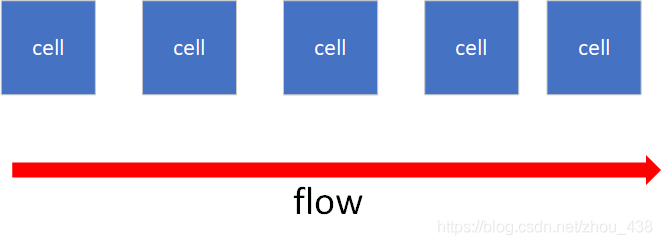
对于 flow 的意思就是流的意思,其实 h2o flow 的核心思想就是分成若干个 cell(细胞),然后 cell 按照先后顺序进行 flow。
2.架构图


3.gitee 地址
https://gitee.com/mirrors/h2o-dev
4.部署 demo
https://h2o-release.s3.amazonaws.com/h2o/rel-zipf/7/index.html
5.Windows 启动
cd /h2o-dev
gradlew.bat build -x test //拉取前端代码
java -jar build/h2o.jar
6.访问链接
http://localhost:54321/
二、web UI 页面介绍
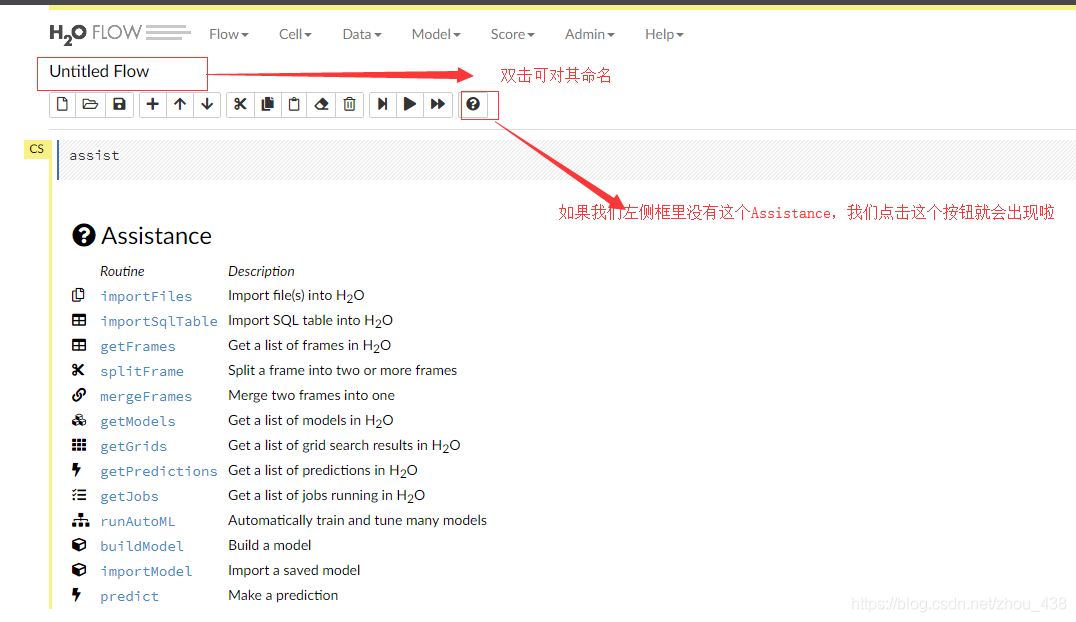
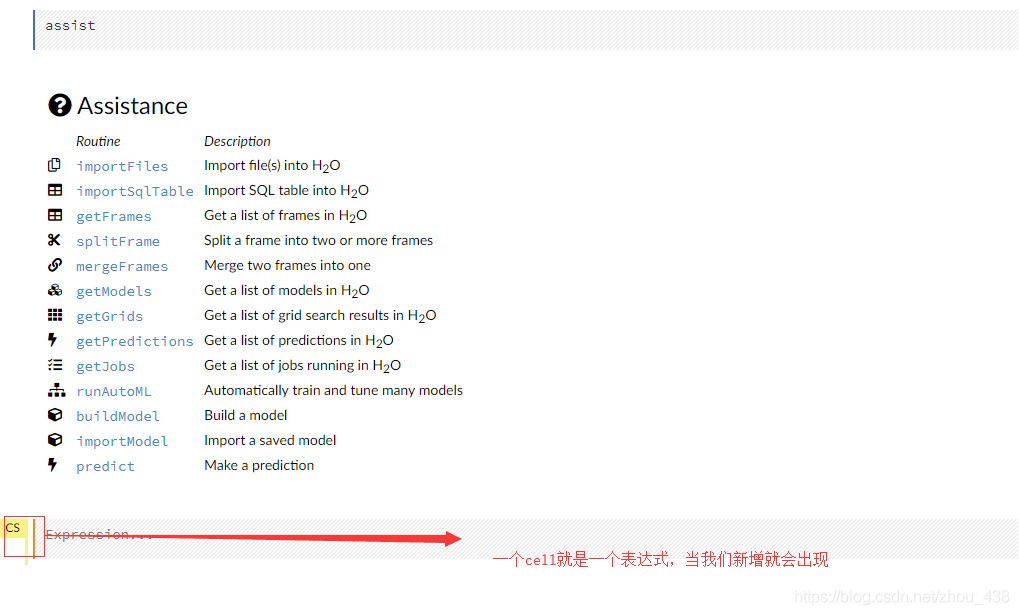
1.cell 介绍
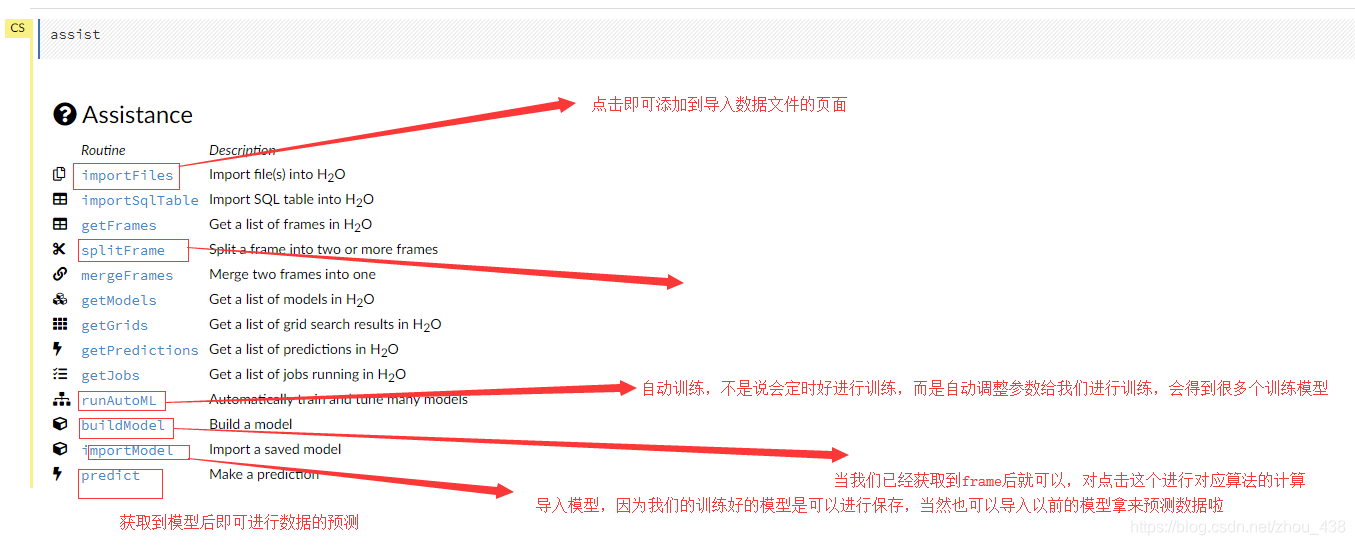
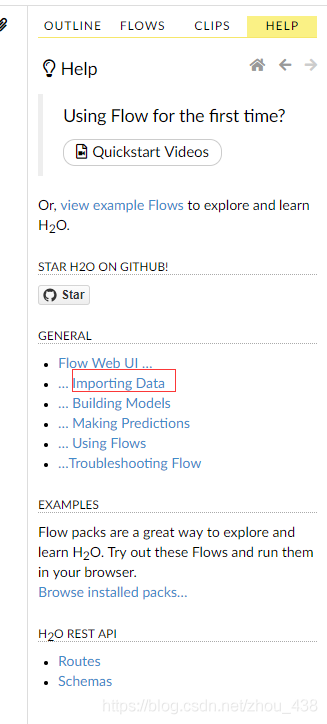
2.help 介绍使用
我们还可以在这里找到官方提供成操作案例是非常详细的(在 web 的右侧)
就会来到这个页面,发现提供了几乎我们用得上的算法实践
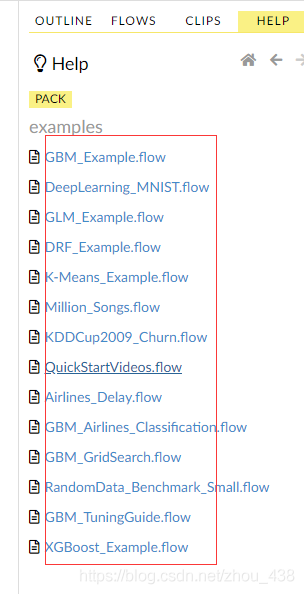
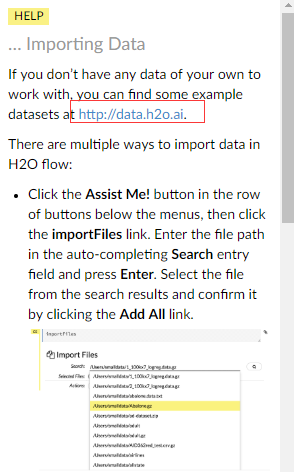
点击这个来到导入数据的页面(我们也可以看到我们进行数据挖掘的流程刚好是导入数据,建立模型,预测。发现文档顺序也是这样是),我们可以看到
人家给我们说了,实践用到的数据基本上都可以在这个网站上进行下载,个别不是,这不影响,因为对应的 example 会提供
3.操作按钮
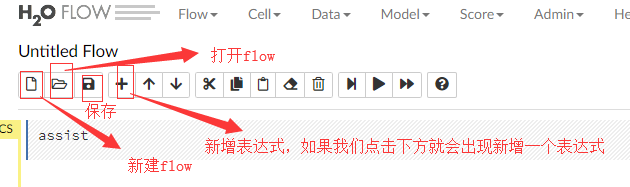

4.支持的文件
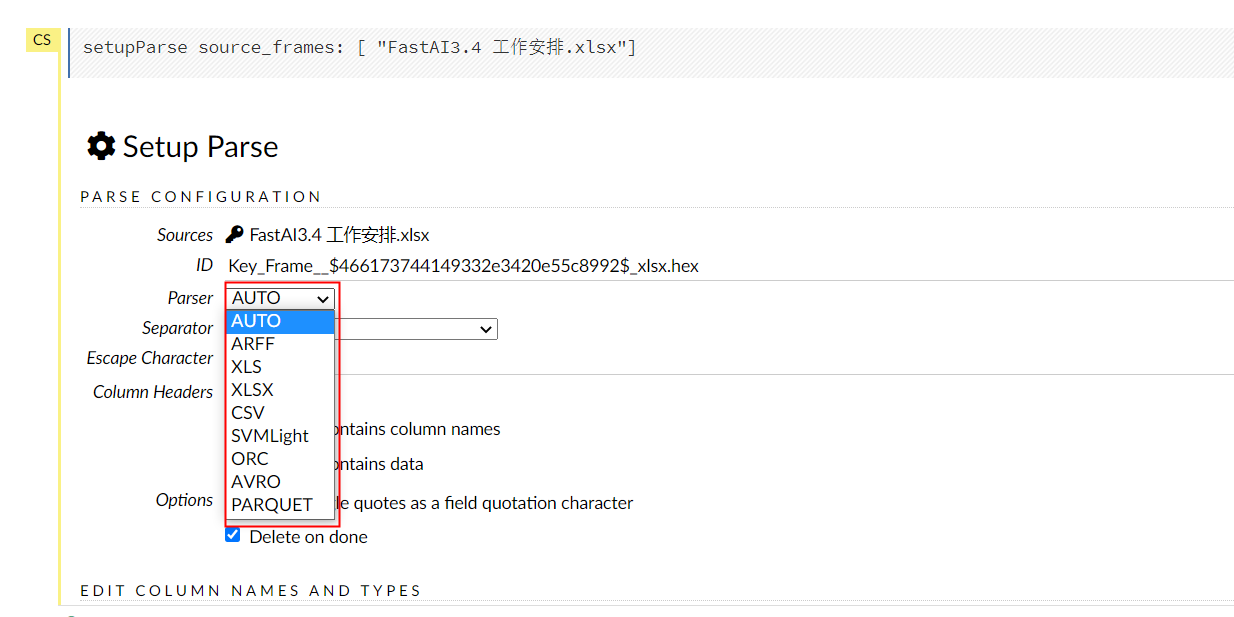
5.总结
- 使用界面如下,类似于 zeppelin 的使用风格.
- java -jar h2o.jar [各种参数] ,内置了 jetty 服务,直接用 java -jar 就可以启动.然后访问端口为 54321.
- flow 的方式不能对数据做处理,需要将数据提前处理好.
- 对中文的支持不是很好.显示乱码.主要是中文是双字节的,h2o 有自己的数据结构(hex).hex 是对单字节的处理.修改下源码即可.
- h2o 可以直接读取 hdfs (hdfs://…),本地等数据.对于文件格式的支持有 text,csv,parquet 等.orc 的格式需要以 hadoop 集群的方式启动,才能使用.
- 对 parquet 格式的支持有 timestamp int96 的问题.这个问题主要是 parquet 项目中 timestamp 使用的类型是 int96 造成的.spark,drill 等项目也会遇到这个问题.但是都各自解决掉了.参照 spark 的修改方式.也可以修改.
- h2o 集群的部署,有三种部署方式,一种是 jvm 进程组建 standalone 集群.另外两种借助 hadoop 实现分布式集群.
- standalone 集群方式中,没有 HA,其中一台坏掉了这个集群就坏掉了.
- standalone 集群也会有通信问题,在不使用多长时间后这个集群会因为监听心态通信不成功而 down 掉.(这个问题没有解决),可能是 ipv6 的问题.
- 使用方式很简单,按照 notebook 的方式引用数据,选择模型类型.很快就能看到各个模型的指标了.
- h2o 中文社区我是没有找到.整个社区也不是很活跃.
三、实践一下模型
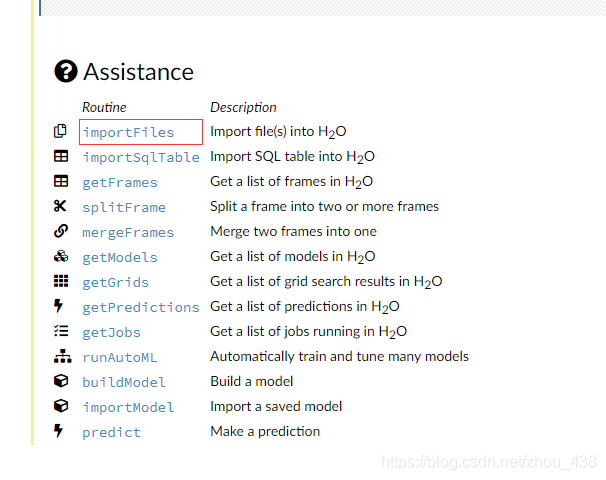
1.导入数据
导入数据很简单,我们可以点击:
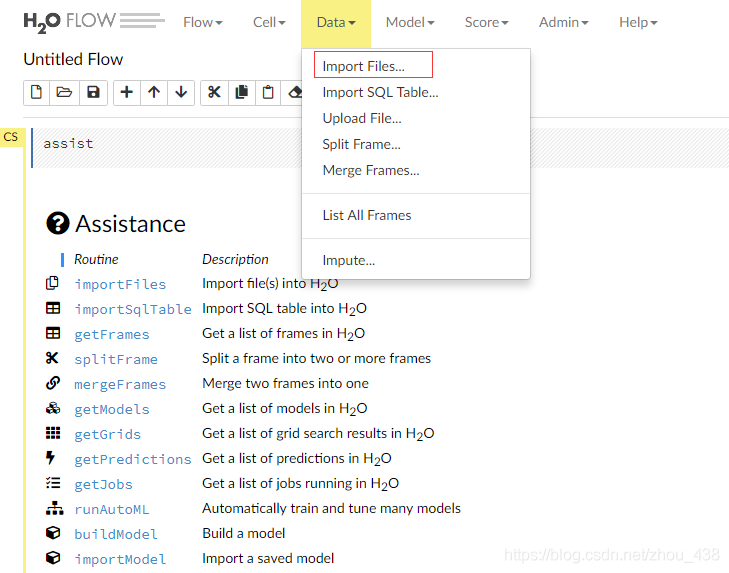

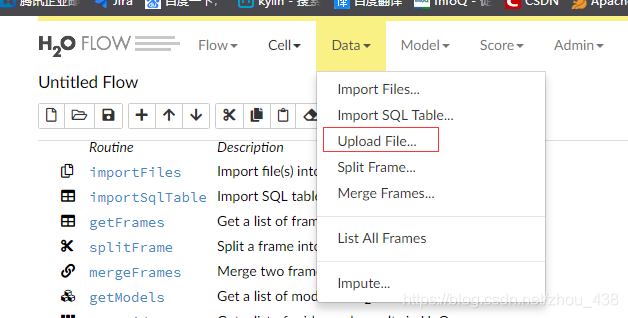
2.格式转换
将数据转变成统一的格式(.hex)
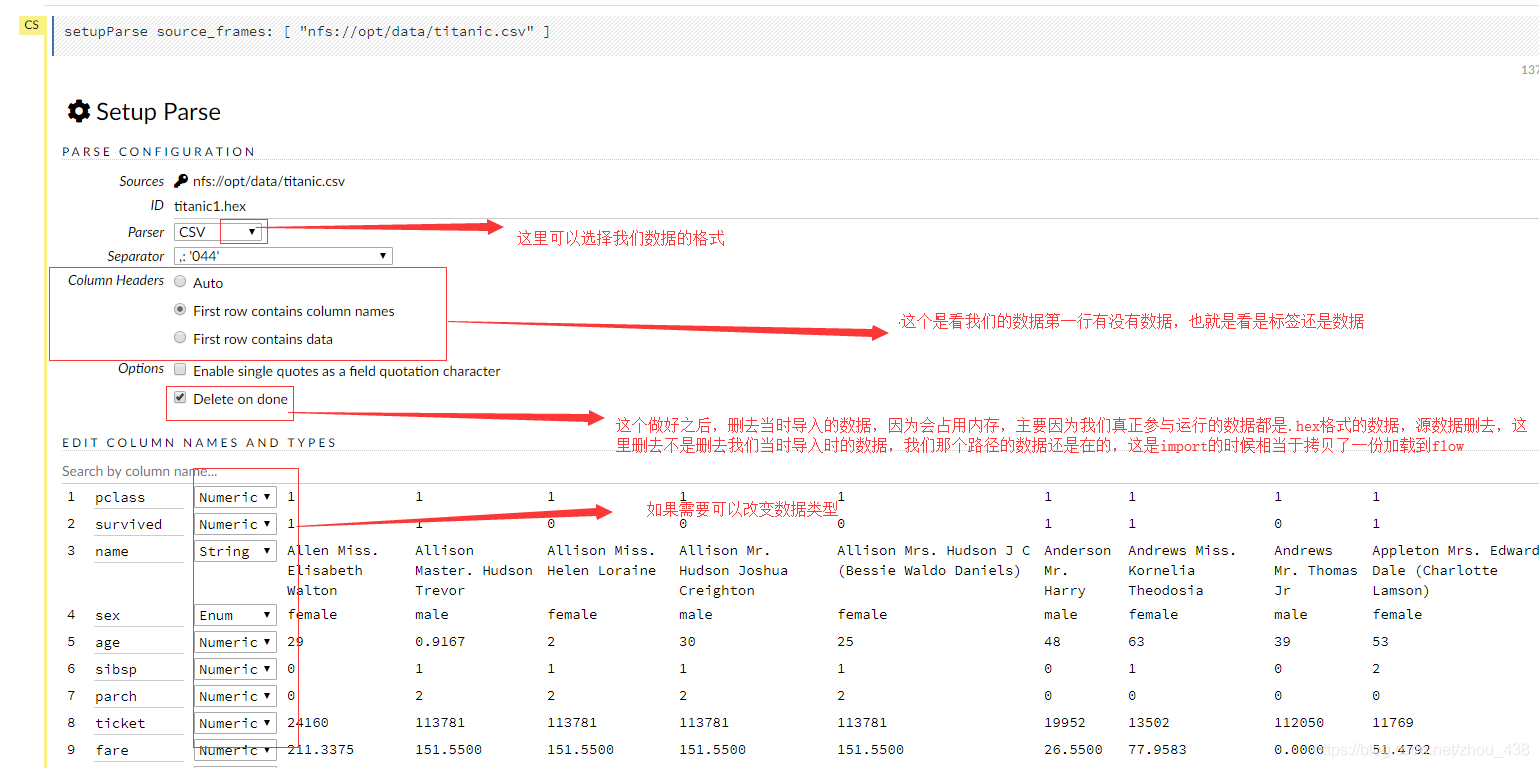
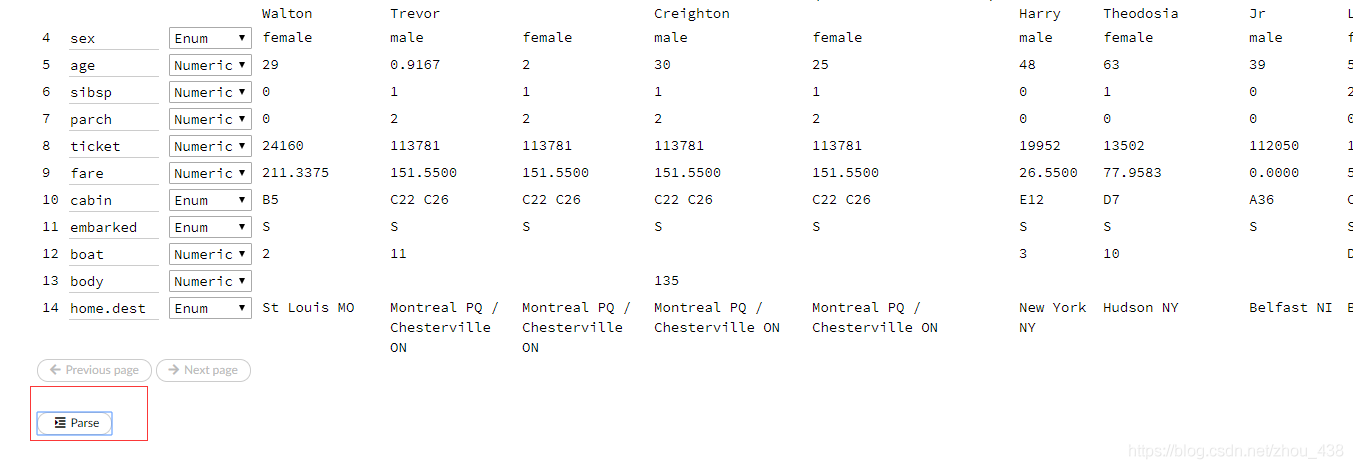

3.数据切分
(这一步有就切分,没有就不用啦,因为有的时候数据是需要我们切分成 train 和 test,有的时候本来就停供了两个文件,当然我们就不用切分了)
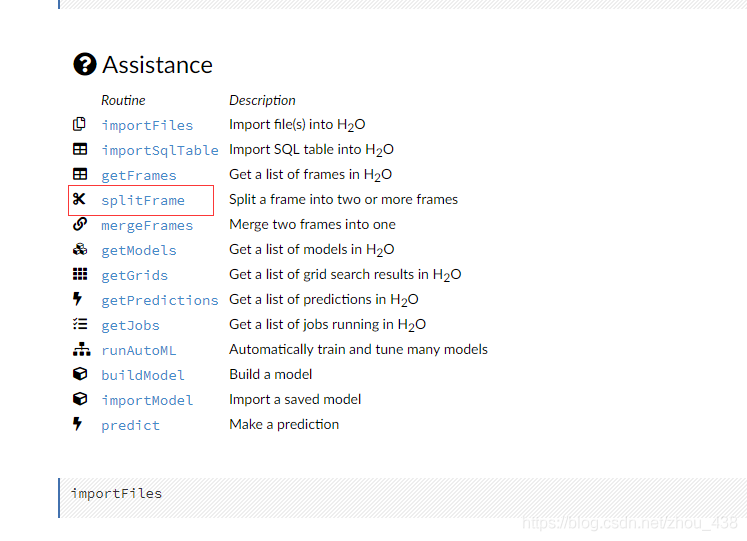
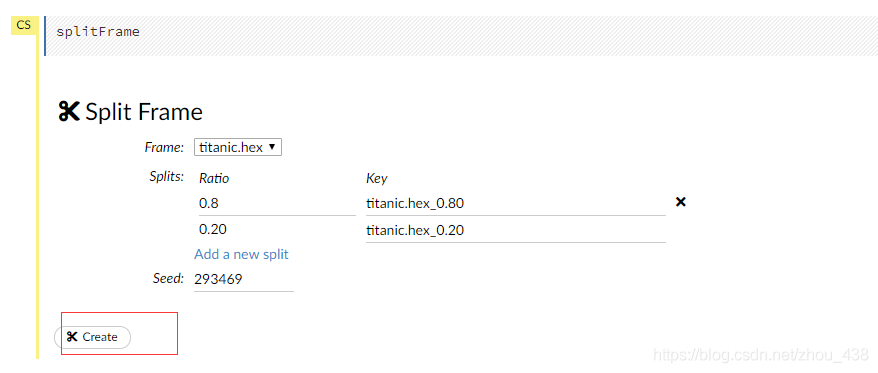

4.训练模型
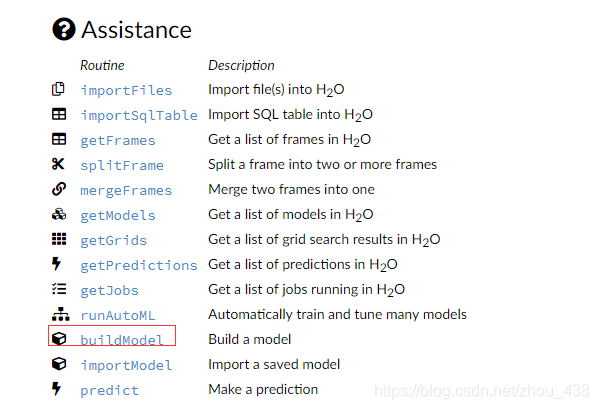
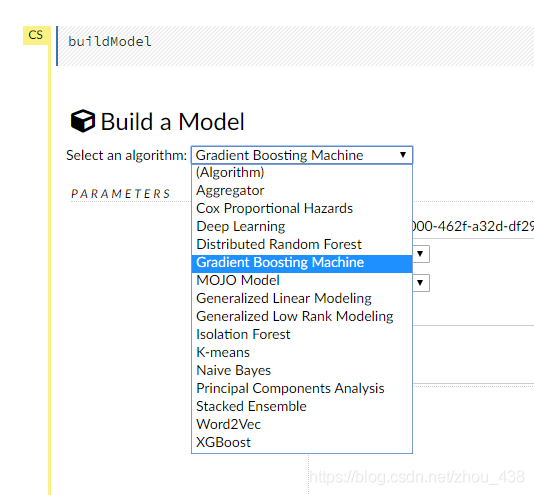
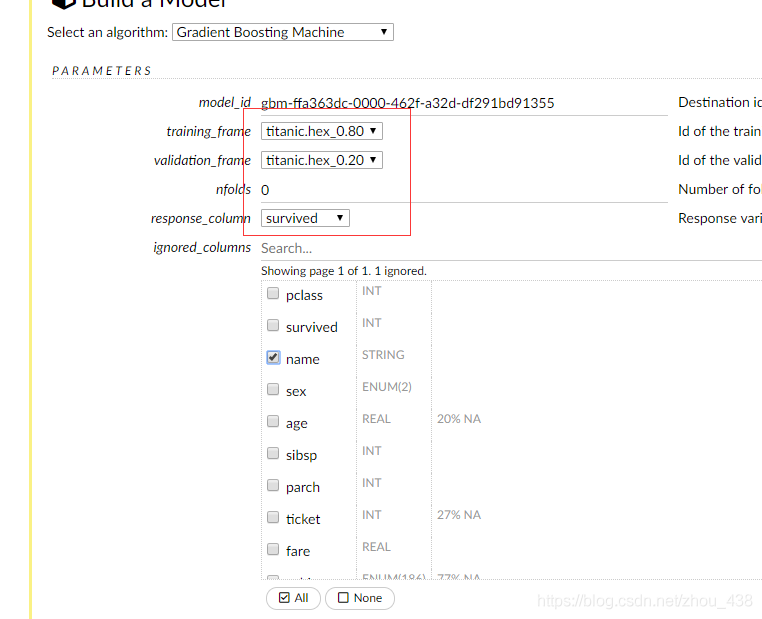
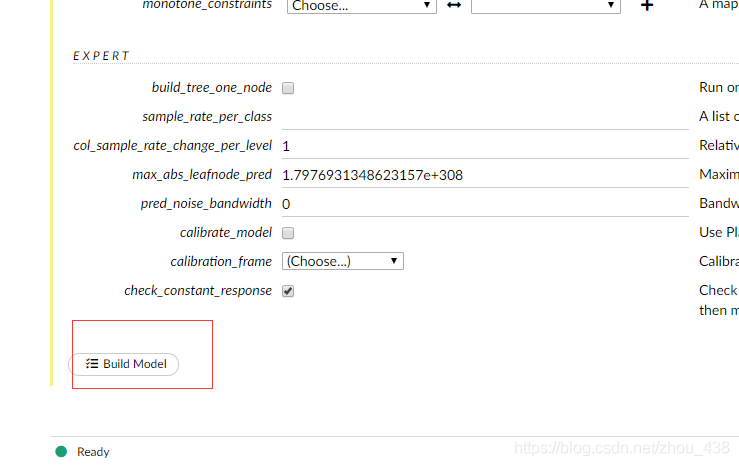
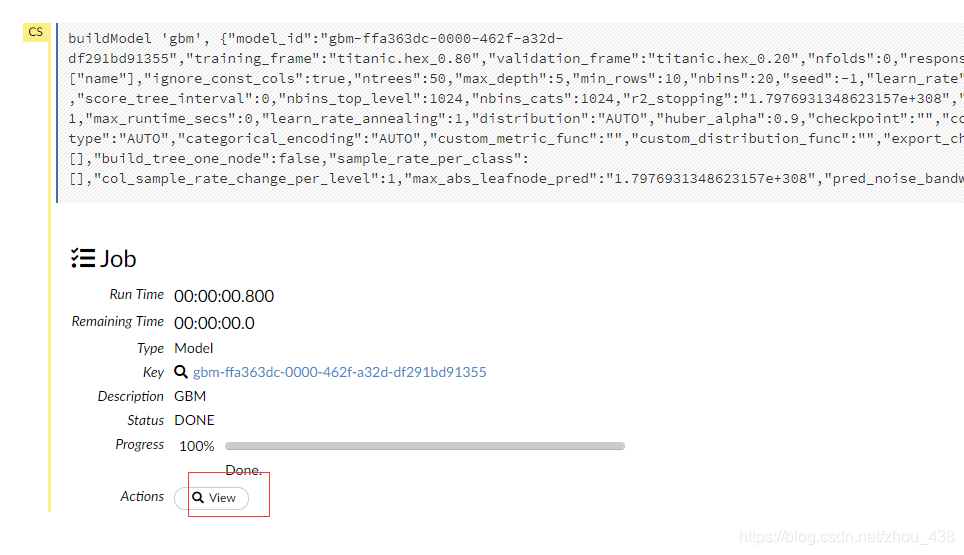
5.预测模型
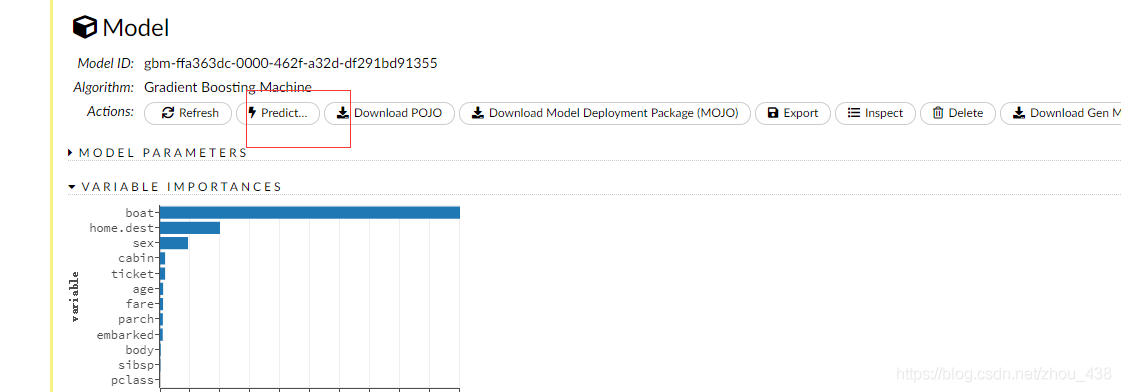
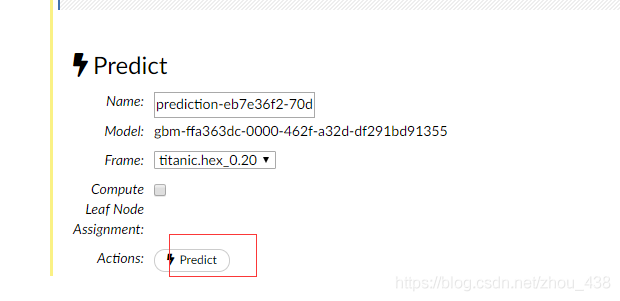
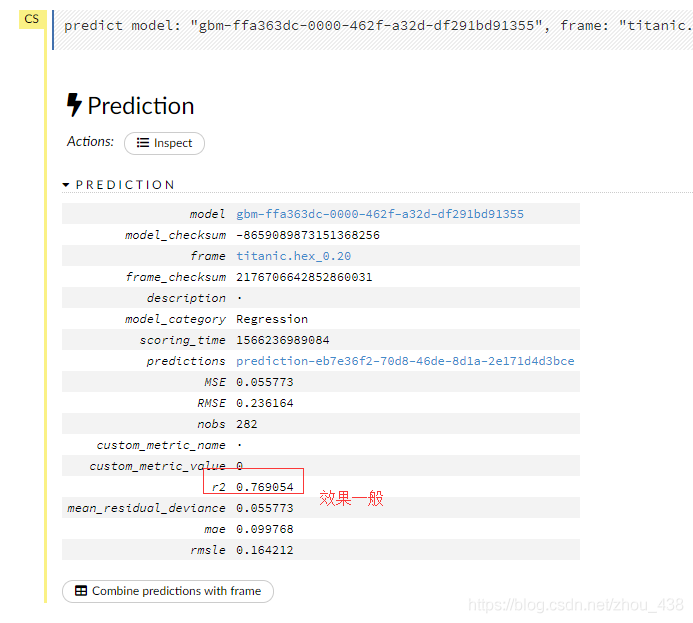
h2o flow 对每一种算法都停供了不同的数据图表,这里演示我用的 gbm,所以图不是没那么多。
四、补充
1.超参数
h2o flow 给我们提供了便利的使用超参数,只需要想建立模型的时候勾选上既可以,比如:

然后进行勾选

我们进行添加几个数据作为超参数

于是我们建立模型后就多出来几个模型,这就是不同的超参数对应的模型

我们在建立模型的参数上看到超参数

2.查看集群状态

因为我是单机模式,所以只有一个

3.关闭服务

4.列出所有模型


五.源码理解
1.处理请求
CoreServletProvider
private static final List<ServletMeta> SERVLETS = Collections.unmodifiableList(Arrays.asList(
new ServletMeta("/3/NodePersistentStorage.bin/*", NpsBinServlet.class),
new ServletMeta("/3/PostFile.bin", PostFileServlet.class),
new ServletMeta("/3/PostFile", PostFileServlet.class),
new ServletMeta("/3/DownloadDataset", DatasetServlet.class),
new ServletMeta("/3/DownloadDataset.bin", DatasetServlet.class),
new ServletMeta("/3/PutKey.bin", PutKeyServlet.class),
new ServletMeta("/3/PutKey", PutKeyServlet.class),
new ServletMeta("/", RequestServer.class)
));
2.源码解读

六.分布式部署
部署方式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tUPVj1qm-1637328322130)(C:/Users/Administrator/AppData/Roaming/Typora/typora-user-images/image-20210908105746844.png)]
- xgb xgboost 部署
- k8s
- hadoop
- docker
- EC2 aws 服务器部署
- Dockerfile.dev
觉得有用的话点个赞 👍🏻 呗。
❤️❤️❤️本人水平有限,如有纰漏,欢迎各位大佬评论批评指正!😄😄😄
💘💘💘如果觉得这篇文对你有帮助的话,也请给个点赞、收藏下吧,非常感谢!👍 👍 👍
🔥🔥🔥Stay Hungry Stay Foolish 道阻且长,行则将至,让我们一起加油吧!🌙🌙🌙

相关文章
- 车载诊断系列——车辆诊断 UDS 协议概述
- netty系列之:搭建客户端使用http1.1的方式连接http2服务器
- 大型网站架构系列:电商网站架构案例
- Android应用程序管理系列(一)——管理对象封装概述
- 微服务技术系列教程(14) - SpringBoot - 实现原理
- SCL项目:在Red Hat系列系统上安装同一软件的不同版本
- 【深度学习之美】一入侯门“深”似海,深度学习深几许(入门系列之一)
- ASM 翻译系列第五弹:高级知识 ASM 元数据概述
- Java NIO系列教程(二) Channel
- 汇川触摸屏IT7000E和汇川中小型系列PLC连接及MW寄存器说明
- 委托、Lambda表达式、事件系列05,Action委托与闭包
- netty系列之:netty架构概述
- 外设驱动库开发笔记10:SHT2x系列温湿度传感器驱动
- Dubbo系列_概述