
MySQL:索引的底层实现 | 聚集索引和非聚集索引 | 自适应哈希索引
前言
数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘块(对应索引树的节点),索引树越低,越“矮胖”,磁盘IO次数就少。
两种索引结构
MySQL支持两种索引,一种是B-树索引,一种是哈希索引,大家知道,B-树和哈希表在数据查询时的效率是非常高的。
这里我们主要讨论一下MySQL InnoDB存储引擎,基于B-树(但实际上MySQL采用的是B+树结构)的索引结构。
B-树是一种m阶平衡树,叶子节点都在同一层,由于每一个节点存储的数据量比较大,索引整个B-树的层数是非常低的,基本上不超过三层。
由于磁盘的读取也是按block块操作的(内存是按page页面操作的),因此B-树的节点大小一般设置为和磁盘块大小一致,这样一个B-树节点,就可以通过一次磁盘I/O把一个磁盘块的数据全部存储下来,所以当使用B-树存储索引的时候,磁盘I/O的操作次数是最少的(MySQL的读写效率,主要集中在磁盘I/O上)。
B-树
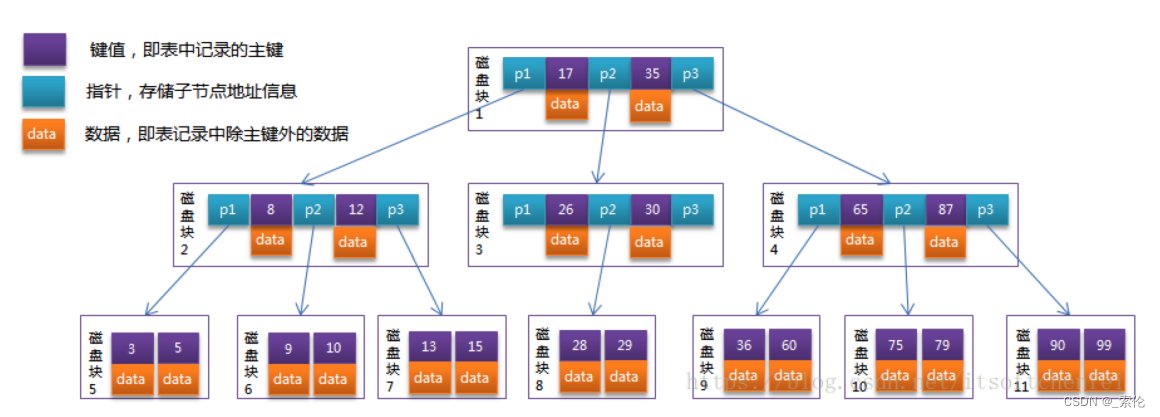
如图:
-
索引和数据分散在不同的节点上,离根节点近,搜索就快;离根节点远搜索就慢,花费的磁盘I/O次数不平均,每一行数据搜索花费得到时间也不平均。
-
每一个非叶子节点上,不仅仅要存储索引(key),还要存储索引值所在的那一行的数据。一个节点所能存放的索引key值得个数,比只存储key值得节点的个数要少的多。
-
这棵树不方便做范围搜索,整表遍历看起来也不方便。
B+树
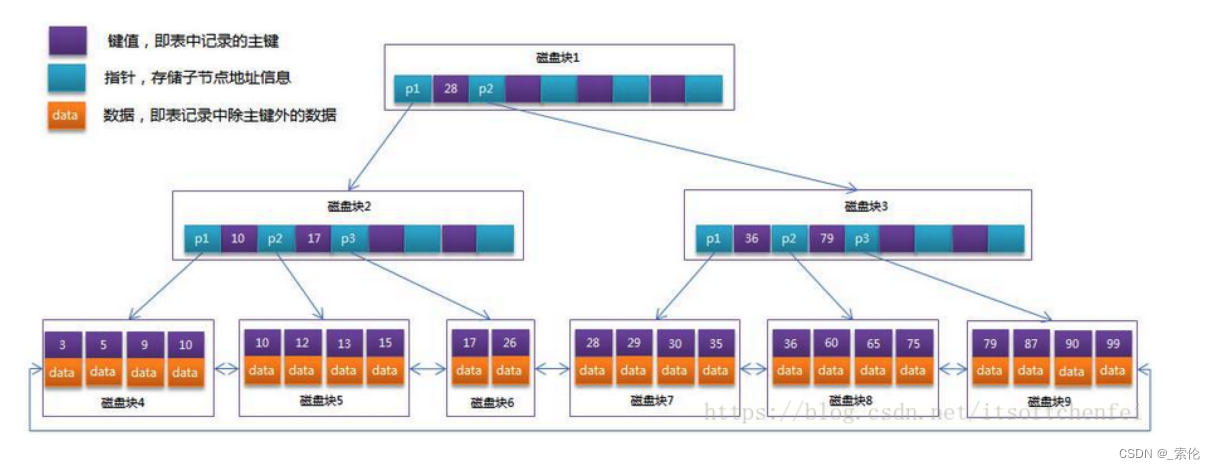
如图:
- 每个非叶子节点只存放key,不存放data。好处就是每个节点存放的key更多,B+树理论上来说,层数会更低一些,搜索的效率会更好一些。
- 叶子节点上存储了所有索引值对应的数据data:那么搜索每一个索引对应的数据,都需要跑到叶子节点上,这样每一行记录的搜索时间非常平均。
- 叶子节点被串在一个链表上,有序链表,如果要进行索引树的搜索 & 整表搜索,或做范围查询时,直接遍历叶子节点的链表即可。
不同之处
面试题:
那么MySQL最终为什么要采用B+树存储索引结构呢,那么看看B-树和B+树在存储结构上有什么不同?
- B-树的每一个节点,存了关键字和对应的数据地址,而B+树的非叶子节点只存关键字,不存数据地址。因此B+树的每一个非叶子节点存储的关键字是远远多于B-树的,B+树的叶子节点存放关键字和数据,因此,从树的高度上来说,B+树的高度要小于B-树,使用的磁盘I/O次数少,因此查询会更快一些。
- B-树由于每个节点都存储关键字和数据,因此离根节点进的数据,查询的就快,离根节点远的数
据,查询的就慢;B+树所有的数据都存在叶子节点上,因此在B+树上搜索关键字,找到对应数据的时间是比较平均的,没有快慢之分。 - 在B-树上如果做区间查找,遍历的节点是非常多的;B+树所有叶子节点被连接成了有序链表结
构,因此做整表遍历和区间查找是非常容易的。
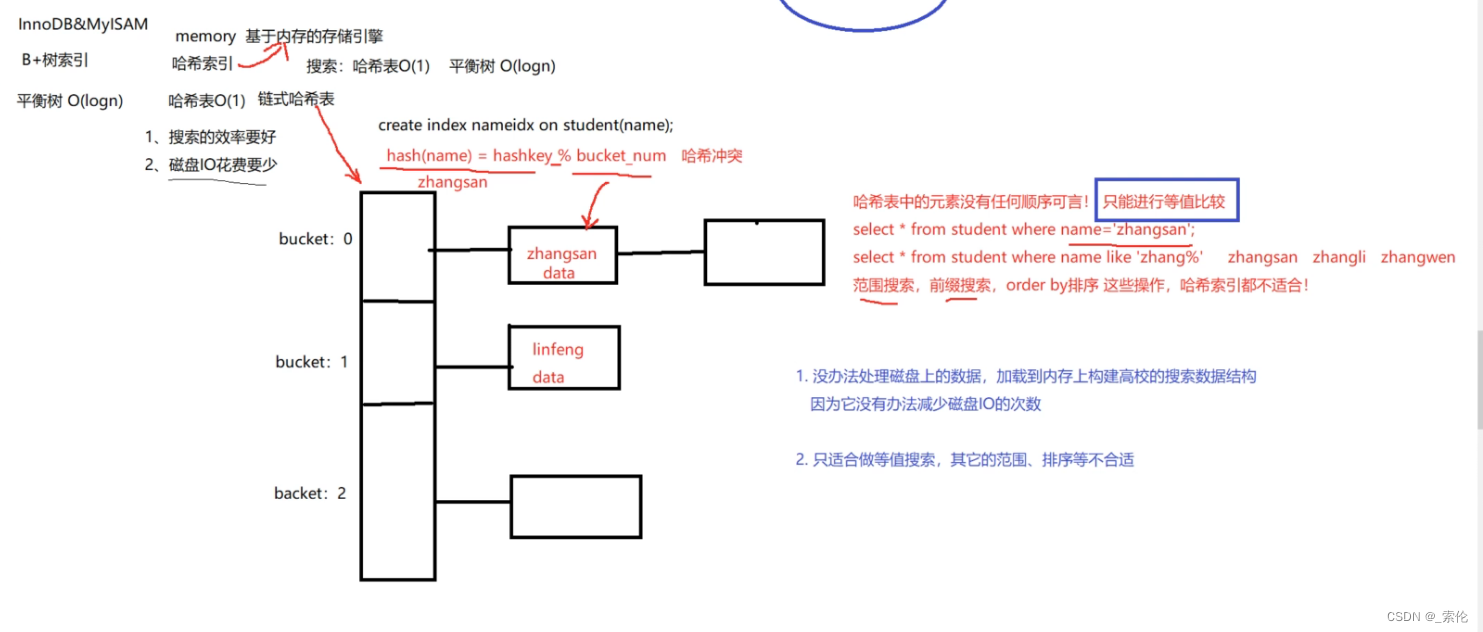
哈希索引当然是由哈希表实现的,哈希表对数据并不排序,因此不适合做区间查找,效率非常低,需要搜索整个哈希表结构。
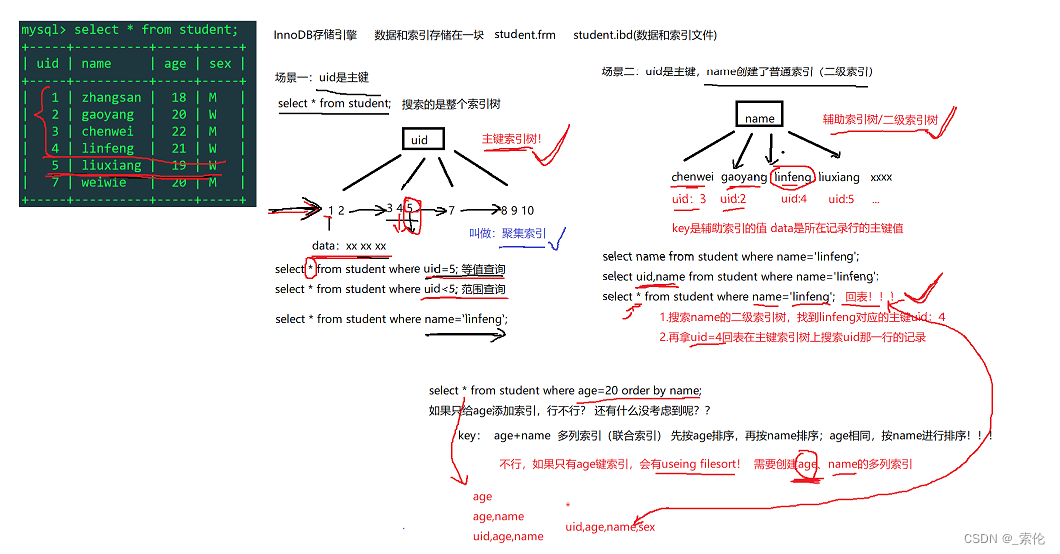
InnoDB的聚集索引
主键索引
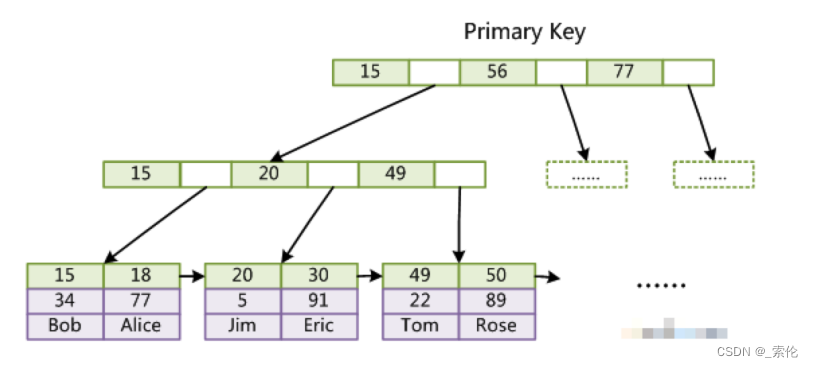
InnoDB存储引擎的主键索引,叶子节点中,索引关键字和数据是在一起存放的,如图:
辅助索引
InnoDB的辅助索引,叶子节点上存放的是索引关键字和对应的主键,如图:
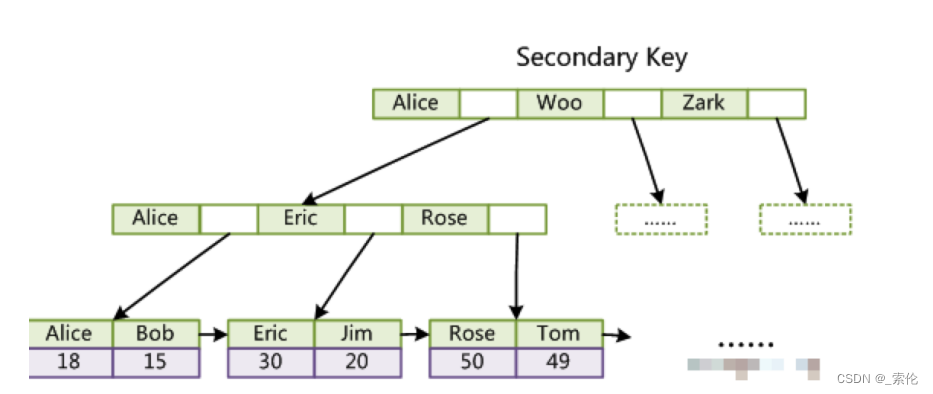
辅助索引的B+树,先根据关键字找到对应的主键,再去主键索引树上找到对应的行记录数据。
从索引树上可以看到,InnoDB的索引关键字和数据都是在一起存放的,体现在磁盘存储上,例如创建一个user表,在磁盘上只存储两种文件,user.frm(存储表的结构),user.ibd(存储索引和数据)。
InnoDB的索引树叶节点包含了完整的数据记录,这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(区别于MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
MyISAM的非聚集索引
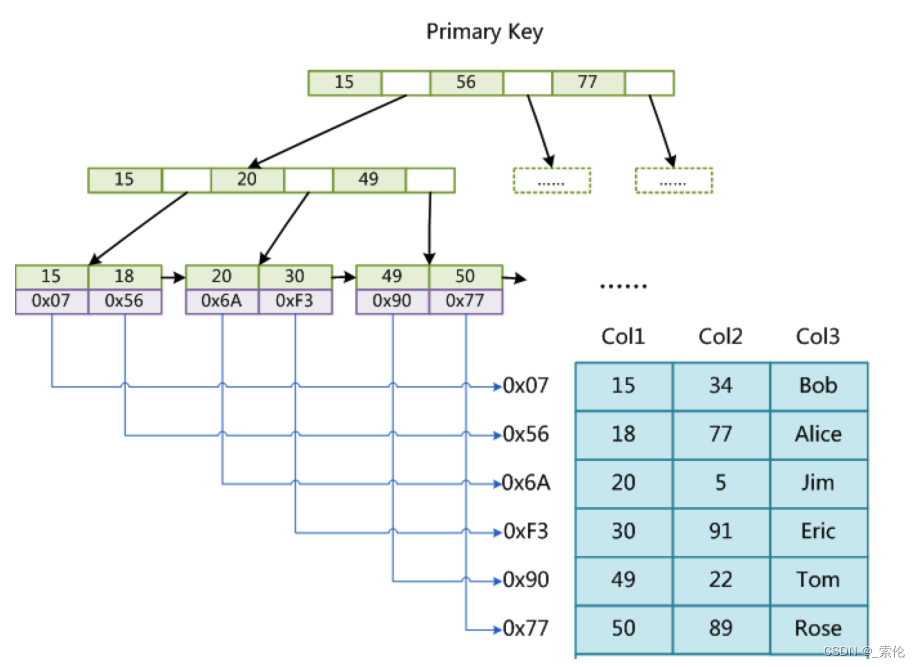
主键索引
MyISAM引擎使用B+树作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM主键索引的原理图:
辅助索引
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复,如果给其它字段创建辅助索引,结构图如下:
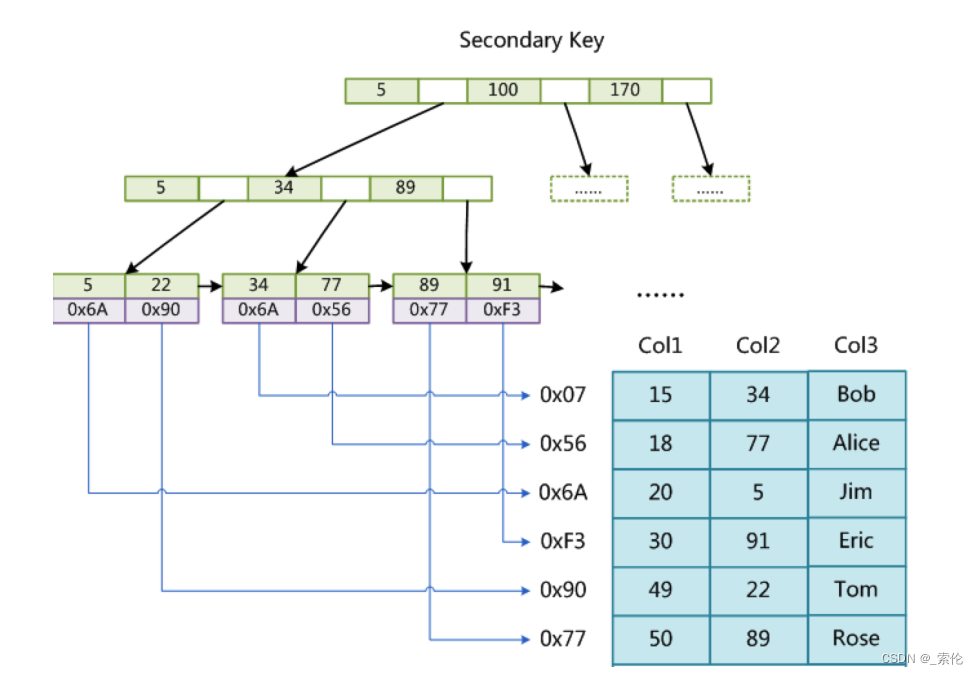
根据上面两张图,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
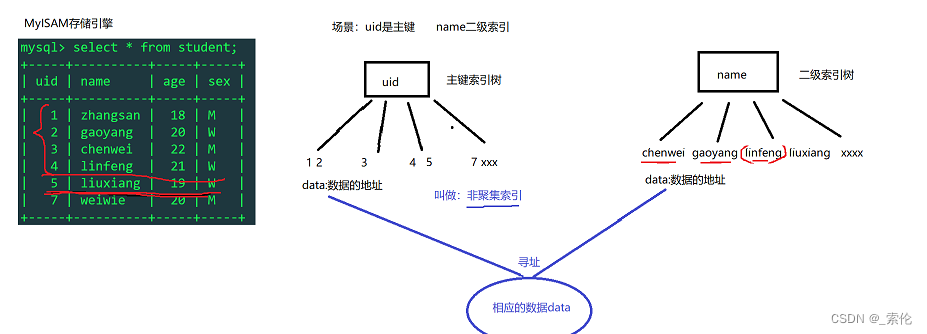
可以看到,MyISAM存储引擎,索引结构叶子节点存储关键字和数据地址,也就是说索引关键字和数据没有在一起存放,体现在磁盘上,就是索引在一个文件存储,数据在另一个文件存储,例如一个user表,会在磁盘上存储三个文件 user.frm(表结构文件) user.MYD(表的数据文件) user.MYI(表的索引文件)。
MyISAM的索引方式也叫做非聚集索引。
抽象图示:
哈希索引
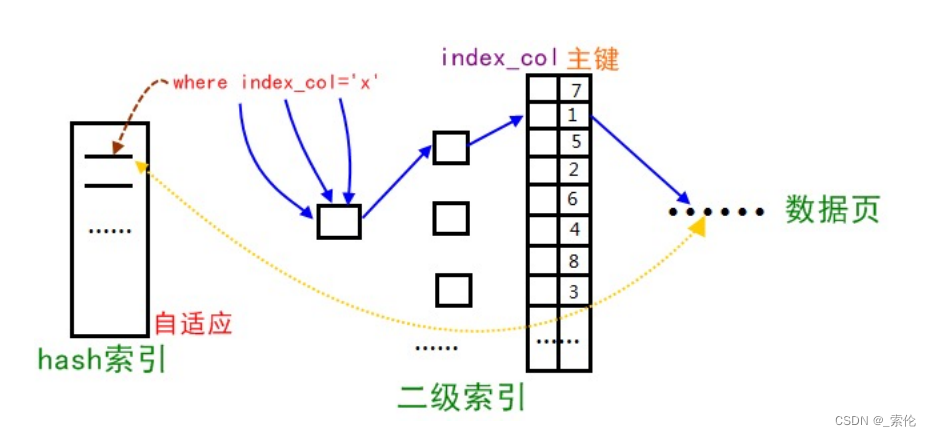
InnoDB的自适应哈希索引
In MySQL 5.7, the adaptive hash index search system is partitioned. Each index is bound to a
specific partition, and each partition is protected by a separate latch.
Partitioning is controlled by the innodb_adaptive_hash_index_parts configuration option. In
earlier releases, the adaptive hash index search system was protected by a single latch which
could become a point of contention under heavy workloads. The
innodb_adaptive_hash_index_parts option is set to 8 by default.
The maximum setting is 512.
The hash index is always built based on an existing B-tree index on the table. InnoDB can build a
hash index on a prefix of any length of the key defined for the B-tree,
depending on the pattern of searches that InnoDB observes for the B-tree index. A hash index
can be partial, covering only those pages of the index that are often accessed.
You can monitor the use of the adaptive hash index and the contention for its use in the
SEMAPHORES section of the output of the SHOW ENGINE INNODB STATUS command. If you see
many threads waiting on an RW-latch created in btr0sea.c, then it might be useful to disable
adaptive hash indexing.
如果InnoDB存储引擎检测到同样的二级索引不断被使用,那么它会根据这个二级索引,在内存上根据二级索引树的二级索引值,在内存上构建一个哈希索引,以达到加速搜索。
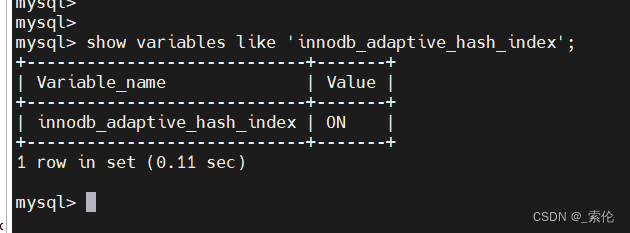
使用命令来查看
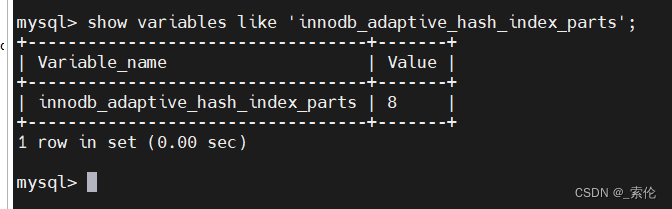
自适应哈希索引的数据维护也是要消耗性能的,并不是说自适应哈希索引在任何情况下都会提升二级索引的查询性能。根据参数指标,来具体分析打开或关闭自适应哈希索引。

相关文章
- 【MySQL从入门到精通】【高级篇】(十一)Hash索引、AVL树、B树与B+树对比
- 【MySQL从入门到精通】【高级篇】(九)InnoDB的B+树索引的注意事项
- GaussDB(for MySQL)如何快速创建索引?华为云数据库资深架构师为您揭秘
- Mysql索引笔记
- mysql-server-5.7.25的my.cnf
- mysql索引之组合索引
- 解决Deprecated: mysql_connect(): The mysql extension is deprecated and will be removed in the future:
- mysql 数据库的分库分表详解
- mysql索引失效的情况以及left join关联字段字符集排序规则造成索引失效
- 图解 MySQL 索引,清晰易懂,写得太好了!
- mysql处理存在则更新,不存在则插入(多列唯一索引)
- mysql查询语句理解
- redis作为mysql的缓存服务器(读写分离)
- 2022-09-01 mysql/stonedb-多线程并行遍历元组遇到的问题分析
- 2023-03-07 mysql-explain-format=tree-解读-以TPCH-Q2为例
- 2023-05-08 mysql列存储引擎-union all与给返回值赋值集合出错-问题分析
- Mysql数据库查询好慢,除了索引,还能因为什么?
- MySQL服务端的登录和退出
- PYTHON3连接MYSQL数据库
- MySQL日期数据类型、MySQL时间类型使用总结
- navicat为mysql建立索引
- mysql建立索引的原则
- 测试环境治理之MYSQL索引优化篇
- Oracle与Mysql插入多行数据
- MySQL 数据同步
- mysql行锁测试