
三十四、python学之Flask框架(六)数据库:mysql数据库及Flask-SQLAlchemy
2023-09-27 14:29:29 时间
一、数据库知识回顾:
1.SQL:关系型数据库,支持结构化查询语言:
- 关系型数据库:以表的形式存储;
- 支持结构化查询语言:SQL语句;
- 列数固定;行数可变,定义数据,主键、外键,引用同表或不同表的主键,这种联系称为关系.
2.关于范式:
第一范式:原子性;表单中的每一列都是不可分割的
第二范式:在满足第一范式的基础上,消除非主属性对主属性的依赖;
第三范式:在满足第二范式的基础上,消除非主属性之间的依赖;
3. 补充:
冗余字段的作用:以空间换时间;
二、ORM:
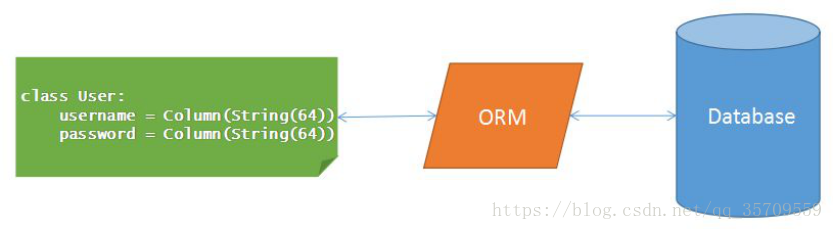
1.什么是ORM:
- ORM (Object-Relation Mapping.): 对象-关系映射.
- 主要实现模型对象到关系数据库数据的映射.
比如:把数据库表中每条记录映射为一个模型对象

ORM图解:
2.ORM的优点:
只需要面向对象编程, 不需要面向数据库编写代码.
对数据库的操作都转化成对类属性和方法的操作.
不用编写各种数据库的sql语句.实现了数据模型与数据库的解耦, 屏蔽了不同数据库操作上的差异.
不在关注用的是mysql、oracle…等.
通过简单的配置就可以轻松更换数据库, 而不需要修改代码.
3.ORM的缺点:
相比较直接使用SQL语句操作数据库,有性能损失.
根据对象的操作转换成SQL语句,根据查询的结果转化成对象, 在映射过程中有性能损失.
三、SQLAlchemy:
1.什么是SQLAlchemy:
(ppt23图片)
- SQLAlchemy(翻译:炼金术):就是对数据库的抽象;
- ORM:对象关系映射;
- SQLAlchemy:数据库抽象框架,实现ORM;
- 使用Flask-SQLAlchemy扩展包,是SQLAlchemy的具体实现;
2. Flask-SQLAlchemy安装及设置:
2.1 SQLAlchemy概述:
- SQLALchemy 实际上是对数据库的抽象,让开发者不用直接和 SQL 语句打交道,而是通过 Python 对象来操作数据库,在舍弃一些性能开销的同时,换来的是开发效率的较大提升
- SQLAlchemy是一个关系型数据库框架,它提供了高层的 ORM 和底层的原生数据库的操作。flask-sqlalchemy 是一个简化了 SQLAlchemy 操作的flask扩展。
- 文档地址:http://docs.jinkan.org/docs/flask-sqlalchemy
2.2 安装:
安装 flask-sqlalchemy
pip install flask-sqlalchemy
如果连接的是 mysql 数据库,需要安装 mysqldb
pip install flask-mysqldb
3.学习Flask_SQLAlchemy:
3.1. 使用Flask_SQLAlchemy连接数据库:
app.config[‘SQLALCHEMY_DATABASE_URI’] = ‘数据库类型://用户名:密码@ip和port/数据库名称’
app表示Flask程序实例
config是Flask配置对象
SQLALCHEMY_DATABASE_URI表示链接数据库的地址,为固定名称。
例如:
‘mysql://user:pwd@localhost/database’
3.2 其他设置:
# 动态追踪修改设置,如未设置只会提示警告
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
3.3 其他配置:
| 名字 | 备注 |
|---|---|
| SQLALCHEMY_DATABASE_URI | 用于连接的数据库 URI 。例如:sqlite:tmp/test.dbmysql://username:password@server/db |
| SQLALCHEMY_BINDS | 一个映射 binds 到连接 URI 的字典。更多 binds 的信息见用 Binds 操作多个数据库。 |
| SQLALCHEMY_ECHO | 如果设置为Ture, SQLAlchemy 会记录所有 发给 stderr 的语句,这对调试有用。(打印sql语句) |
| SQLALCHEMY_RECORD_QUERIES | 可以用于显式地禁用或启用查询记录。查询记录 在调试或测试模式自动启用。更多信息见get_debug_queries()。 |
| SQLALCHEMY_NATIVE_UNICODE | 可以用于显式禁用原生 unicode 支持。当使用 不合适的指定无编码的数据库默认值时,这对于 一些数据库适配器是必须的(比如 Ubuntu 上 某些版本的 PostgreSQL )。 |
| SQLALCHEMY_POOL_SIZE | 数据库连接池的大小。默认是引擎默认值(通常 是 5 ) |
| SQLALCHEMY_POOL_TIMEOUT | 设定连接池的连接超时时间。默认是 10 |
| SQLALCHEMY_POOL_RECYCLE | 多少秒后自动回收连接。这对 MySQL 是必要的, 它默认移除闲置多于 8 小时的连接。注意如果 使用了 MySQL , Flask-SQLALchemy 自动设定 这个值为 2 小时。 |
4.连接其他数据库
完整连接 URI 列表请跳转到 SQLAlchemy 下面的文档 (Supported Databases) 。这里给出一些 常见的连接字符串。
- Postgres:
postgresql://scott:tiger@localhost/mydatabase
- MySQL:
mysql://scott:tiger@localhost/mydatabase
- Oracle:
oracle://scott:tiger@127.0.0.1:1521/sidname
- SQLite (注意开头的四个斜线):
sqlite:absolute/path/to/foo.db
5.常用的SQLAlchemy字段类型:
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
6.常用的SQLAlchemy列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
7.常用的SQLAlchemy关系选项:
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多关系中关系表的名字 |
| secondary join | 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
注意:
重新学习一下数据库的关系(一对一,一对多,多对多);
ER模型;
补充到数据库相关的文章中
四、数据库的基本操作:
1.创建模型类:
导入模板
from flask import Flask
# 使用flask_sqlslchemy扩展
from flask_sqlalchemy import SQLAlchemy
实例化对象,并配置数据库:
app = Flask(__name__)
# 配置连接mysql数据库
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:19970125@127.0.0.1:3306/python32"
# 关闭动态追踪修改的警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
#展示sql语句
app.config["SQLALCHEMY_ECHO"] = True
# 实例化SQLAlchemy对象
db = SQLAlchemy(app)
创建数据表关系类:
创建角色关系类:
# 需求:实现一对多的关系映射,角色(管理员和普通用户)和用户,Role为一方,User为多方
# 定义模型类:必须继承db.Model
class Role(db.Model):
# 手动指定mysql表的名称
__tablename__ = "roles"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(32), unique=True)
# 定义关系引用, 第一个参数User表示多方的类名
# 第二个参数backref表示反向引用,给User模型用,实现多对一的查询
# 等号左边给一方Role使用,backref给多方使用
us = db.relationship("User", backref = 'role')
创建用户关系类:
# 定义用户表类
class User(db.Model):
__tablename__ = "users"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(32))
email = db.Column(db.String(32), unique=True)
pswd = db.Column(db.String(128),unique=True)
# 指定外键, 指向roles的id属性
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
主函数:
if __name__ == '__main__':
# 删除数据表
db.drop_all()
# 创建数据表
db.create_all()
# 实例化模型类对象,添加测试数据
ro1 = Role(name = "admin")
ro2 = Role(name = "user")
db.session.add_all([ro1, ro2])
db.session.commit()
us1 = User(name = "wang", email = "wang@163.com", pswd = "123456", role_id = ro1.id)
us2 = User(name='zhang', email='zhang@189.com', pswd='201512', role_id=ro2.id)
us3 = User(name='chen', email='chen@126.com', pswd='987654', role_id=ro2.id)
us4 = User(name='zhou', email='zhou@163.com', pswd='456789', role_id=ro1.id)
db.session.add_all([us1, us2, us3, us4])
db.session.commit()
app.run(debug=True)
相关文章
- 【mysql+pandas】用MySQL命令处理在python中处理DataFrame数据 pandasql库
- python通过ssh连接mysql数据库的注意事项
- Python 操作 MySQL 数据库
- Python使用MySQL数据库从入门到精通
- python使用mysql数据库
- python mysql orm
- 《Python Cookbook(第2版)中文版》——1.22 在标准输出中打印Unicode字符
- 基于Python(Django )+VUE+MySQL实现多功能美颜 Web 应用【100010556】
- 基于Python+Vue+Mysql实现(物联网)智能大棚【100010340】
- Python 操作 mysql 数据库,并使用连接池
- 使用 Python 操作 MySQL 数据库
- Python MySQL 数据库连接不同方式
- 转 Python 访问数据库(SQLite、MySQL、SQLAlchemy)
- python操作mysql数据库系列-操作MySql数据库(三)
- MySQL实战之三:Python连接与操作
- Python 操作 MySQL 之 pysql 与 ORM(转载)
- [Spark][Python]Spark 访问 mysql , 生成 dataframe 的例子:
- python数据库操作,python从mssql 查询结果,插入到mysql表
- 【图像处理】——Python+opencv实现图像的hu不变矩特征提取(含原理、推导过程、应用、代码等)
- 【数据库学习】——Python实现mysql数据库SQL文件生成和导入
- python构建web界面实现MySQL数据库的操作