
吴恩达深度学习网课 通俗版笔记——(02.改善深层神经网络)第一周 深度学习的实用层面
改善深层神经网络——深度学习的实用层面
前面已经学会了基本的神经网络搭建,但只有把参数调好,使各项设置更符合自己的问题,才能最大化我们的预测准确率。
这一周的内容在机器学习网课中实际上大部分都已经有讲,注意一些更新变化的点。
1.1 训练/验证/测试集
该节主要是讲如何分割训练集、验证集和测试集。
- 只有训练集和测试集——7:3
- 三者都有——6:2:2
- 百万级数据——训练集占到99%以上
还有一点就是验证集和测试集的数据要匹配,即最好是同一来源,这样才不会影响最终的预测。
k折交叉验证具体做法:把数据分成训练集和测试集,将训练集平均分为k份,取其中k-1份作训练集,另一份作测试集,共迭代10次,每一次迭代有一个性能评估,取所有迭代的平均值即为对当前模型的评估。(要评估另一模型则改变参数再重复上述过程)
1.2 偏差/方差
该节讲解常见的偏差、方差问题。
- 高偏差即对训练集拟合度低(欠拟合)
- 高方差即对验证集或测试集拟合度低(过拟合)
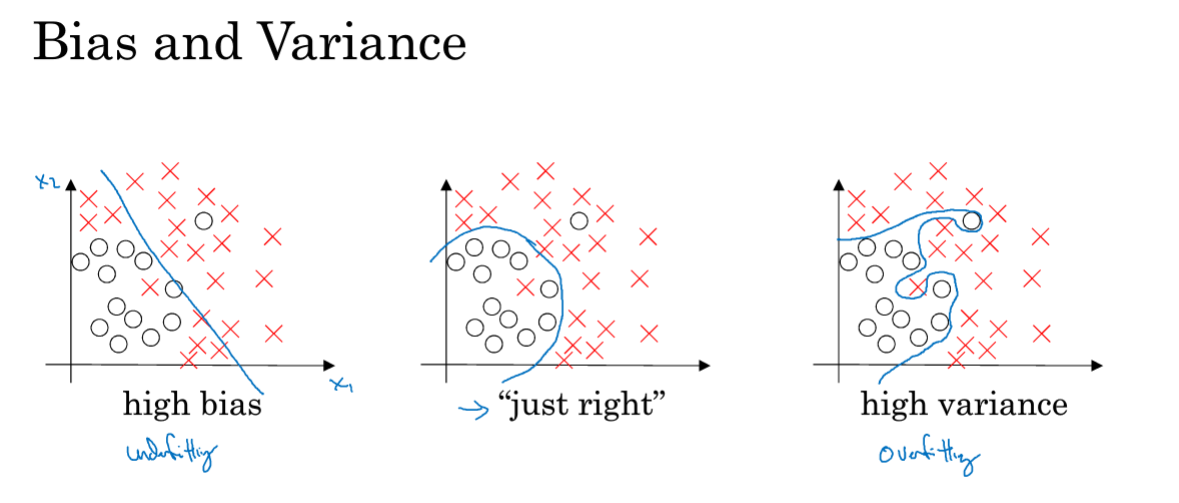
上图为三种基本情况。
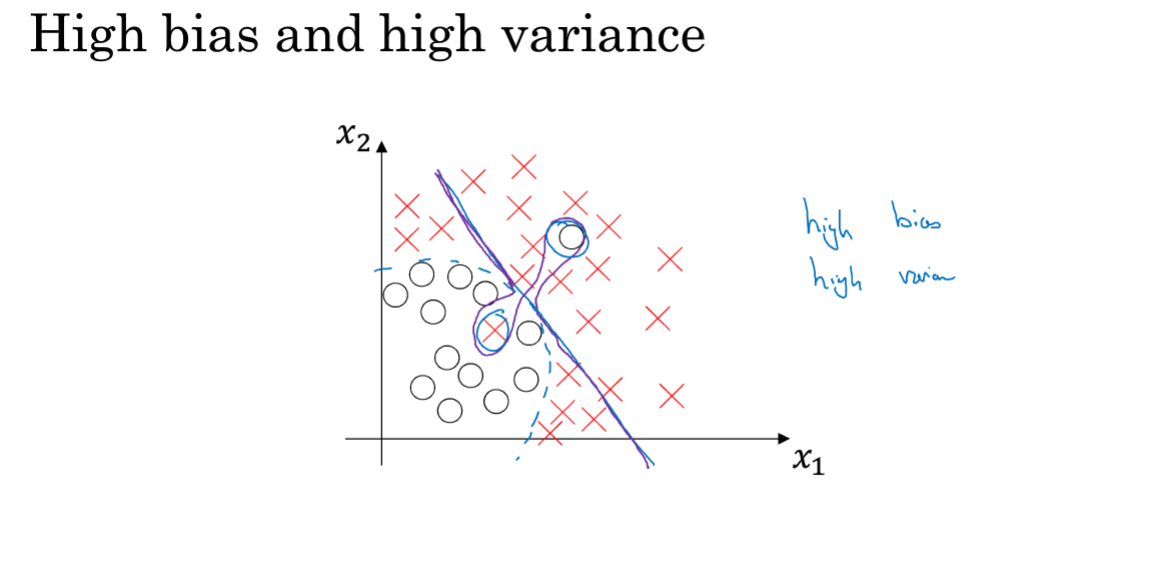
注意还有一种情况就是,既高偏差又高方差。
1.3 机器学习基础
该节简要给出在高偏差和高方差的情况下有哪些措施可以采取。
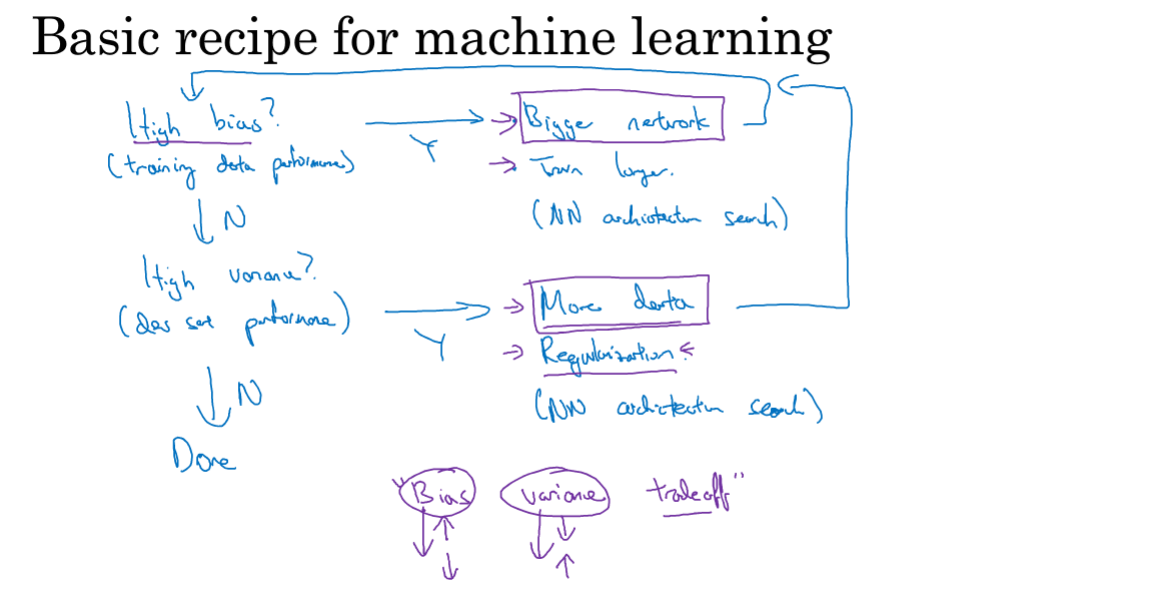
训练算法的一个大体步骤如上图所示,简要阐述就是:
- 训练完成后,先在训练集上做预测,判断是否有高偏差现象。
- 如果有,采取一些措施(采用更大的神经网络、增加迭代次数),然后再接着判断。
- 直到偏差降低到合适值,再在验证集上预测,判断是否有高方差现象。
- 如果有,采取一些措施(用更多的数据集、正则化),最后整体判断,结束。
1.4 正则化
正则化是处理过拟合问题的首选方法,实际上就是给代价函数后面添加一个参数式,来控制最终我们学习到的参数的值,从而控制最终的预测。

L2正则化:逻辑回归的正则化使用欧几里德范数,注意dw也会跟着变化。

神经网络使用Frobenius范数(弗罗贝尼乌斯),就是每一层的w矩阵中所有元素的平方和。
L2正则化也被称为权重衰减,注意上图最后一行,跟非正则化情况w的梯度下降相比,每次对w都进行了一个缩小。
1.5 为什么正则化可以减少过拟合?
因为设定了λ参数,λ比较大时,由于要最小化代价函数,则Frobenius范数会比较小,即w很小甚至接近于0,这会使网络变得更加线性化,线性化的分类则偏差往往更大,从而将我们的高方差模型往高偏差模型转变。
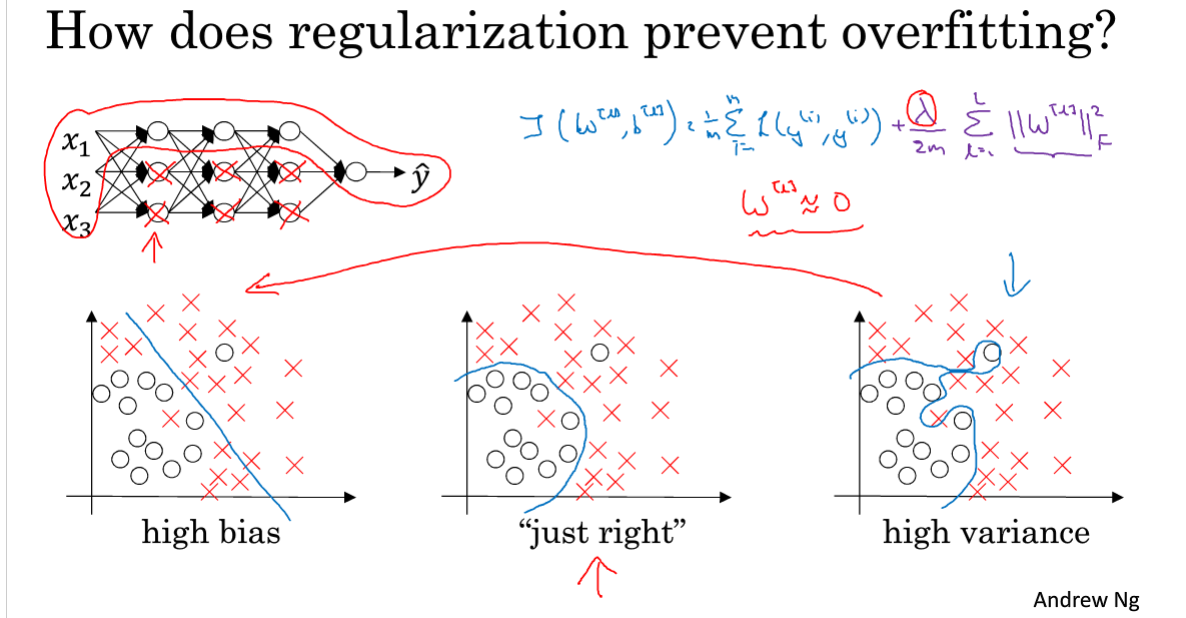
当找到折中的λ,则就可以让我们的模型分类面达到最佳。
1.6 Dropout正则化
除了上面讲到的L2正则化(其他机器学习算法也常用),还有一种神经网络中常使用的Dropout正则化,简单粗暴解释就是:每一次迭代,对于网络的每一层,随机丢弃一些单元。
具体实现一般采用反向随机失活方法:

生成一个与当前层同维度的0,1组成的随机矩阵,通过设置保留概率使得随机的一部分元素为1,其余为0。用当前层矩阵和该矩阵逐元素乘即可消除部分隐藏单元,最后记得要用当前层矩阵除以一个保留概率,这样可以保证计算出的期望值不变。
在测试集做预测的时候不使用dropout。
1.7 理解Dropout
Dropout思想其实和L2正则化很相似,为什么能够减轻过拟合主要有两点原因:
- 丢弃单元,导致网络变小
- 每一个特征都可能被丢弃,因此网络不会偏向某一个特征,每个特征的权重都很小
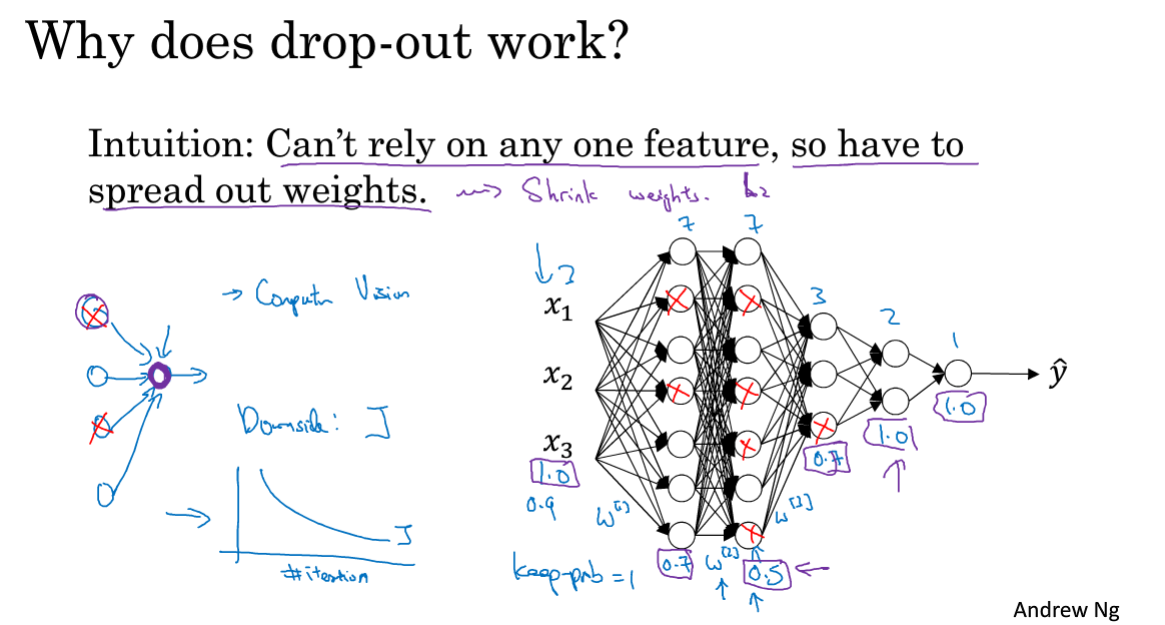
注意使用dropout正则化没有办法明确定义的代价函数,因此缺点之一也是无法做出好的代价曲线来调试。所以通常先不开启dropout,先做出代价曲线保证单调下降以后再进行dropout正则化。
用下面两张图来展示dropout非常直观:
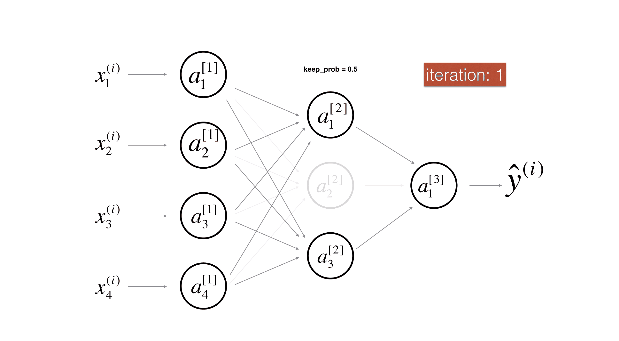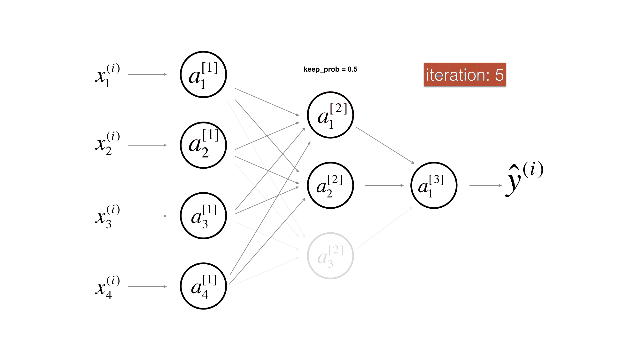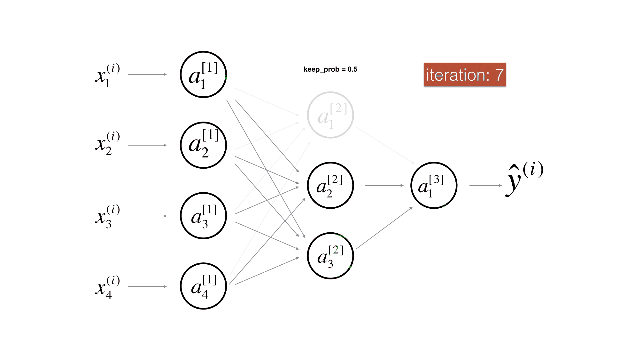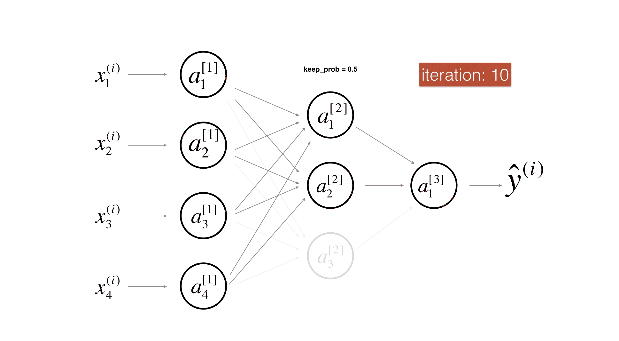
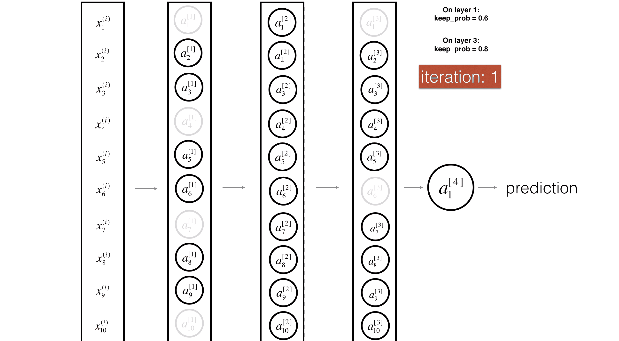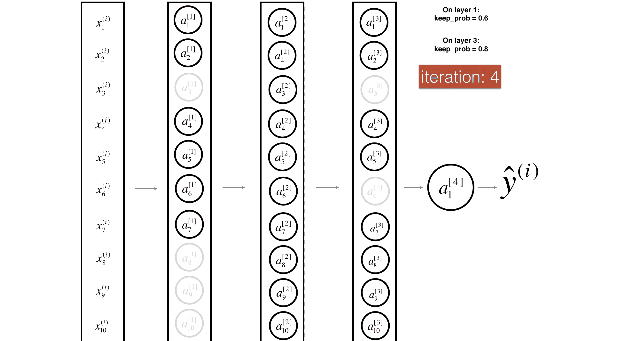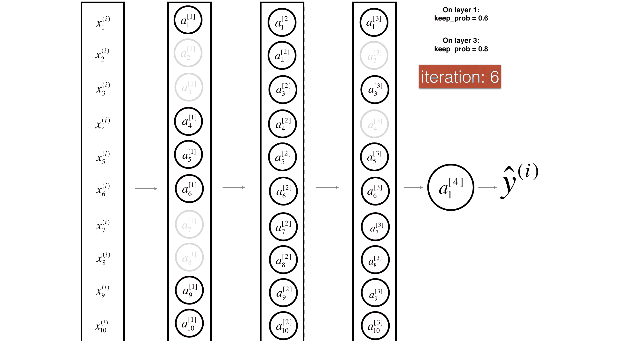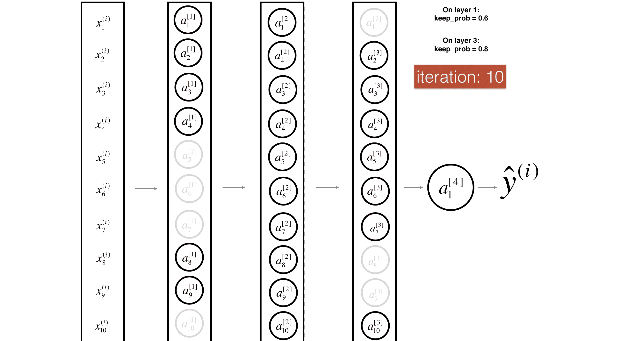
1.8 其他正则化方法
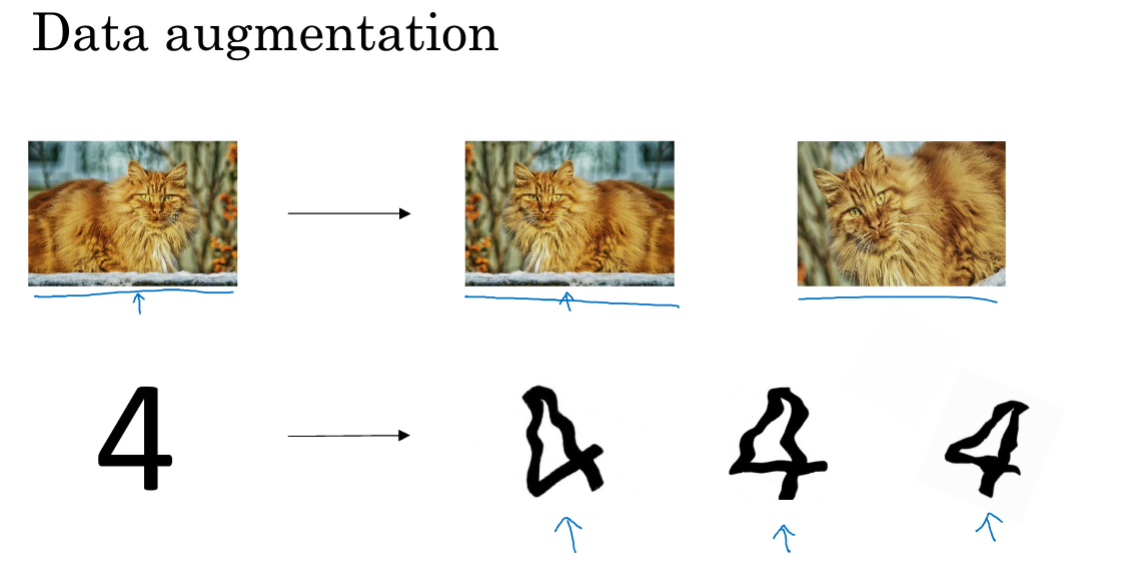
除了上面介绍的两种方法外,还有两种正则化方法:数据扩增,earlystopping。
- 数据扩增就是自己再生成一些假训练集,比如做图像识别,可以把图片通过旋转裁剪再生成一些新的样本,比重新收集新数据集成本小很多。
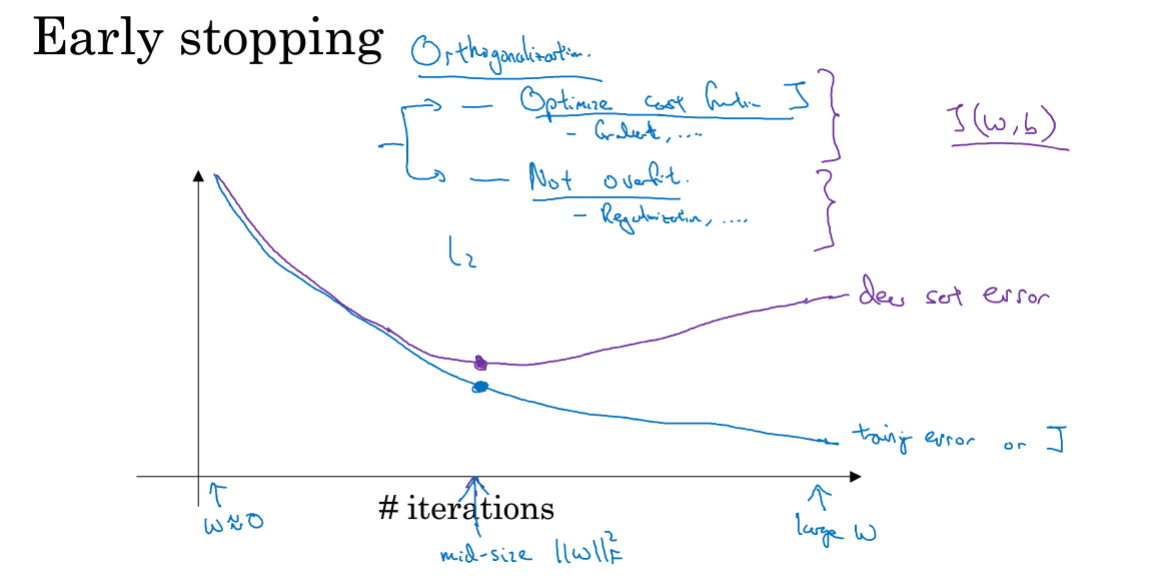
- earlystopping就是在迭代过程中,也画出每一次迭代后参数在验证集上的代价,选取代价不再降低的点,停止梯度下降,这样也就减少了神经网络的复杂度,从而防止过拟合。
1.9 归一化输入
对于特征的输入,通常来说所有特征并不都在同一个量级,这会导致代价函数不均匀,某特征占主导,梯度下降速度慢(下图所示),因此一般会将特征值归一化到同一区间。([0,1]或[-1,1])
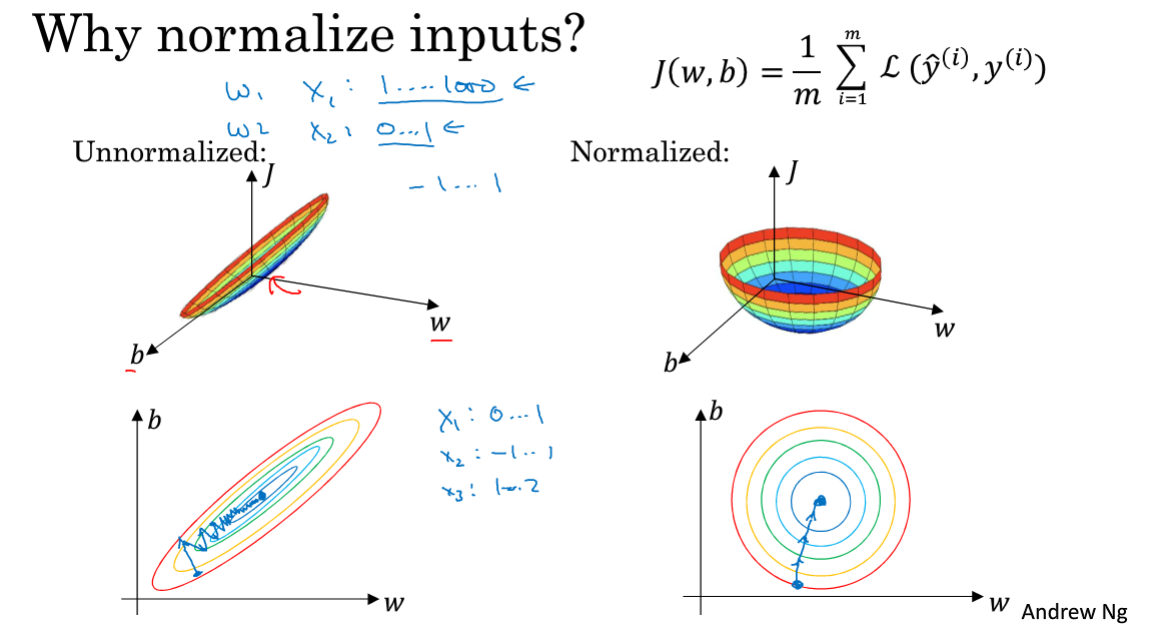
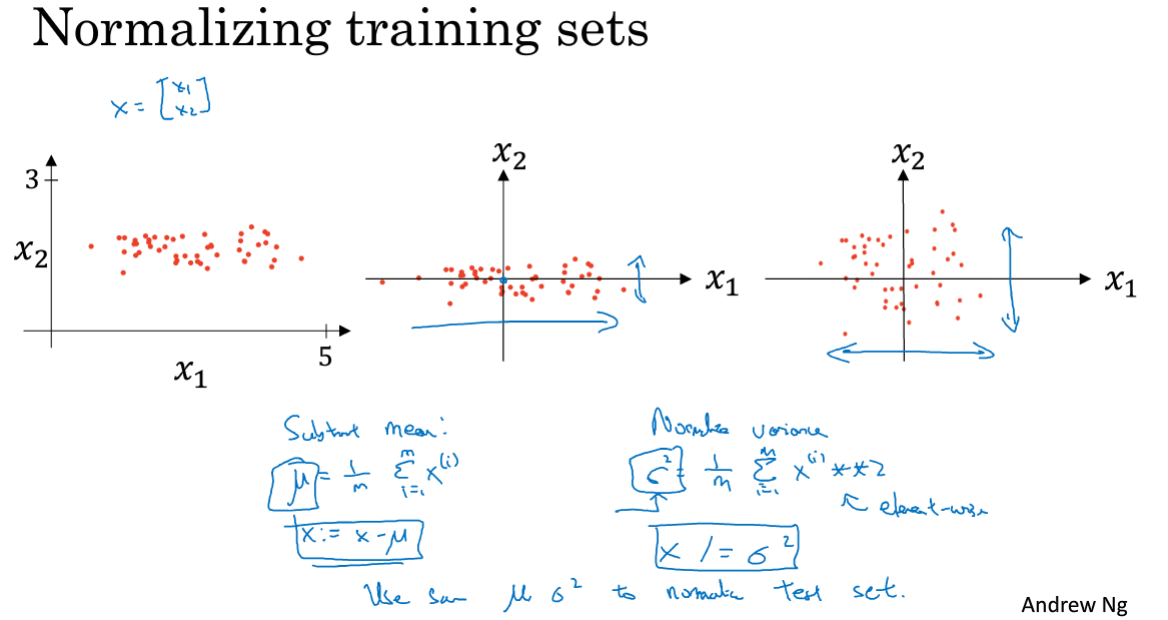
计算每个特征的值减去该特征所有样本的均值,然后除以方差。
1.10 梯度消失与梯度爆炸
梯度消失和梯度爆炸,训练神经网络时,导数变得很大或者很小,这会导致梯度下降变得非常缓慢。
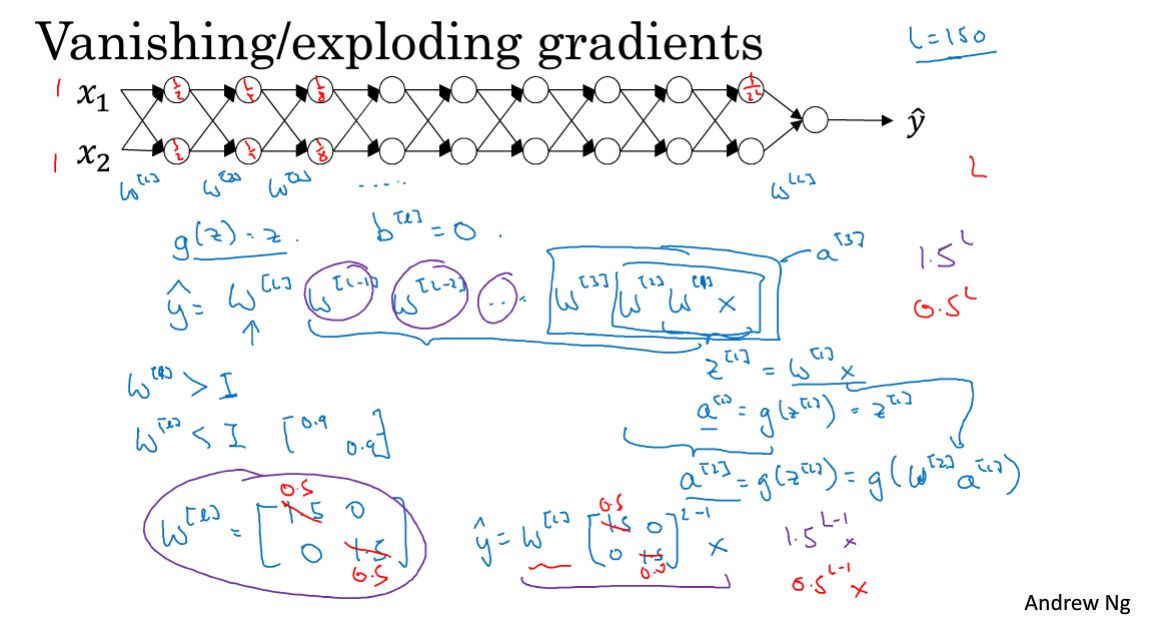
W初始化比较小,则层层递进相乘会导致最后结果越来越小,则求导的结果也会很小,梯度消失。
反之亦然。
1.11 神经网络的权重初始化
为了避免出现上节提到的梯度消失和梯度爆炸问题,可以参数进行特定的初始化防止其过大过小。

如上图所示,每一层的权重初始化可根据上一层的特征数量来定,根据不同的激活方式选择不同的初始化方法。
1.12 梯度的数值逼近
本节给出双测公差以及单测公差的计算方式,并证明了双侧公差准确度远高于单侧公差。

我们在梯度检验中将用该数值方法计算导数和用算法计算导数进行对比,保证我们的算法是运行正确的。
1.13 梯度检验
梯度检验:一方面,当前参数W和b通过反向传播算法链式求导能求出每个参数对应的导数值dW,db;另一方面,利用代价函数使用最原始的双侧公差逼近求导方法也能求出当前参数下的导数dW,db;对比这两种方法算出来的导数值,如果误差小于10^7(大概),则认为算法实现是正确的。

实际上,反向传播算法中我们相当于用了求导公式去直接求导,而数值计算中我们用的最原始的定义去求导,用定义去验证我们算法代码有没有写错,可以避免很多未知的BUG。
注意,数值计算时需要把所有参数展开为一个大向量,算出的导数也是大向量,为了对比也需要把算法计算出的导数也展开为大向量。
1.14 关于梯度检验实现的注记

梯度检验要注意以下5点:
- 不要在训练中进行梯度检验,成本太高。训练前执行一次,确认算法没问题即可
- 梯度检验如果出问题了,具体看一下是参数哪一部分误差大,再去定位BUG
- L2正则化不影响检验,代价函数记得加上正则化项
- dropout正则化一般不与梯度检验共用
- 有一种情况就是只有在W和b接近0的时候检验才正确,可以训练一段时间后再检验一次(少用)
相关文章
- 学习笔记 | 2023 ICLR ParetoGNN 多任务自监督图神经网络实现更强的任务泛化
- 06 卷积神经网络CNN-学习笔记-李宏毅深度学习2021年度
- 2020李宏毅机器学习笔记— 9. Recurrent Neural Network(RNN循环神经网络)
- 【计算机视觉】【神经网络与深度学习】论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 【神经网络与深度学习】GLog使用笔记
- [轻笔记] label smoothing(标签平滑)
- StyleCop学习笔记——默认的规则
- Springcloud学习笔记39--拦截器Interceptor详细使用
- Java学习笔记之switch & 循环语句
- HTML – W3Schools 学习笔记
- angular2 学习笔记 ( ngModule 模块 )
- JProfiler学习笔记
- SpringMVC 学习笔记(五) 基于RESTful的CRUD
- 麦子学院6.1 神经网络算法(Nerual Networks)(上) 学习笔记
- 图神经网络-GCN学习笔记
- 图神经网络-图游走类模型 异构图 Methpath2Vec 学习笔记
- 图神经网络-图游走类模型 同构图 学习笔记
- 图神经网络-图与图学习笔记-2
- 图神经网络系列-GCN学习笔记-代码实战
- 图神经网络系列-GCN学习笔记-1
- Unity3D之Mecanim动画系统学习笔记(九):Blend Tree(混合树)
- golang 笔记
- jackson 学习笔记
- Webpack学习笔记
- 图像编程学习笔记2——bmp位图平移
- jQgrid学习笔记