
tesseract - the most popular OCR library from Google
tesseract
https://github.com/tesseract-ocr/tesseract
此包包含一个OCR引擎 libtesseract 和 命令行程序 tesseract
版本4添加了一个基于OCR引擎的神经网络。
支持多余100多种语言,开箱即用
支持多种输出格式, 普通文本, HTML, PDF ...
This package contains an OCR engine -
libtesseractand a command line program -tesseract. Tesseract 4 adds a new neural net (LSTM) based OCR engine which is focused on line recognition, but also still supports the legacy Tesseract OCR engine of Tesseract 3 which works by recognizing character patterns. Compatibility with Tesseract 3 is enabled by using the Legacy OCR Engine mode (--oem 0). It also needs traineddata files which support the legacy engine, for example those from the tessdata repository.The lead developer is Ray Smith. The maintainer is Zdenko Podobny. For a list of contributors see AUTHORS and GitHub's log of contributors.
Tesseract has unicode (UTF-8) support, and can recognize more than 100 languages "out of the box".
Tesseract supports various output formats: plain text, hOCR (HTML), PDF, invisible-text-only PDF, TSV. The master branch also has experimental support for ALTO (XML) output.
You should note that in many cases, in order to get better OCR results, you'll need to improve the quality of the image you are giving Tesseract.
manual
https://tesseract-ocr.github.io/tessdoc/
支持的模型数据
https://github.com/tesseract-ocr/tessdata
These language data files only work with Tesseract 4.0.0 and newer versions. They are based on the sources in tesseract-ocr/langdata on GitHub. (still to be updated for 4.0.0 - 20180322)
These have models for legacy tesseract engine (--oem 0) as well as the new LSTM neural net based engine (--oem 1).
The LSTM models (--oem 1) in these files have been updated to the integerized versions of tessdata_best on GitHub. So, they should be faster but probably a little less accurate than tessdata_best.
tessdata_fast on GitHub provides an alternate set of integerized LSTM models which have been built with a smaller network. tessdata_fast files are the ones packaged for Debian and Ubuntu.
The legacy tesseract models (--oem 0) have been removed for Indic and Arabic script language files.
tesseract--命名含义
https://en.wikipedia.org/wiki/Tesseract
本身此词的意思是 立方体的思维模拟,图像如下
In geometry, the tesseract is the four-dimensional analogue of the cube; the tesseract is to the cube as the cube is to the square.[1] Just as the surface of the cube consists of six square faces, the hypersurface of the tesseract consists of eight cubical cells. The tesseract is one of the six convex regular 4-polytopes.
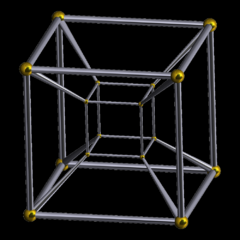

https://marvelcinematicuniverse.fandom.com/wiki/Tesseract
应该是来源于这部电影,
tesseract是一个立方体, 水晶立方体形状的容器舱, 装着太空石头, 这个太空石是在宇宙产生之前就存在的6个无限石之一, 拥有无限的能量。
The Tesseract, also called the Cube, was a crystalline cube-shaped containment vessel for the Space Stone, one of the six Infinity Stones that predate the universe and possess unlimited energy. It was used by various ancient civilizations before coming into Asgardian hands, kept inside Odin's Vault. Eventually, it was brought to Earth and left in Tønsberg, where it was guarded by devout Asgardian worshipers.
In 1942, the Tesseract was retrieved by Johann Schmidt, the leader of HYDRA, who used the Tesseract to power enhanced weaponry in order to defeat the Allies during World War II. Following Schmidt's defeat at the hands of Captain America in 1945, the Tesseract fell into Arctic waters, where it was recovered by Howard Stark. The Tesseract was then kept at Camp Lehigh in New Jersey, where it remained until at least 1970.
What is OCR?
https://en.wikipedia.org/wiki/Optical_character_recognition
视觉文字识别。
Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo (for example the text on signs and billboards in a landscape photo) or from subtitle text superimposed on an image (for example: from a television broadcast).[1]
Widely used as a form of data entry from printed paper data records – whether passport documents, invoices, bank statements, computerized receipts, business cards, mail, printouts of static-data, or any suitable documentation – it is a common method of digitizing printed texts so that they can be electronically edited, searched, stored more compactly, displayed on-line, and used in machine processes such as cognitive computing, machine translation, (extracted) text-to-speech, key data and text mining. OCR is a field of research in pattern recognition, artificial intelligence and computer vision.
Early versions needed to be trained with images of each character, and worked on one font at a time. Advanced systems capable of producing a high degree of recognition accuracy for most fonts are now common, and with support for a variety of digital image file format inputs.[2] Some systems are capable of reproducing formatted output that closely approximates the original page including images, columns, and other non-textual components.
安装
https://tesseract-ocr.github.io/tessdoc/Installation.html
Linux
Tesseract is available directly from many Linux distributions. The package is generally called ‘tesseract’ or ‘tesseract-ocr’ - search your distribution’s repositories to find it. Thus you can install Tesseract 4.x and its developer tools on Ubuntu 18.x bionic by simply running:
sudo apt install tesseract-ocr sudo apt install libtesseract-dev
识别示例
https://www.cnblogs.com/BackingStar/p/11254120.html
简单使用
import pytesseract from PIL import Image if __name__ == '__main__': text = pytesseract.image_to_string(Image.open("D:\\test.png"),lang="eng") print(text)测试图片:

输出结果:

全栈集成
https://stackabuse.com/pytesseract-simple-python-optical-character-recognition/
Through Tesseract and the Python-Tesseract library, we have been able to scan images and extract text from them. This is Optical Character Recognition and it can be of great use in many situations.
We have built a scanner that takes an image and returns the text contained in the image and integrated it into a Flask application as the interface. This allows us to expose the functionality in a more familiar medium and in a way that can serve multiple people simultaneously.
相关文章
- 很佩服的一个 Google 大佬,离职了。。
- 微信文章底部增加淘宝入口;Google 推出 ChatGPT 竞品 Bard;苹果或推出无接口设计iPhone|极客头条
- [Map 3D] Google Map 3D Construction
- Enabling Flash for Google Chrome (Windows/Macintosh)
- VMware、Pivotal和Google Cloud协力推出全新基于Kubernetes的容器服务——Pivotal Container Service(PKS)
- Google Colab免费GPU使用教程(一)
- 几个主要搜索引擎(Google和百度、雅虎)的站内搜索代码
- 自定义Google扩展皮肤
- 【Google Play】正式版上架流程 ( 创建版本 | 设置国家地区 | 发布正式版 )
- google-chrome-stable add apt-key