
AcWing 1073. 树的中心
\(AcWing\) \(1073\). 树的中心
一、题目描述
给定一棵树,树中包含 \(n\) 个结点(编号\(1\)~\(n\))和 \(n−1\) 条无向边,每条边都有一个权值。
请你在树中找到一个点,使得该点到树中其他结点的最远距离最近。
输入格式
第一行包含整数 \(n\)。
接下来 \(n−1\) 行,每行包含三个整数 \(a_i,b_i,c_i\),表示点 \(a_i\) 和 \(b_i\)
之间存在一条权值为 \(c_i\) 的边。
输出格式
输出一个整数,表示所求点到树中其他结点的最远距离。
数据范围
\(1≤n≤10000,\)
\(1≤a_i,b_i≤n,\)
\(1≤c_i≤10^5\)
输入样例:
5
2 1 1
3 2 1
4 3 1
5 1 1
输出样例:
2
二、暴力大法
国际惯例上来就写暴力:
对每一个点都求得他的最远距离, 显然其中最小的就是所求
通过 \(7/11\)个数据然后\(TLE\)
#include <bits/stdc++.h>
using namespace std;
const int INF = 0x3f3f3f3f;
const int N = 10010, M = 20010;
int n;
int ans;
int res = INF;
int st[N];
// 邻接表
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
void dfs(int u, int sum) {
st[u] = 1;
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (st[j]) continue;
dfs(j, sum + w[i]);
}
if (sum > ans) ans = sum;
}
int main() {
memset(h, -1, sizeof h);
cin >> n;
for (int i = 1; i < n; i++) {
int a, b, c;
cin >> a >> b >> c;
add(a, b, c), add(b, a, c);
}
for (int i = 1; i <= n; i++) {
ans = 0;
memset(st, 0, sizeof st);
dfs(i, 0);
res = min(res, ans);
}
printf("%d\n", res);
return 0;
}
三、换根\(DP\)解法【模板,背诵】
【黄海注:与前一题类似,也是怕两重循环导致时间复杂度上升到\(O(N^2)\),不能遍历每两个节点,只能是遍历每个节点,尝试构建此节点的相关信息,再用这些信息组装出树的中心。】
首先明确树中节点的最远距离 只可能是当前节点到叶节点的距离
因为如果不是到叶子节点,那么必然存在一条多走几步到达叶子节点的路径,那岂不是更长?
所以只需要知道 每个点到叶节点的最远距离,再找出其中的最小距离即可。
以下面这棵树为例:

以\(1\)节点为根节点的时候,进行普通的树上 \(dp\) 时 \(3\) 节点便只会更新到 \(5,6\) 节点的距离,却并不能直接更新到\(4\)节点的距离,但可以通过\(1\)节点与\(3\)节点之间的关系得出\(3\)到\(4\)节点的距离,即将\(3\)节点看作根节点,将\(1\)节点看作子节点,这就是换根\(dp\)的意义了:
-
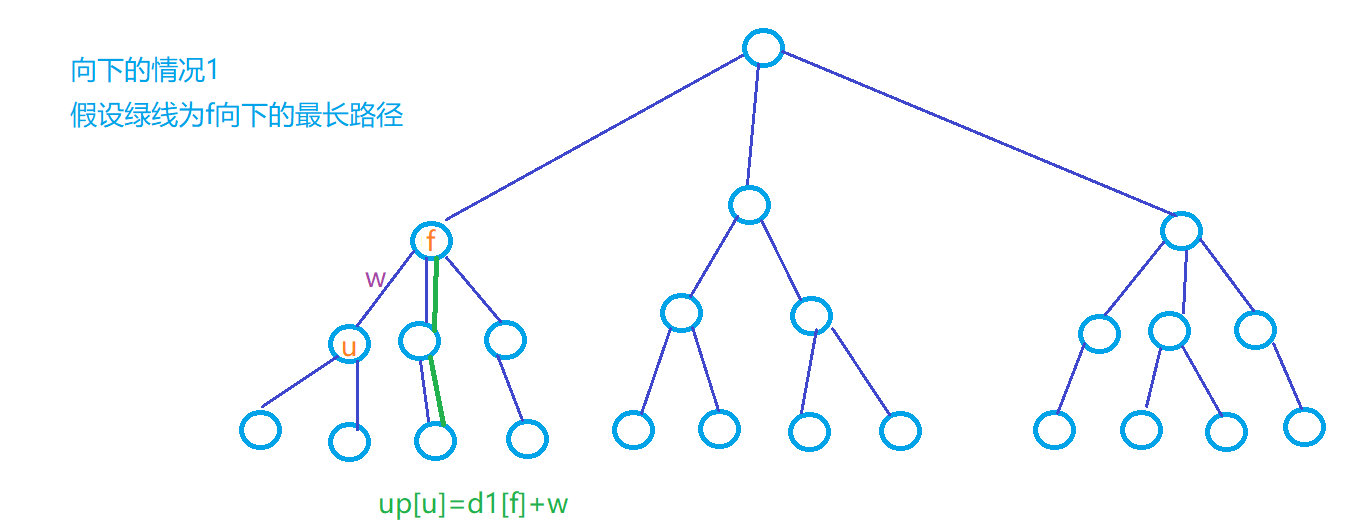
\(d1[u]\):存下\(u\)节点向下走的最长路径的长度
-
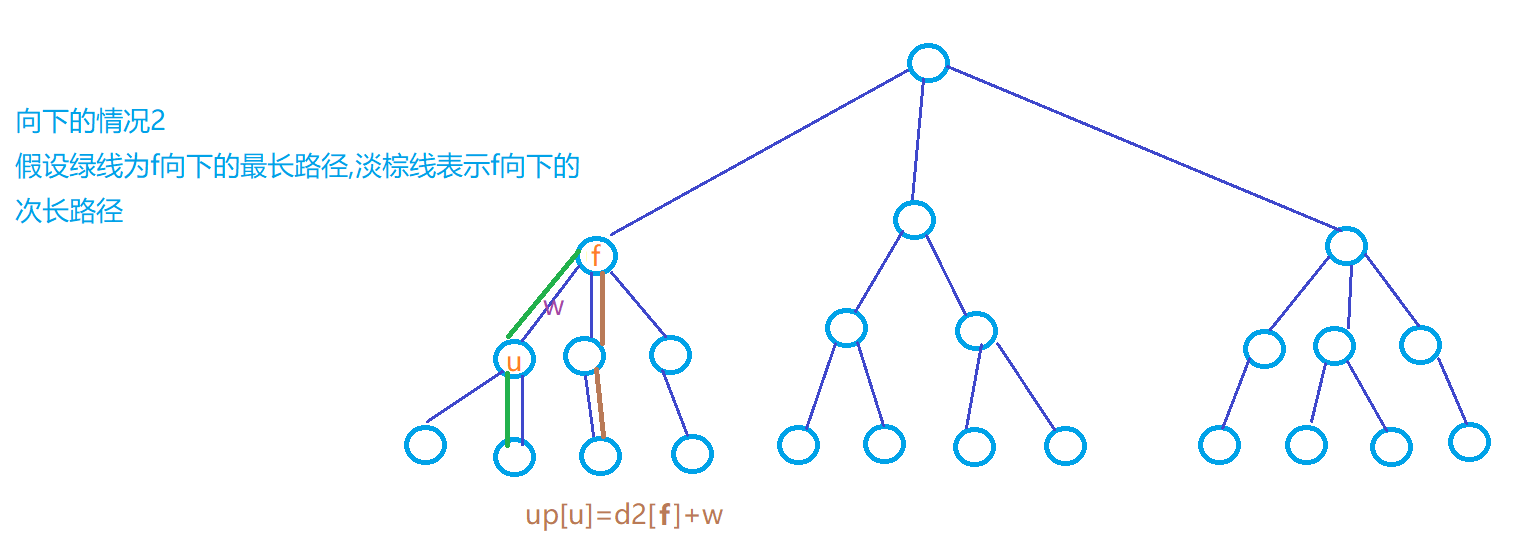
\(d2[u]\):存下\(u\)节点向下走的次长路径的长度
-
\(p1[u]\):存下\(u\)节点向下走的最长路径是从哪一个节点下去的
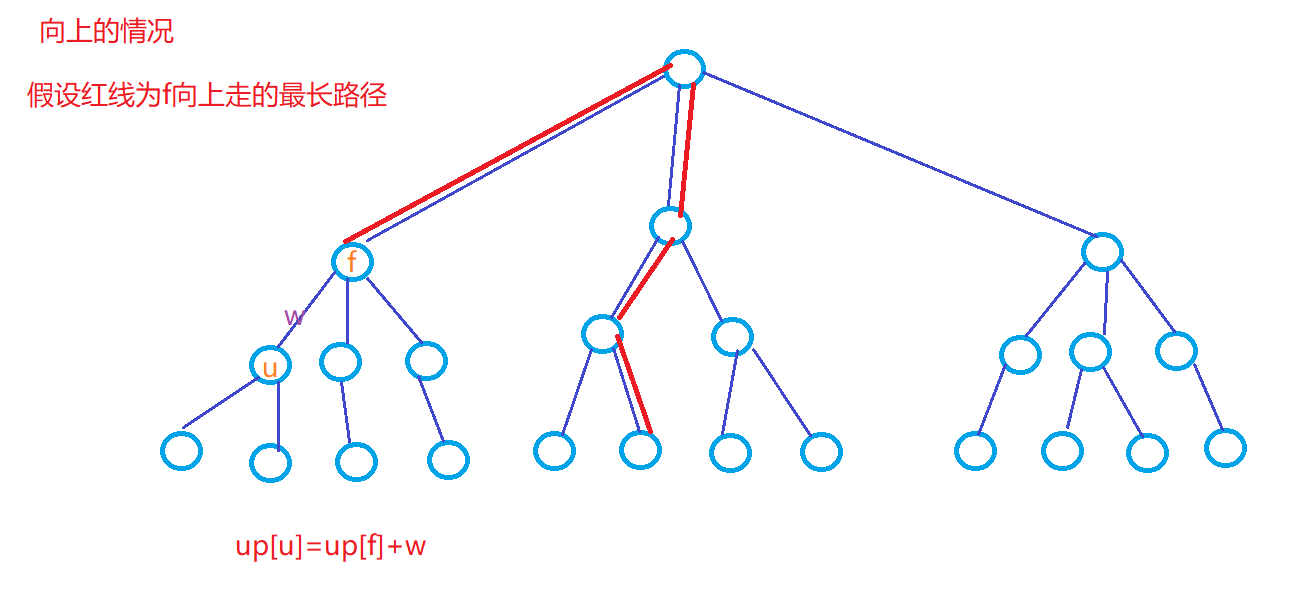
-
\(up[u]\):存下\(u\)节点向上走的最长路径的长度
\(Q0:\)为什么记录了\(p1[u]\),而不需要记录\(p2[u]\)呢?
\(A\):对父节点\(f\)而言,它的最远距离可能是\(up[f]\),也可能是\(d1[f]\),但如果\(u\)是出现在\(d1[f]\)的路线上时,就不能选择这条路径,需要选择\(d2[f]\)。我们需要解决的问题是:判断\(u\)是不是出现在\(f\)的最长路径中,也就是和\(d1[f]\)相关的\(p1[f]\)有用,\(p2[f]\)用不到。
图解
实现代码
#include <bits/stdc++.h>
using namespace std;
const int N = 10010;
const int M = N << 1;
const int INF = 0x3f3f3f3f;
int n;
int d1[N]; // d1[u]:存下u节点向下走的最长路径的长度
int d2[N]; // d2[u]:存下u节点向下走的次长路径的长度
int p1[N]; // p1[u]:存下u节点向下走的最长路径是从哪一个节点下去的
int up[N]; // up[u]:存下u节点向上走的最长路径的长度
int st[N];
// 邻接表
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
// 功能:以u为根,向叶子进行递归,利用子节点返回的最长信息,更新自己的最长和次长,并记录最长是从哪个节点来的
void dfs1(int u) {
st[u] = 1;
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (st[j]) continue;
// 递归完才能有数据
dfs1(j);
if (d1[j] + w[i] >= d1[u]) { // 更新最长
d2[u] = d1[u]; // ① 更新次长,必须在第一位,因为下面d1[u]会被改写
d1[u] = d1[j] + w[i]; // ② 更新最长
p1[u] = j; // ③ 记录最长来源
} else if (d1[j] + w[i] > d2[u]) // 更新次长
d2[u] = d1[j] + w[i];
}
}
// 功能:完成向上的信息填充
void dfs2(int u) {
st[u] = 1;
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (st[j]) continue;
// 三者取其一
up[j] = w[i] + up[u];
if (p1[u] == j)
up[j] = max(up[j], w[i] + d2[u]);
else
up[j] = max(up[j], w[i] + d1[u]);
// 准备好了信息,再进入递归
dfs2(j);
}
}
int main() {
memset(h, -1, sizeof h);
cin >> n;
for (int i = 1; i < n; i++) {
int a, b, c;
cin >> a >> b >> c;
add(a, b, c), add(b, a, c);
}
memset(st, 0, sizeof st);
dfs1(1); // 选择任意一个节点进行dfs,用儿子更新父亲的统计信息
memset(st, 0, sizeof st);
dfs2(1); // 向上
int res = INF;
for (int i = 1; i <= n; i++) res = min(res, max(d1[i], up[i]));
printf("%d\n", res);
return 0;
}
\(Q1\):为什么\(dfs1\)中要“先安排工作,后统计信息”?
\(A\):因为后面\(u\)统计的信息,是根据\(y\)的信息来的,儿子的信息没出来,爹的信息就统计不出来
\(Q2\):为什么\(dfs2\)中要 “先统计信息,后安排工作”?
\(A\):因为你继续递归时,在子函数调用时,是否需要前序提供的信息,比如此处在处理子节点\(j\)时,需要更新\(up[j]\),但\(up[j]\)是依赖于\(up[u],d1[u],d2[u]\)的,\(d1[u],d2[u]\)在\(dfs1\)中已完成填充,没有问题,但\(up[u]\)如果还没正确填充内容,后续就无法完成计算了,所以必须在进入递归前完成统计信息计算,为后面的子递归提供数据信息。
\(Q3\):为什么非得跑一遍\(dfs1\),再跑一遍\(dfs2\),只跑一遍不行吗?
\(A\):第一遍\(dfs\),解决的是我的孩子到我有多远的问题,没有记录,也没法记录 我爹,我爷爷离我有多远的问题,那需要再跑一遍反向的才能知道。
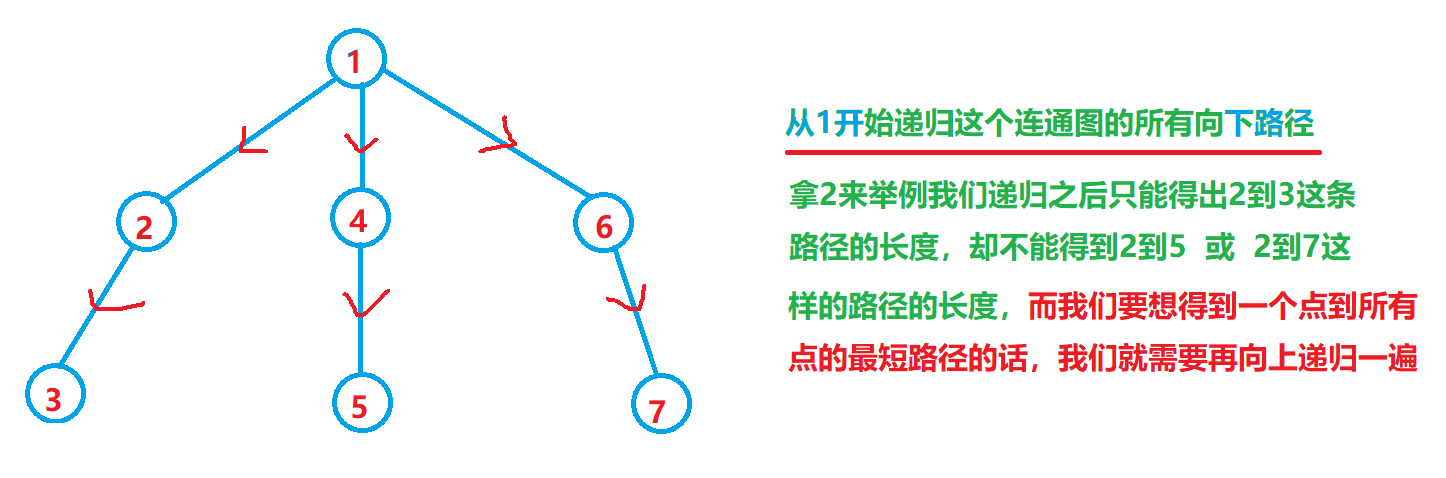
\(Q4\):据说边权要是负的,需要修改代码,该怎么改?
\(A:\)如下,把下面两句注释的话放开即可
void dfs1(int u) {
// d1[u] = d2[u] = -INF; //这题所有边权都是正的,可以不用初始化为负无穷
st[u]=1;
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (st[j]) continue;
dfs1(j);
if (d1[j] + w[i] >= d1[u]) {
d2[u] = d1[u];
d1[u] = d1[j] + w[i];
p1[u] = j;
} else if (d1[j] + w[i] > d2[u])
d2[u] = d1[j] + w[i];
}
// if (d1[u] == -INF) d1[u] = d2[u] = 0; //特判叶子结点
}
四、四次\(dfs\)解法【另类解法】
相信你肯定会写最简单的\(dfs\):
void dfs(int u,int sum){
st[u]=1;
for(int i=h[u];~i;i=ne[i]){
int j=e[i];
if(st[j]) continue;
dfs(j,sum+w[i]);
}
}
这里将讲述如何 用四次最简单的\(dfs\)解决这个树的中心问题。
其实这个题有一个结论,树的中心一定在树的直径上面。(很容易证明,因为树的直径是树上最长的一条路径,那么想要达到树的中心的目的,那就必须在树的直径上面,证的比较敷衍,大家可以画个图理解一下)
我们就运用这个结论,来寻找我们的答案。
首先我们要做的第一件事就是 找到树的直径的两个端点,这个过程可以利用 两次\(dfs\) 来解决:
【黄海注:如果树的权值为负数,就会失败: 传送门】
第一次\(dfs\)从任意起点开始,走到一个距离最远的点,那就是树的直径的一个端点
第二次\(dfs\)再从第一次\(dfs\)找到的一个端点开始,继续找到一个距离最远的点,那就是树的直径的另外一个端点
这里我就不赘述证明了,想看证明的同学可以移步洛谷里面一个题的题解,里面有证明: 传送门
现在我们找到了树的直径的两个端点,然后 分别求一下树上的每个点距离这两个端点的距离,还是\(dfs\)。
这里看起来需要两次\(dfs\),其实只需要在进行一次即可,因为我们在上面的第二次\(dfs\)里面,就可以顺带求出每个点距离第一个端点的距离。所以这里我们只需要\(dfs\)第二个端点就可以了。
最后一次\(dfs\),我们枚举一下树上的点,为什么要枚举树上的点呢?不是枚举树的直径上的点就够了吗?
当然是这样,但是要做到只枚举树的直径上的点其实有点难做到,而且枚举树上的所有点复杂度也只是\(O(n)\)而已,所以大可不必去优化它。
那么最后一次\(dfs\)的时候,我们就 更新一下最小的最大长度 就可以了,具体更新方程就是 \(len=min(len,max(d1[u],d2[u]))\),其实也有点像\(dp\),哈哈。
\(d1[u]\) 和 \(d2[u]\) 分别表示当前点分别距离两个端点的距离。上面那个转移方程可以只针对在树的直径上的点去理解,会更好理解一些。(因为如果一个点不在树的直径上,那么这个值会更大,不用考虑它)
好了,下面就是四次\(dfs\)的代码了,时间复杂度 \(O(n)\),跑完大概\(35ms\)。(鄙人比较喜欢偷懒,所以代码比较丑)
【黄海注:使用\(fa\)参数和使用全局\(st\)数组,都是为了不走回头路,效果是一样的,但\(fa\)参数法多次调用不用清空,不用多余空间,推荐。】
带\(ST\)数组版本 【推荐】
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int INF = 0x3f3f3f3f;
const int N = 1e4 + 10, M = N << 1;
int n, m;
int t1, t2, ans;
int res = INF;
int d1[N], d2[N];
// 链式前向星
int e[M], h[N], idx, w[M], ne[M], st[N];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
// 第一次dfs求直径的第一个端点
void dfs1(int u, int sum) {
st[u] = 1;
if (sum > ans) {
ans = sum;
t1 = u;
}
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (!st[j]) dfs1(j, sum + w[i]);
}
}
void dfs2(int u, int sum) { // 第二次dfs求树的直径的第二个端点+d1[u]
st[u] = 1;
if (sum > ans) {
ans = sum;
t2 = u;
}
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (!st[j]) {
d1[j] = sum + w[i]; // 这是啥?
dfs2(j, sum + w[i]);
}
}
}
void dfs3(int u, int sum) { // 第三次dfs求d2[u]
st[u] = 1;
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (!st[j]) {
d2[j] = sum + w[i];
dfs3(j, sum + w[i]);
}
}
}
void dfs4(int u) { // 第四dfs求 res=min(res,max(d1[u]+d2[u]))
st[u] = 1;
res = min(res, max(d1[u], d2[u]));
for (int i = h[u]; ~i; i = ne[i]) {
int j = e[i];
if (!st[j]) dfs4(j);
}
}
int main() {
cin >> n;
// 初始化链式前向星
memset(h, -1, sizeof h);
for (int i = 1; i < n; i++) { // n-1条边
int a, b, c;
cin >> a >> b >> c;
add(a, b, c), add(b, a, c); // 无向图
}
// ① 任选一点,找出此点能够到达的最远点t1,t1就是树的直径中的一个端点
ans = 0;
memset(st, 0, sizeof st);
dfs1(1, 0);
// ② 从 t1出发,找出此点能够到达的最远点t2,t2就是树的直径中的另一个端点
ans = 0;
memset(st, 0, sizeof st);
dfs2(t1, 0);
// ③ 计算树上每个点到上面树的直径两个端点的距离
memset(st, 0, sizeof st);
dfs3(t2, 0);
// ④ 更新一下最小的最大长度
memset(st, 0, sizeof st);
dfs4(1);
// 输出结果
printf("%d\n", res);
return 0;
}